

В начале сентября Яндекс провел закрытую мини-конференцию по генеративному ИИ, предоставив площадку для глубокого погружения в мир ИИ. Тем не менее, конференция принесла важные откровения, особенно касающиеся долгожданного YandexGPT 2.
Представление YandexGPT 2 вызвало у сообщества ИИ бурное ожидание. Создатели этой модели исследовали различные отличительные особенности, включая специализированный модуль, предназначенный для поиска и предоставления ответов на основе данных результатов поиска. Примечательно, что откровения команды раскрыли поразительный аспект: даже при обучении на обширном хранилище внутренних данных Yandex, охватывающем более чем десятилетие работы над нейронными поисковыми механизмами, эта фирменная модель все еще не дотягивала до грозного GPT-4. Это значительное развитие подчеркивает замечательные успехи, достигнутые GPT-4. Это наблюдение подчеркивает превосходство GPT-4 как над фирменными разработками, так и над предыдущими итерациями с открытым исходным кодом.
Расширяя такие фундаментальные идеи, Google провел исследование для оценки точности ответов от больших языковых моделей (LLM), наделенных доступом к поисковой системе. Хотя идея интеграции внешнего инструмента с LLM не нова, Google обнаружил, что сложность заключается в тонкой оценке и проверке этих моделей. Решающие факторы, формирующие эту интеграцию, охватывают выбор тщательно продуманного запроса и внутренние возможности LLM.
Методология тестирования LLM от Google
Собранный корпус из 600 вопросов был разделен на четыре отдельные группы. Каждая группа отдавала приоритет фактической точности, но одна группа выделялась включением вопросов, основанных на ложных предпосылках. Например, такие вопросы, как «что написал Трамп после того, как его разбанили в Twitter?», содержали неточную предпосылку, поскольку Трамп не был разбанен. Остальные три группы ввели переменные устаревания ответов: никогда, редко и часто. В группе «никогда» от LLM ожидалось, что они будут отвечать исключительно по памяти, тогда как вопросы о недавних событиях требовали поиска в реальном времени. Каждая группа состояла из 125 вопросов.
Вопросы были заданы самым разным моделям. Интересно, что вопросы, содержащие ложные предпосылки, выявили доминирование GPT-4 и ChatGPT, которые умело опровергали такие предпосылки, что указывает на их особую подготовку для решения таких задач.
Последовал сравнительный анализ, в котором ChatGPT, GPT-4, поиск Google (на основе текстовых фрагментов или ответов на первой странице) и PPLX.AI (платформа, использующая ChatGPT для агрегации ответов Google, нацеленная на разработчиков) сталкивались друг с другом. В этом контексте LLM давали ответы исключительно по памяти.
Примечательно, что поиск Google в среднем давал правильные ответы в 40% случаев по всем четырем группам. Точность для «вечных» вопросов составила 70%, а для вопросов с ложными предпосылками — всего 11%. Производительность ChatGPT в среднем составила 26%, а GPT-4 достигла 28%, впечатляюще отвечая на вопросы с ложными предпосылками в 42% случаев. PPLX.AI продемонстрировал показатель успешности 52%.
Исследование углублялось за счет интеграции нового подхода. Каждый вопрос вызывал поиск в Google, а результаты включались в подсказку. Затем LLM должны были «прочитать» эту информацию, прежде чем составлять свои ответы. Эта техника позволяла проводить обучение Few-Shot (где примеры представлены в подсказке для руководства моделью) и вдумчивое пошаговое рассмотрение перед ответом.
Результаты оказались просто захватывающими. GPT-4 показал замечательный рейтинг качества 77%, отвечая на «вечные» вопросы с точностью 96% и решая вопросы с ложными предпосылками с похвальной точностью 75%. Хотя ChatGPT показал немного менее впечатляющие показатели, он превзошел и PPLX.AI, и поиск Google.
Освоение дизайна подсказок ИИ: ключевые идеи от экспертов PPLX.AI и Google
Способность эффективно направлять большие языковые модели (LLM) через лабиринт информации — немалый подвиг. Однако недавнее исследование подсказок ИИ выявило ключевые стратегии, которые обещают повысить качество ответов, генерируемых LLM, предлагая заглянуть в тонкую механику помощи ИИ.
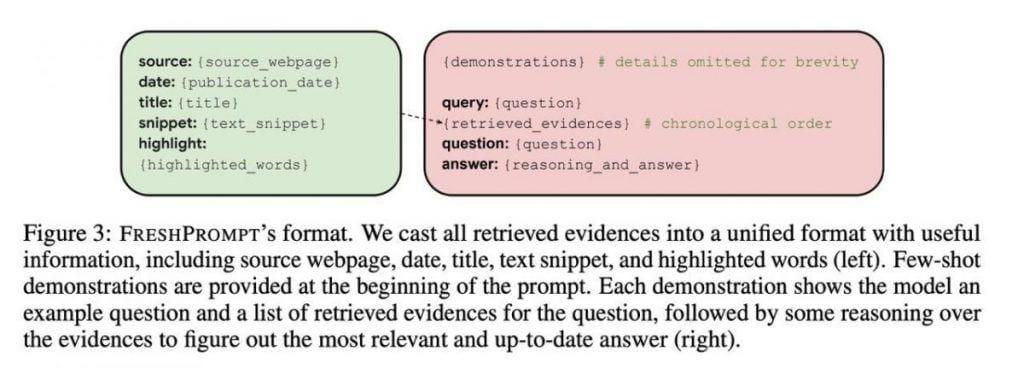
Основа для этого откровения была заложена посредством тщательного структурирования подсказок. Этот метод состоит из нескольких компонентов, предлагающих четкий путь к получению точных ответов, прочно основанных на контекстном понимании. Начальный аспект включает иллюстративные примеры, служащие направляющими маркерами, направляющими LLM к правильному ответу на основе контекстных подсказок.
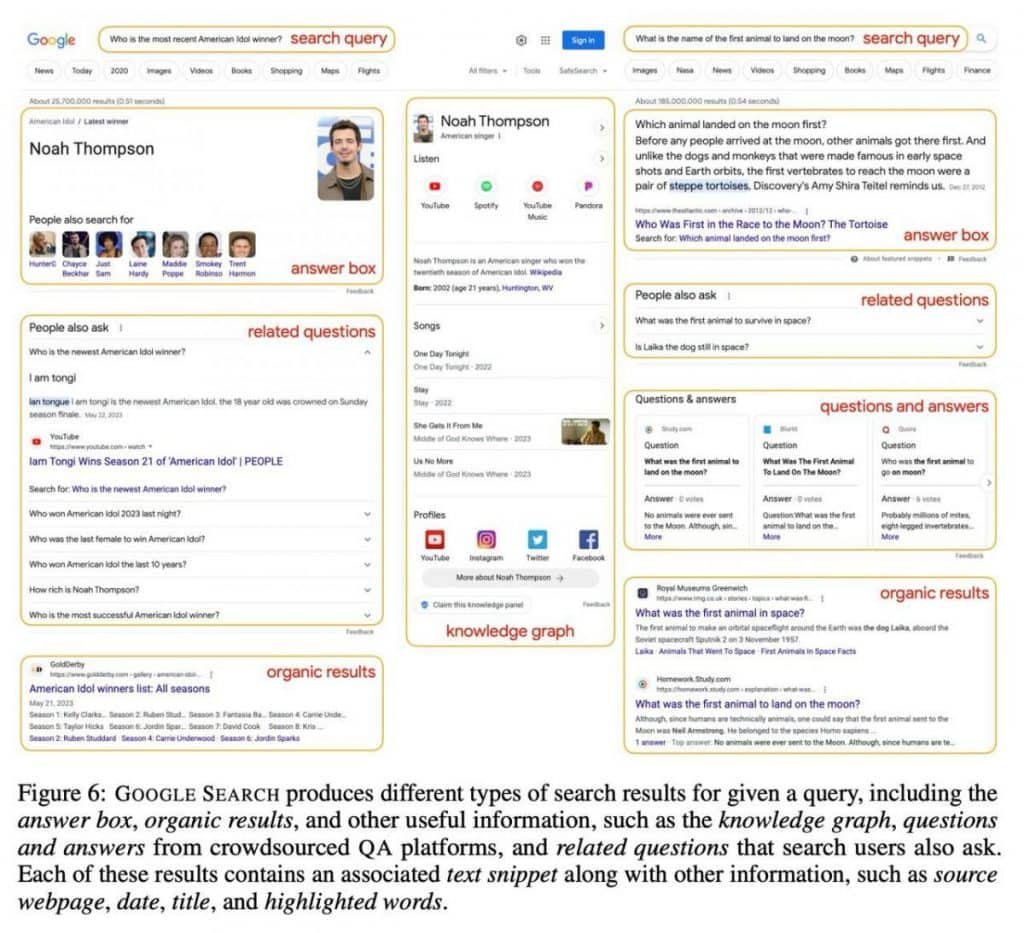
второй слой показывает фактический запрос вместе с 10-15 результатами поиска. Эти результаты выходят за рамки простых ссылок на веб-страницы, охватывая массу информации, включая текстовый контент, релевантные запросы, вопросы, ответы и графики знаний. Такой подход снабжает ИИ всеобъемлющей библиотекой знаний.
Сложность этой системы идет дальше. Решающее открытие возникло при хронологическом расположении ссылок в подсказке, когда самые последние дополнения были помещены в конец. Это хронологическое расположение отражает эволюционную природу информации, позволяя модели различать временную шкалу изменений. Включение дат в каждый пример сыграло решающую роль в улучшении контекстного понимания.
Хотя код, реализующий эту детальную структуру подсказок, с нетерпением ожидается, его отсутствие побудило энтузиастов рискнуть и переписать шаблоны подсказок на основе предоставленных изображений.
Из этого исследования механики подсказок ИИ можно сделать несколько ключевых выводов:
1) PPLX.AI, платформа, которая использует ChatGPT для агрегации ответов Google, появилась как многообещающий вариант. Даже сотрудники Google намекнули на ее превосходство.
2) Эксперименты с различными элементами дали улучшения в показателях отклика. Точность в построении подсказок, похоже, сама по себе является искусством.
3) GPT-4 демонстрирует похвальную сноровку в обработке обширных наборов новостей и текстов. Хотя его нельзя охарактеризовать как «отличное», его качество даже в быстро меняющихся новостных сценариях колеблется около отметки 60%. Сообществу ИИ рекомендуется критически оценивать такие метрики.
4) Поскольку экосистема ИИ продолжает расширяться, LLM, интегрированные в поисковые системы, готовы стать повсеместными, обслуживая широкий спектр пользователей. Присутствие ИИ в повседневном поиске находится на восходящей траектории, что означает преобразующий сдвиг в способе доступа к информации и ее обработки.
Многогранный подход предлагает многообещающий способ получения точных ответов из этих сложных языковых моделей, поскольку он включает в себя иллюстративные примеры, четко определенный запрос и множество контекстной информации. Хронологическое расположение ссылок в подсказках привело к значительному пониманию, подчеркивая важность адаптации к динамической природе информации. LLM могут ориентироваться во временной шкале изменений благодаря этой временной осведомленности, которая улучшает их контекстное понимание.
Публикация «Анализ Google раскрывает удивительные факты о LLM и точности поисковых систем» впервые появилась на Metaverse Post.