

Principalele produse la pachet
Binance folosește managementul capacității pentru creșterile neplanificate ale traficului cauzate de volatilitatea ridicată, asigurând o infrastructură adecvată și la timp și resurse de calcul pentru cerințele afacerii.
Teste de încărcare Binance în mediul de producție (mai degrabă decât într-un mediu de staging) pentru a obține benchmark-uri exacte ale serviciilor. Această metodă ajută la validarea faptului că alocarea noastră de resurse este adecvată pentru a servi o sarcină definită.
Infrastructura Binance se ocupă de cantități mari de trafic, iar menținerea unui serviciu de care se pot baza utilizatorii necesită o gestionare adecvată a capacității și testarea automată a sarcinii.

De ce are Binance nevoie de un proces specializat de gestionare a capacității?
Managementul capacității este o bază a stabilității sistemului. Presupune dimensionarea corectă a aplicațiilor și a resurselor de infrastructură cu cerințele actuale și viitoare ale afacerii la costul corect. Pentru a ajuta la atingerea acestui obiectiv, construim instrumente și conducte de gestionare a capacității pentru a evita supraîncărcarea și pentru a ajuta companiile să ofere o experiență de utilizator fluidă.
Piețele de criptomonede se confruntă adesea cu perioade mai regulate de volatilitate decât piețele financiare tradiționale. Aceasta înseamnă că sistemul Binance trebuie să reziste la această creștere a traficului din când în când, pe măsură ce utilizatorii reacționează la mișcările pieței. Cu un management adecvat al capacității, menținem capacitatea adecvată pentru cererea generală de afaceri și pentru aceste scenarii de creștere a traficului. Acest punct cheie este exact ceea ce face ca procesele de gestionare a capacității Binance să fie unice și provocatoare.
Să ne uităm la factorii care împiedică adesea procesul și conduc la un serviciu lent sau indisponibil. În primul rând, avem suprasolicitare, de obicei cauzată de o creștere bruscă a traficului. De exemplu, acest lucru ar putea rezulta dintr-un eveniment de marketing, o notificare push sau chiar un atac DDoS (Distributed Denial of Service).
Traficul crescut și capacitatea insuficientă afectează funcționalitatea sistemului ca:
Serviciul preia din ce în ce mai multă muncă.
Timpul de răspuns crește până la punctul în care nicio solicitare nu poate fi răspunsă în timpul expirării clientului. Această degradare se întâmplă de obicei din cauza saturației resurselor (CPU, memorie, IO, rețea etc.) sau a pauzelor GC prelungite în serviciul în sine sau dependențele acestuia.
Rezultatul este că serviciul nu va putea procesa cererile prompt.
Defalcarea procesului
Acum că am discutat despre principiul general al managementului capacității, să ne uităm la modul în care Binance aplică acest lucru afacerii sale. Iată o privire asupra arhitecturii sistemului nostru de management al capacității cu câteva fluxuri de lucru cheie.
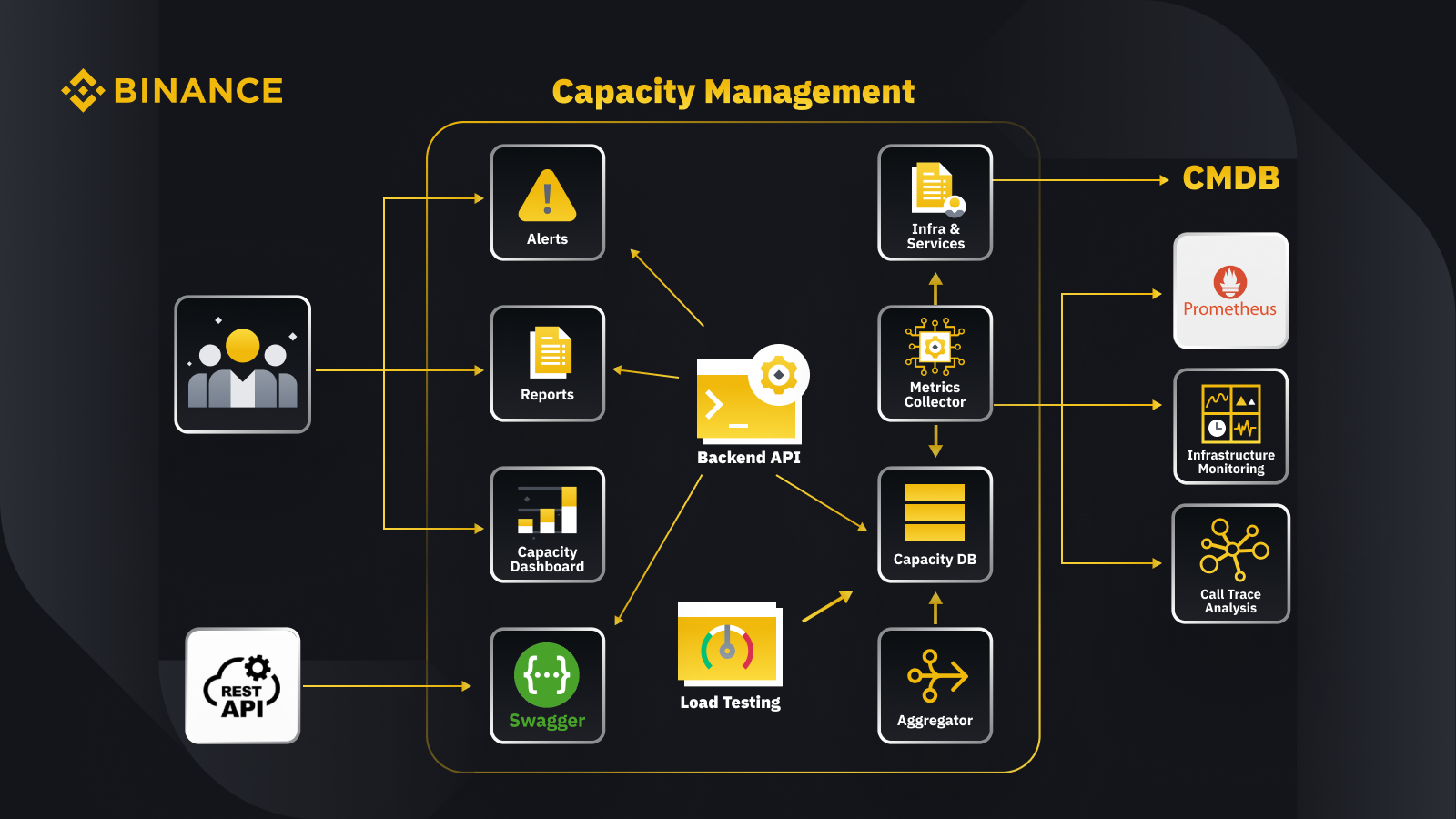
Prin preluarea datelor din baza de date de management al configurației (CMDB), generăm configurațiile infra și servicii. Elementele din aceste configurații sunt obiectele de gestionare a capacității.
Colectorul de valori preia valorile de capacitate de la Prometheus pentru datele de nivel de afaceri și de servicii, Monitorizarea infrastructurii pentru valorile stratului de resurse și sistemul de analiză a urmăririi apelurilor pentru informațiile de urmărire. Colectorul de metrici stochează datele în baza de date de capacitate (CDB).
Sistemul de testare a sarcinii efectuează teste de stres asupra serviciilor și stochează datele de referință în CDB.
Agregatorul primește datele de capacitate de la CDB și le agregează pentru dimensiuni zilnice și maxime (ATH). După agregare, scrie datele agregate înapoi în CDB.
Prin procesarea datelor din CDB, API-ul backend oferă interfețe pentru tabloul de bord de capacitate, alerte și rapoarte, precum și restul API-ului și datele de capacitate aferente pentru integrare.
Părțile interesate obțin informații despre capacitate prin intermediul tabloului de bord al capacității, alertelor și rapoartelor. Ei pot folosi, de asemenea, alte sisteme conexe, inclusiv monitorizarea datelor de capacitate a serviciilor cu restul API furnizate de sistemul de management al capacității cu Swagger.
Strategie
Strategia noastră de gestionare și planificare a capacității se bazează pe procesarea de vârf. Procesarea bazată pe vârf este volumul de lucru experimentat de resursele unui serviciu (servere web, baze de date etc.) în timpul utilizării de vârf.
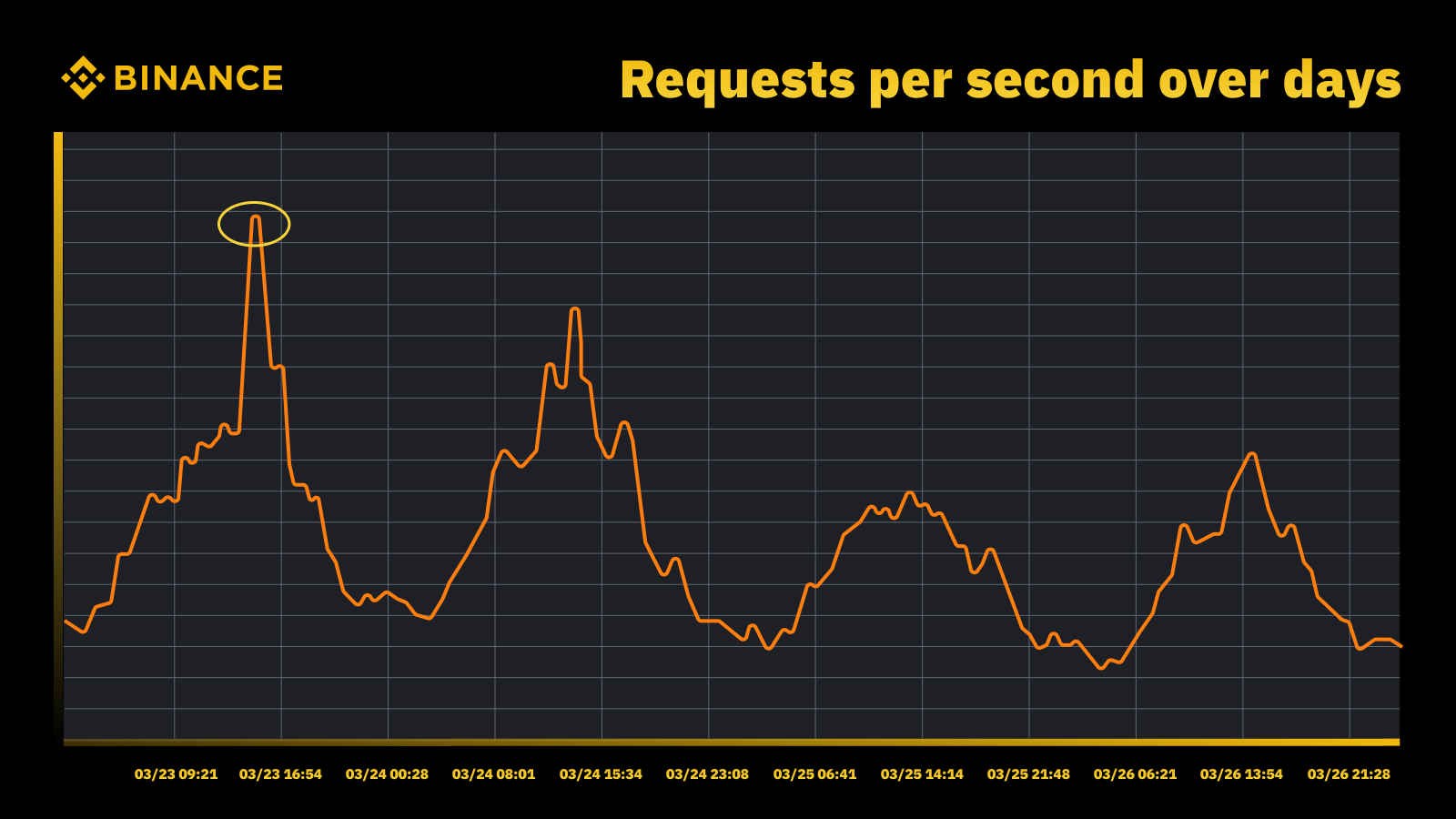
Traficul a crescut atunci când Fed a crescut rata în martie 2023
Analizăm vârfurile periodice și le folosim pentru a conduce traiectoria capacității. Ca și în cazul oricărei resurse bazate pe vârfuri, vrem să aflăm când apar vârfurile și apoi să explorăm ce se întâmplă de fapt în timpul acelor cicluri.
Un alt lucru important pe care îl luăm în considerare împreună cu prevenirea supraîncărcării este scalarea automată. Autoscaling tratează supraîncărcarea prin creșterea dinamică a capacității cu mai multe instanțe ale serviciului. Traficul în exces este apoi distribuit, iar traficul pe care îl gestionează o singură instanță a serviciului (sau dependenței) rămâne gestionabil.
Autoscaling-ul își are locul, dar nu face față doar situațiilor de suprasarcină. De obicei, nu poate reacționa suficient de rapid la o creștere bruscă a traficului și funcționează cel mai bine doar atunci când există o creștere treptată.
Măsurare
Măsurarea joacă un rol crucial în activitatea de gestionare a capacității a Binance, iar colectarea datelor este primul nostru pas de măsurare. Pe baza standardelor Bibliotecii de infrastructură a tehnologiei informației (ITIL), colectăm date pentru măsurare în subprocesele de management al capacității și anume:
Resurse - consumul de resurse pentru infrastructura IT determinat de utilizarea aplicației/serviciului. Se concentrează pe valorile interne de performanță ale resurselor de calcul fizice și virtuale, inclusiv CPU server, memorie, stocare pe disc, lățime de bandă de rețea etc.
Serviciu. Măsurile de performanță la nivel de aplicație, SLA, latență și debit care decurg din activitățile de afaceri. Se concentrează pe valorile de performanță externe bazate pe modul în care utilizatorii percep serviciul, inclusiv latența serviciului, debitul, vârfurile etc.
Afaceri. Colectează date care măsoară activitățile de afaceri procesate de aplicația țintă, inclusiv comenzi, înregistrarea utilizatorilor, plăți etc.
Gestionarea capacității bazată doar pe utilizarea resurselor de infrastructură va duce la o planificare incorectă. Acest lucru se datorează faptului că s-ar putea să nu reprezinte volumele reale de afaceri și debitul care determină capacitatea infrastructurii noastre.
Evenimentele programate oferă un loc excelent pentru a discuta acest lucru în continuare. Participați la Watch Web Summit 2022 pe Binance Live pentru a împărți până la 15.000 BUSD în campania Crypto Box Rewards. Pe lângă valorile de bază ale resurselor și ale stratului de servicii, trebuia să luăm în considerare și volumele de afaceri. Ne-am bazat aici planificarea capacității pe valori de afaceri, cum ar fi numărul estimat de spectatori ai fluxurilor live, solicitările maxime în timpul zborului pentru o cutie Crypto, latența de la un capăt la altul și alți factori.
După colectarea datelor, procesele noastre de gestionare a capacității agregează și rezumă numeroasele puncte de date colectate în raport cu un anumit factor de capacitate. Valoarea agregată a unei valori este o singură valoare care poate fi utilizată în alertarea capacității, raportarea și alte funcții legate de capacitate.
Putem aplica mai multe metode de agregare a datelor la punctele de date periodice, cum ar fi sumă, medie, mediană, minimă, maximă, percentilă și maxim total (ATH).

Metoda aleasă de noi determină rezultatele noastre din procesul de management al capacității și deciziile rezultate. Selectăm diferite metode pe baza diferitelor scenarii. De exemplu, folosim metoda maximă pentru serviciile critice și punctele de date aferente. Pentru a înregistra cel mai mare trafic, folosim metoda ATH.
Pentru diferite cazuri de utilizare, folosim diferite tipuri de granularitate pentru agregarea datelor. În cele mai multe cazuri, folosim fie minute, oră, zi sau ATH.
Cu o granularitate minimă, măsurăm volumul de lucru al unui serviciu pentru alerte de suprasarcină în timp util.
Folosim date orare agregate pentru a acumula date zilnice și cumulăm datele orare pentru a înregistra vârful zilnic.
De obicei, folosim datele zilnice pentru rapoartele de capacitate și folosim datele ATH pentru modelarea și planificarea capacității.
Una dintre valorile de bază ale managementului capacității este evaluarea comparativă a serviciilor. Acest lucru ne ajută să măsurăm cu precizie performanța și capacitatea serviciului. Obținem benchmark-ul serviciului cu testarea sarcinii și vom aborda acest lucru mai în detaliu mai târziu.
Managementul capacității pe baza priorităților
Până acum, am văzut cum colectăm valorile de capacitate și cum adunăm date în diferite tipuri de granularitate. Un alt domeniu critic de discutat este prioritatea, care este utilă în contextul rapoartelor de alertă și capacitate. După clasarea activelor IT, utilizarea limitată a infrastructurii și resursele de calcul sunt prioritizate și acordate mai întâi serviciilor și activităților critice.
Pot exista o serie de moduri de a defini serviciul și de a solicita criticitatea. O referință utilă este Google. În cartea SRE. Ele definesc nivelurile de criticitate ca CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS etc. În mod similar, definim mai multe niveluri de prioritate, cum ar fi P0, P1, P2 și așa mai departe.
Definim nivelurile de prioritate astfel:
P0: Pentru cele mai critice servicii și solicitări, cele care vor avea ca rezultat un impact grav, vizibil de utilizator, dacă eșuează.
P1: Pentru acele servicii și solicitări care vor avea ca rezultat un impact vizibil de utilizator, dar impactul este mai mic decât cele ale P0. Se așteaptă ca serviciile P0 și P1 să fie furnizate cu o capacitate suficientă.
P2: Aceasta este prioritatea implicită pentru joburile lot și joburile offline. Este posibil ca aceste servicii și solicitări să nu aibă un impact vizibil de utilizator dacă sunt parțial indisponibile.
Ce este testarea de încărcare și de ce o folosim într-un mediu de producție?
Testarea de încărcare este un proces nefuncțional de testare a software-ului în care performanța unei aplicații este testată sub o anumită sarcină de lucru. Acest lucru ajută la determinarea modului în care se comportă aplicația în timp ce este accesată de mai mulți utilizatori finali simultan.
La Binance, am creat o soluție care ne permite să rulăm testarea încărcării în producție. De obicei, testarea încărcării se desfășoară într-un mediu de procesare, dar nu am putut folosi această opțiune pe baza obiectivelor noastre generale de gestionare a capacității. Testarea de încărcare într-un mediu de producție ne-a permis să:
Colectați un benchmark precis al serviciilor noastre în condiții de încărcare reale.
Creșteți încrederea în sistem, fiabilitatea și performanța acestuia.
Identificați blocajele din sistem înainte ca acestea să apară în mediul de producție.
Permite monitorizarea continuă a mediilor de producție.
Activați gestionarea proactivă a capacității cu cicluri de testare normalizate care au loc în mod regulat.
Mai jos puteți vedea cadrul nostru de testare a sarcinii cu câteva concluzii cheie:

Cadrul de microservicii Binance are un strat de bază pentru a sprijini rutarea traficului bazată pe configurație și pe semnalizare, ceea ce este esențial pentru abordarea noastră TIP.
Analiza automată canar (ACA) este adoptată pentru a evalua instanța pe care o testăm. Acesta compară valorile cheie colectate în sistemul de monitorizare, astfel încât să putem întrerupe/încheia testul dacă se întâmplă vreo problemă neașteptată pentru a minimiza impactul utilizatorului.
Benchmark-urile și valorile sunt colectate în timpul testării de încărcare pentru a genera informații despre date privind comportamentele și performanța aplicației.
API-urile sunt expuse să partajeze date valoroase de performanță în diferite scenarii, de exemplu, managementul capacității și asigurarea calității. Acest lucru ajută la construirea unui ecosistem deschis.
Creăm fluxuri de lucru de automatizare pentru a orchestra toți pașii și punctele de control dintr-o perspectivă de testare end-to-end. De asemenea, oferim flexibilitatea integrării cu alte sisteme, cum ar fi conducta CI/CD și portalul de operare.
Abordarea noastră de testare în producție (TIP).
O abordare tradițională de testare a performanței (executarea de teste într-un mediu de pregătire cu trafic simulat sau oglindit) oferă unele beneficii. Cu toate acestea, implementarea unui mediu de organizare asemănător producției are mai multe dezavantaje în contextul nostru:
Aproape dublează costul infrastructurii și eforturile de întreținere.
Este incredibil de complex să lucrezi end-to-end în producție, în special într-un mediu de microservicii la scară largă în mai multe unități de afaceri.
Adaugă mai multe riscuri de confidențialitate și securitate a datelor, deoarece, în mod inevitabil, este posibil să fie nevoie să duplicăm datele în punere în scenă.
Traficul simulat nu va replica niciodată ceea ce se întâmplă de fapt în producție. Benchmark-ul obținut în mediul de punere în scenă ar fi inexact și are o valoare mai mică
Testarea în producție, cunoscută și sub numele de TIP, este o metodologie de testare cu schimbare la dreapta în care codul, funcțiile și versiunile noi sunt testate în mediul de producție. Testarea de sarcină în producție pe care am adoptat-o este extrem de benefică, deoarece ne ajută:
Analizați stabilitatea și robustețea sistemului.
Descoperiți punctele de referință și blocajele aplicațiilor la diferite niveluri de trafic, specificații de server și parametri ai aplicației.
Rutare bazată pe FlowFlag
Rutarea noastră bazată pe FlowFlag încorporată în cadrul de bază pentru microservicii este fundația pentru a face posibilă TIP. Acest lucru este valabil pentru cazuri specifice, inclusiv pentru aplicațiile care utilizează Eureka service discovery pentru distribuirea traficului.
După cum este ilustrat în diagramă, serverul web Binance ca puncte de intrare etichetează o parte din trafic, așa cum este specificat în configurațiile cu antetele FlowFlag, în timpul testului de încărcare, putem selecta o gazdă a unui anumit serviciu și o putem marca ca instanță de performanță țintă în configs, atunci acele cereri etichetate perf vor fi în cele din urmă direcționate către instanța perf când ajung la serviciu pentru procesare.
Este pe deplin bazat pe configurație și încărcare la cald, putem ajusta cu ușurință procentul de sarcină de lucru folosind automatizare, fără a fi nevoie să implementăm o nouă ediție
Poate fi aplicat pe scară largă la majoritatea serviciilor noastre, deoarece mecanismul face parte din pachetul de bază și gateway
Un singur punct de schimbare înseamnă, de asemenea, o retragere ușoară pentru a reduce riscurile în producție

În timp ce ne transformăm soluția pentru a fi mai nativă în cloud, explorăm și modul în care putem construi o abordare similară pentru a sprijini alte rutări de trafic oferite de furnizorii de cloud public sau Kubernetes.
Analiză automată canar pentru a minimiza riscurile de impact asupra utilizatorului
Implementarea Canary este o strategie de implementare pentru a reduce riscul implementării unei noi versiuni de software în producție. De obicei, implică implementarea unei noi versiuni a software-ului, numită lansare Canary, la un subset mic de utilizatori, alături de versiunea de rulare stabilă. Apoi împărțim traficul între cele două versiuni, astfel încât o parte din solicitările primite să fie redirecționată către canar.
Calitatea versiunii canare este apoi evaluată prin așa-numita analiză canar. Aceasta compară valorile cheie care descriu comportamentul versiunilor vechi și noi. Dacă există o degradare semnificativă a valorilor, canary este anulat și tot traficul este direcționat către versiunea stabilă pentru a minimiza impactul comportamentului neașteptat.
Folosim același concept pentru a construi soluția noastră automată de testare a sarcinii. Soluția folosește platforma Kayenta pentru analiza automată a canarelor (ACA) prin Spinnaker pentru a permite implementări automate de canare. Fluxul nostru tipic de testare a sarcinii atunci când urmează această metodă arată așa:
Prin fluxul de lucru, adăugăm treptat încărcătura de trafic (de exemplu, 5%, 10%, 25%, 50%) la gazda țintă, așa cum este specificat sau până când aceasta atinge punctul de întrerupere.
Sub fiecare încărcare, analiza Canary este efectuată în mod repetat cu Kayenta pentru o anumită perioadă de timp (de exemplu, 5 minute) pentru a compara valorile cheie ale gazdei testate cu perioada de preîncărcare ca linie de bază și perioada actuală de post-încărcare ca experiment.
Comparația (modelul Canary Config) se concentrează pe verificarea dacă gazda țintă:
Atinge constrângerile de resurse, de exemplu, utilizarea procesorului depășește 90%.
Are o creștere semnificativă a valorilor de eșec, de exemplu, jurnalele de erori, excepții HTTP sau respingeri ale limitelor de rată.
Are valorile de bază ale aplicației sunt încă rezonabile, de exemplu, o latență HTTP mai mică de 2 secunde (personalizată pentru fiecare serviciu)
Pentru fiecare analiză, Kayenta ne oferă un raport pentru a indica rezultatul, iar testul se încheie imediat după eșec.
Această detectare a eșecului durează de obicei mai puțin de 30 de secunde, reducând semnificativ șansa de a afecta experiența utilizatorilor finali.

Activarea Datelor Insights
Este esențial să colectați suficiente informații despre toate procesele și execuțiile de testare descrise anterior. Scopul final este de a îmbunătăți fiabilitatea și robustețea sistemului nostru, ceea ce este imposibil fără informații despre date.
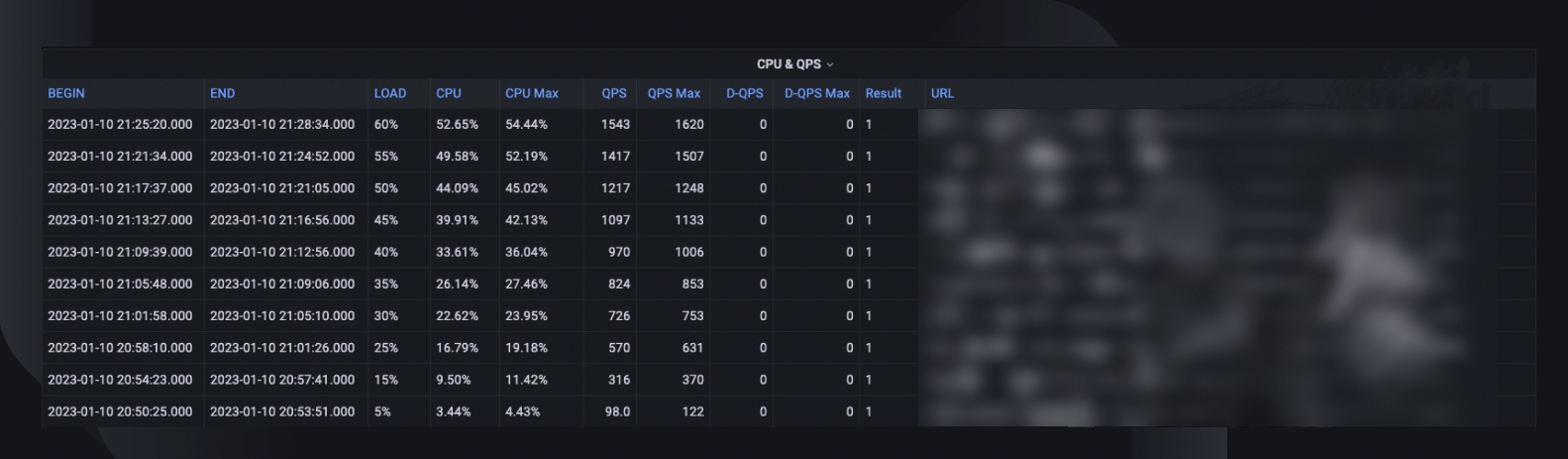
Un rezumat general al testului surprinde procentul de încărcare maximă pe care gazda a fost capabilă să o suporte, utilizarea maximă a procesorului și QPS-ul gazdei. Pe baza acestui fapt, estimează, de asemenea, numărul de instanțe pe care ar putea fi necesar să le implementăm pentru a ne îndeplini rezervarea de capacitate, ținând cont de QPS-ul de-a lungul timpului al serviciilor.
Alte informații valoroase pentru analiză includ versiunea software, specificațiile serverului, numărul implementat și un link către tabloul de bord al monitorului, unde putem privi înapoi la ceea ce s-a întâmplat în timpul testului.

O curbă de referință indică modul în care s-a schimbat performanța în ultimele trei luni, astfel încât să putem descoperi eventualele probleme legate de o anumită versiune a aplicației.

Tendințele CPU și QPS arată modul în care utilizarea procesorului s-a corelat cu volumul de solicitări pe care serverul a trebuit să îl gestioneze. Această măsurătoare poate ajuta la estimarea spațiului serverului pentru creșterea traficului de intrare.
Comportamentul latenței API surprinde modul în care timpul de răspuns variază în diferite condiții de încărcare pentru primele cinci API-uri. Putem apoi optimiza sistemul, dacă este necesar, la un nivel individual de API.

Valorile de distribuție a încărcăturii API ne ajută să înțelegem modul în care compoziția API-ului afectează performanța serviciului și oferă mai multe informații despre domeniile de îmbunătățire.
Normalizare și producție
Pe măsură ce sistemul nostru continuă să crească și să evolueze, vom continua să urmărim și să îmbunătățim stabilitatea și fiabilitatea serviciului. Vom continua asta prin:
Un program regulat și stabilit de testare a sarcinii pentru serviciile critice.
Testarea automată a sarcinii ca parte a conductelor noastre CI/CD.
Producție crescută a întregii soluții pentru a se pregăti pentru adoptarea pe scară largă în întreaga organizație.
Limitări
Există câteva limitări ale abordării actuale a testului de sarcină:
Rutarea bazată pe FlowFlag este aplicabilă numai cadrului nostru de microservicii. Căutăm să extindem soluția la mai multe scenarii de rutare, utilizând caracteristica comună de rutare ponderată a echilibratorilor de încărcare în cloud sau a unui Kubernetes Ingress.
Deoarece ne bazăm testul pe traficul real al utilizatorilor în producție, nu putem efectua teste de caracteristici pentru anumite API-uri sau cazuri de utilizare. De asemenea, pentru serviciile cu volum foarte scăzut, valoarea ar fi limitată, deoarece este posibil să nu putem identifica blocajul acestuia.
Efectuăm aceste teste pe servicii individuale, mai degrabă decât să acoperim lanțurile de apeluri end-to-end.
Testarea în producție poate afecta uneori utilizatorii reali dacă apar erori. Prin urmare, trebuie să avem analiză a erorilor și auto-rollback cu capabilități complete de automatizare.
Gânduri de închidere
Este esențial pentru noi să ne gândim la scenarii de trafic intens pentru a preveni supraîncărcarea sistemului și pentru a asigura timpul de funcționare al acestora. De aceea, am construit procesele de management al capacității și de testare a sarcinii descrise în acest articol. A rezuma:
Managementul capacității noastre este determinat de vârf și încorporat în fiecare etapă a ciclului de viață al serviciului, prevenind supraîncărcarea cu activități precum măsurarea, configurarea priorităților, alerte și rapoarte de capacitate etc. În cele din urmă, acesta este ceea ce face ca procesele și nevoile Binance să fie unice în comparație cu o situație tipică de gestionare a capacității. .
Valoarea de referință a serviciilor obținută din testarea sarcinii este punctul focal al managementului și planificării capacității. Determină cu precizie resursele de infrastructură necesare pentru a susține cerințele actuale și viitoare ale afacerii. Acest lucru a trebuit în cele din urmă să fie realizat în producție cu o soluție unică, construită de Binance, care ne-a permis să ne îndeplinim nevoile specifice.
Cu toate acestea reunite, sperăm că puteți vedea că o bună planificare și cadrele amănunțite ajută la crearea serviciului pe care binancianii îl cunosc și se bucură.
Referințe
Dominic Ogbonna, de la A-Z al managementului capacității: Ghid practic pentru implementarea monitorizării și planificării capacității pentru întreprinderi IT, capitolul 4, capitolul 6
Luis Quesada Torres, Doug Colish, SRE Cele mai bune practici pentru managementul capacității
Alejandro Forero Cuervo, Sarah Chavis, cartea Google SRE, capitolul 21 - Gestionarea supraîncărcării
Lectură suplimentară
(Blog) Cum Binance Ledger vă ajută experiența Binance
(Blog) Vă prezentăm Binance Oracle VRF: următoarea generație a aleatoriei verificabile
(Blog) Binance se alătură Alianței FIDO în pregătirea pentru implementarea Passkey