
昨天半夜刷 X,看那些 AI 视频的时候,我突然有个感觉:
以后最贵的东西,可能不是算力,也不是模型,而是可信度。
现在网上的信息环境大家都懂。
搬运、洗稿、AI 批量生成,真假掺着一起飞。很多内容看起来头头是道,但你根本不知道来源是谁,更不知道背后有没有被篡改。
在 Web2 时代这问题不算致命,毕竟大部分人只是刷刷内容。
但 AI 时代不一样。
当 AI 开始帮你做决策、管资金、执行任务的时候,如果连数据来源都搞不清楚,那风险其实比很多人想象得大得多。
这也是我关注 @OpenLedger 的原因。
很多项目都在卷模型、卷参数、卷算力,但 OpenLedger 更像是在解决另一个问题:
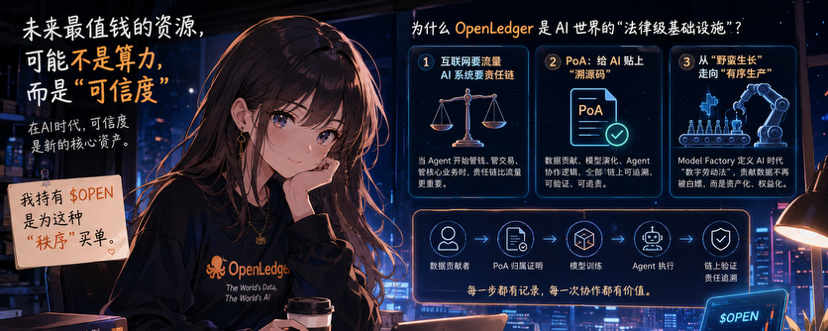
怎么证明 AI 的结论是可信的。
很多人把 PoA(Proof of Attribution)理解成版权工具,我觉得有点低估它了。
在我看来,它更像一套责任追踪系统。
数据从哪里来,谁贡献的,模型怎么训练出来的,中间经过哪些环节,都有迹可循。
就像买菜能查产地一样,未来 AI 给出的结果,也应该能查到源头。
尤其是金融、医疗这些高风险场景,没有溯源能力,再聪明的 AI 也很难让人真正放心。

我最近研究他们的 Model Factory 也是同样的感受。
它做的并不只是训练模型,而是在尝试建立一套更公平的价值分配机制。
过去贡献数据的人往往拿不到回报,价值都集中在平台手里。
而现在,数据、模型、推理过程都能被记录和量化,贡献者也有机会获得对应收益。
这背后最大的变化其实是:
AI 行业正在从野蛮生长,慢慢走向规则化运行。
以前互联网讲究流量第一。
以后 AI 可能更看重责任、归属和验证。
所以我买 $OPEN 并不是因为我觉得它明天一定涨多少。
而是因为我认为,当 AI 真正进入大规模应用阶段,可信度一定会成为核心资产。
没有可信度,再强的模型也只是黑盒。
而能建立信任和秩序的基础设施,才可能穿越周期。

这或许才是 #OpenLedger 真正值得关注的地方~