
3D Avatar Diffusion este un algoritm de învățare automată care poate lua o singură imagine 2D a unei fețe umane și poate crea un avatar tridimensional (3D). Avatarul poate fi apoi folosit pentru a crea o experiență de realitate virtuală (VR) sau de realitate augmentată (AR) sau pur și simplu pentru a oferi o vedere 3D realistă a persoanei pentru jocuri sau alte scopuri.
Modelul de difuzie a fost dezvoltat de o echipă de cercetători de la Microsoft Research și este descris într-o lucrare publicată în jurnalul arXiv.

3D Avatar Diffusion se bazează pe un tip de algoritm de învățare automată numit model de difuzie. Modelele de difuzie sunt modele generative, ceea ce înseamnă că pot genera date noi care sunt similare cu datele de antrenament. Modelele de difuzie au fost folosite anterior pentru a genera imagini 3D din imagini 2D, dar ADM este primul model de difuzie care poate genera un avatar 3D realist dintr-o singură imagine 2D.
Pentru a antrena modelul, cercetătorii au folosit un set de date de peste 200.000 de modele de fețe 3D. Setul de date a inclus o mare varietate de fețe cu diferite nuanțe de piele, coafuri și trăsături faciale. ADM a putut apoi să învețe relația dintre imaginea 2D și modelul feței 3D și să genereze un avatar 3D realist dintr-o singură imagine 2D.
Modelul poate fi folosit și pentru a genera un avatar dintr-o fotografie care a fost făcută dintr-un unghi diferit
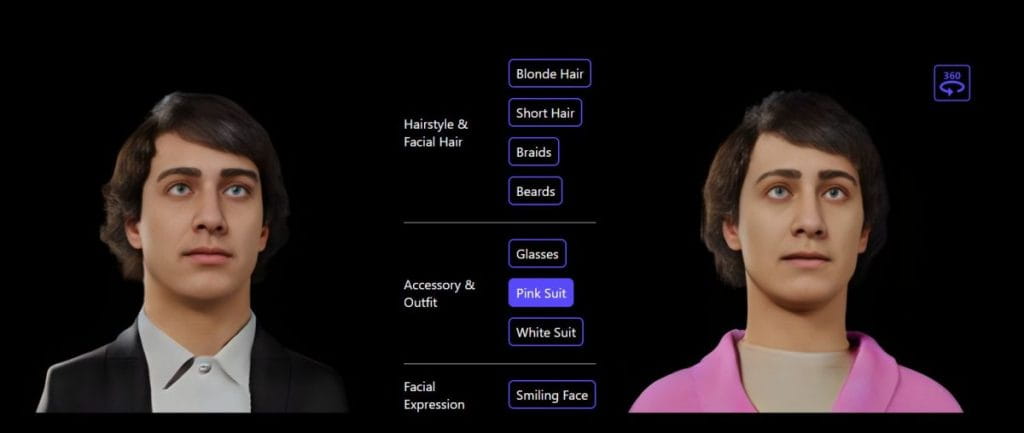 Pentru avatarul 3D personalizat, modelul Rodin oferă manipulare ghidată de text. Editarea în limbaj natural este o modalitate intuitivă de a schimba multe caracteristici diferite de avatar 3D.
Pentru avatarul 3D personalizat, modelul Rodin oferă manipulare ghidată de text. Editarea în limbaj natural este o modalitate intuitivă de a schimba multe caracteristici diferite de avatar 3D.
Acest studiu propune un model generativ 3D care creează automat avatare digitale 3D care sunt reprezentate ca câmpuri de radiație neuronale folosind modele de difuzie. Din cauza cerințelor prohibitive de memorie și procesare asociate cu 3D, crearea funcțiilor bogate necesare pentru avatare de înaltă calitate este o problemă uriașă. Dezvoltatorii sugerează că rețeaua de difuzare de lansare (Rodin) abordează această problemă.
 În ceea ce privește sexul, vârsta, rasa, expresia, accesoriile faciale etc., modelul prezintă o diversitate generațională remarcabilă.
În ceea ce privește sexul, vârsta, rasa, expresia, accesoriile faciale etc., modelul prezintă o diversitate generațională remarcabilă.
Această rețea desfășoară numeroase hărți de caracteristici 2D ale unui câmp de radiație neural într-un singur plan de caracteristici 2D, unde modelul execută apoi difuzarea conștientă de 3D. Modelul Rodin folosește convoluția 3D-aware, care se ocupă de caracteristicile proiectate în planul caracteristicilor 2D în conformitate cu relația lor originală în 3D, pentru a oferi eficiența computațională atât de necesară, menținând în același timp integritatea difuziei în 3D.
Citiți mai multe despre AI:
VALL-E: Noul model de redare a textului în vorbire de la Microsoft poate duplica vocea tuturor în trei secunde
VALL-E de la Microsoft pare a fi cel mai periculos software de escrocherie vreodată
Artistul creează un script antifurt pentru a proteja arta, folosește același filigran ca și generatoarele AI
Microsoft și Google în 2023: principala confruntare a anului între titanii AI
Postarea Microsoft a lansat un model de difuzare care poate construi un avatar 3D dintr-o singură fotografie a unei persoane a apărut mai întâi pe Metaverse Post.