

La începutul lunii septembrie, Yandex a găzduit o mini-conferință privată despre IA generativă, oferind o platformă pentru scufundări profunde în lumea AI. Cu toate acestea, conferința a adus revelații semnificative, în special în ceea ce privește mult așteptatul YandexGPT 2.
Dezvăluirea YandexGPT 2 de către Yandex a făcut ca comunitatea AI să urmeze de nerăbdare. Creatorii acestui model au explorat diverse caracteristici distinctive, inclusiv un modul specializat conceput pentru a căuta și a oferi răspunsuri bazate pe datele rezultatelor căutării. În mod remarcabil, dezvăluirile echipei au dezvăluit un aspect izbitor: chiar și atunci când a fost instruit pe un depozit vast de date interne Yandex care acoperă peste un deceniu de muncă asupra mecanismelor de căutare neuronală, acest model proprietar nu a ajuns în continuare la formidabilul GPT-4. Această dezvoltare semnificativă subliniază progresele remarcabile realizate de GPT-4. Această observație accentuează supremația GPT-4 atât asupra dezvoltărilor proprietare, cât și asupra iterațiilor anterioare open-source.
Expandând astfel de informații fundamentale, Google a realizat un studiu pentru a evalua acuratețea răspunsurilor de la modelele de limbaj mari (LLM) împuternicite cu acces la motorul de căutare. Deși noțiunea de integrare a unui instrument extern cu LLM-urile nu este nouă, Google a constatat că complexitatea constă în evaluarea și validarea nuanțată a acestor modele. Factorii cruciali care modelează această integrare cuprind selecția unui prompt elaborat cu atenție și capacitățile intrinseci ale LLM-urilor.
Metodologia de testare LLM de la Google
Un corpus organizat de 600 de întrebări a fost împărțit în patru grupuri distincte. Fiecare grup a acordat prioritate acurateței faptelor, dar un grup s-a remarcat prin includerea întrebărilor bazate pe premise false. De exemplu, întrebări precum „ce a scris Trump după ce a fost dezinterdit pe Twitter?” conținea o premisă inexactă, deoarece Trump nu fusese interzis. Celelalte trei grupuri au introdus variabile de învechire a răspunsurilor: niciodată, rar și des. În grupul „niciodată”, se aștepta ca LLM să răspundă doar din memorie, în timp ce întrebările despre evenimente recente necesitau o căutare în timp real. Fiecare grup a fost format din 125 de întrebări.
Întrebările au fost prezentate unei game variate de modele. În mod intrigant, întrebările care conțin premise false au dezvăluit dominația GPT-4 și ChatGPT, care au respins cu pricepere astfel de premise, indicând pregătirea lor specifică pentru a face față unor astfel de provocări.
A urmat o analiză comparativă, punând în față ChatGPT, GPT-4, căutarea Google (pe baza fragmentelor de text sau a răspunsurilor de pe prima pagină) și PPLX.AI (o platformă care folosește ChatGPT pentru a agrega răspunsurile Google, destinate dezvoltatorilor). În acest context, LLM-urile au oferit răspunsuri exclusiv din memoria lor.
Într-o observație demnă de remarcat, căutarea Google a oferit răspunsuri corecte în 40% din cazuri, în medie, în cele patru grupuri. Precizia întrebărilor „eterne” a fost de 70%, în timp ce întrebările cu premise false au scăzut la doar 11%. Performanța ChatGPT a înregistrat o medie de 26%, în timp ce GPT-4 a atins 28%, răspunzând impresionant la întrebări cu premise false în 42% din cazuri. PPLX.AI a demonstrat o rată de succes de 52%.
Studiul a aprofundat prin integrarea unei abordări inedite. Fiecare întrebare a determinat o căutare pe Google, rezultatele fiind încorporate în prompt. LLM-urile au fost apoi obligate să „citească” aceste informații înainte de a-și compune răspunsurile. Această tehnică a permis învățarea Few-Shot (unde sunt prezentate exemple în promptul pentru a ghida modelul) și o analiză atentă pas cu pas înainte de a răspunde.
Rezultatele au fost absolut fascinante. GPT-4 a prezentat o evaluare remarcabilă a calității de 77%, răspunzând la întrebări „eterne” cu o acuratețe de 96% și abordând întrebări cu premise false cu o precizie lăudabilă de 75%. În timp ce ChatGPT a oferit valori ceva mai puțin impresionante, a depășit atât PPLX.AI, cât și căutarea Google.
Stăpânirea AI Prompt Design: informații cheie de la PPLX.AI și experții Google
Capacitatea de a ghida în mod eficient modelele lingvistice mari (LLM) printr-un labirint de informații nu este o faptă mică. Cu toate acestea, o explorare recentă a solicitărilor AI a evidențiat strategiile cheie care promit să îmbunătățească calitatea răspunsurilor generate de LLM, oferind o privire asupra mecanismelor nuanțate ale asistenței AI.
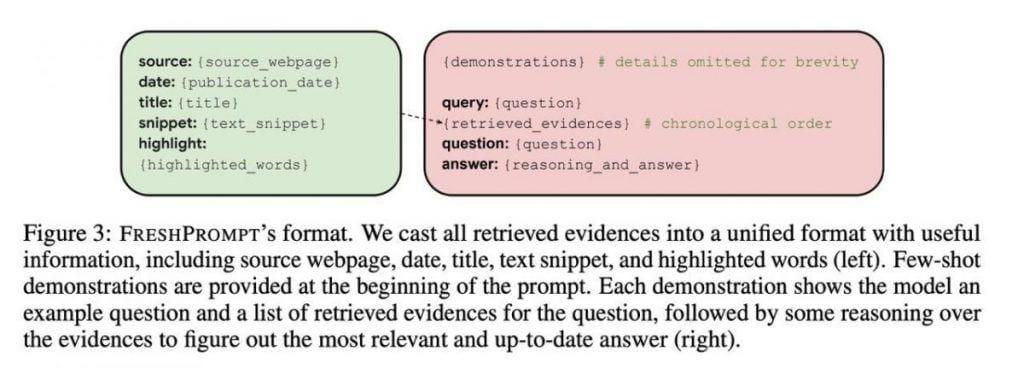
Fundamentul acestei revelații a fost stabilit printr-o structurare atentă promptă. Această metodă constă din mai multe componente, oferind o cale clară pentru obținerea de răspunsuri precise, ferm fundamentate pe înțelegerea contextuală. Aspectul inițial include exemple ilustrative, servind drept markeri de ghidare, direcționând LLM-urile către răspunsul corect bazat pe indicii contextuale.
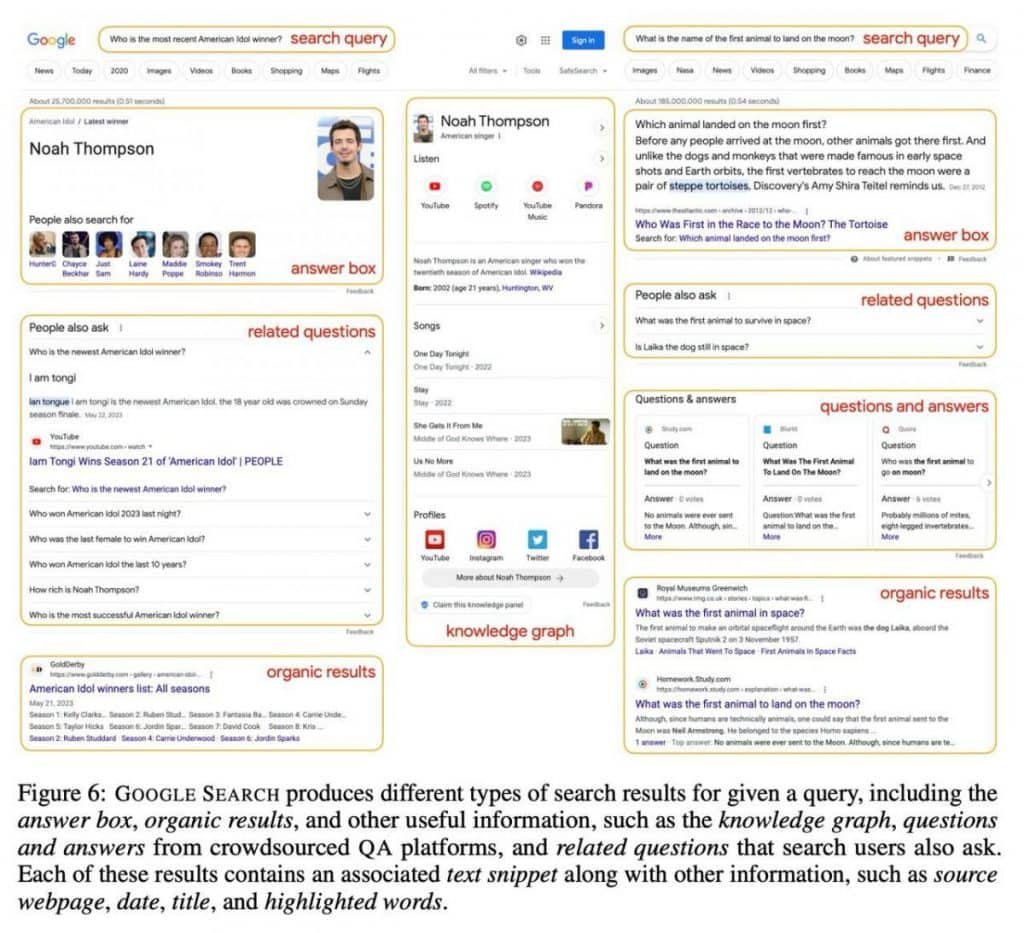
al doilea strat dezvăluie interogarea reală împreună cu 10-15 rezultate de căutare. Aceste rezultate depășesc simplele link-uri ale paginilor web, cuprinzând o mulțime de informații, inclusiv conținut textual, interogări relevante, întrebări, răspunsuri și grafice de cunoștințe. Această abordare echipează AI cu o bibliotecă cuprinzătoare de cunoștințe.
Rafinamentul acestui sistem merge mai departe. O descoperire crucială a apărut la aranjarea cronologică a legăturilor în cadrul promptului, plasând cele mai recente completări la sfârșit. Această aranjare cronologică oglindește natura în evoluție a informațiilor, permițând modelului să discerne cronologia schimbărilor. Includerea datelor în fiecare exemplu a jucat un rol esențial în îmbunătățirea înțelegerii contextuale.
În timp ce codul care să folosească această structurare nuanțată a promptului este așteptat cu nerăbdare, absența acestuia i-a determinat pe entuziaști să se aventureze să rescrie șabloane de prompt pe baza imaginilor furnizate.
Câteva concluzii cheie reiese din această incursiune în mecanica solicitărilor AI:
1) PPLX.AI, o platformă care folosește ChatGPT pentru a agrega răspunsurile Google, a apărut ca o opțiune promițătoare. Chiar și angajații Google au făcut aluzie la superioritatea sa.
2) Experimentarea cu diferite elemente a produs îmbunătățiri în metrica răspunsului. Precizia în construcția promptă, se pare, este o artă în sine.
3) GPT-4 demonstrează o competență lăudabilă în procesarea unor seturi extinse de știri și texte. Deși este posibil să nu fie caracterizat drept „excelent”, calitatea sa, chiar și în scenariile de știri în schimbare rapidă, se situează în jurul valorii de 60%. Comunitatea AI este încurajată să evalueze în mod critic astfel de valori.
4) Pe măsură ce ecosistemul AI continuă să se extindă, LLM-urile integrate în motoarele de căutare sunt pe cale să devină omniprezente, găzduind un spectru larg de utilizatori. Prezența AI în experiențele de căutare de zi cu zi se află pe o traiectorie ascendentă, ceea ce înseamnă o schimbare transformatoare în modul în care informațiile sunt accesate și procesate.
Abordarea cu mai multe fațete oferă o modalitate promițătoare de a obține răspunsuri precise de la aceste modele de limbaj sofisticate, deoarece include exemple ilustrative, o interogare clar definită și o mulțime de informații contextuale. Aranjarea cronologică a legăturilor în cadrul prompturilor a condus la o perspectivă semnificativă, subliniind importanța adaptării la natura dinamică a informațiilor. LLM-urile pot naviga pe cronologia schimbărilor datorită acestei conștientizări temporale, care le îmbunătățește înțelegerea contextuală.
Postarea Analiza Google dezvăluie perspective surprinzătoare asupra LLM-urilor și acurateței motoarelor de căutare a apărut mai întâi pe Metaverse Post.