

Titlul original: „De la GPT-1 la GPT-4, uită-te la ascensiunea ChatGPT”
Autor original: Alpha Rabbit Research Notes
Ce este ChatGPT?

Ce este ChatGPT?
Recent, OpenAI a lansat ChatGPT, un model care poate interacționa într-o manieră conversațională Datorită inteligenței sale, a fost binevenit de mulți utilizatori. ChatGPT este, de asemenea, o rudă a InstructGPT lansat anterior de OpenAI. Modelul ChatGPT este antrenat folosind RLHF (Învățare de întărire cu feedback uman) Poate că sosirea ChatGPT este și preludiul înainte de lansarea oficială a OpenAI-4.
Ce este GPT? De la GPT-1 la GPT-3
Generative Pre-Trained Transformer (GPT) este un model de învățare profundă pentru generarea de text, antrenat pe datele disponibile pe Internet. Este folosit pentru răspunsul la întrebări, rezumarea textului, traducerea automată, clasificarea, generarea de cod și IA conversațională.
În 2018 s-a născut GPT-1, care a fost și primul an de modele de pre-training pentru NLP (prelucrarea limbajului natural). În ceea ce privește performanța, GPT-1 are o anumită capacitate de generalizare și poate fi folosit în sarcini NLP care nu au nimic de-a face cu sarcinile de supraveghere. Sarcinile comune includ:
Raționament în limbaj natural: determinați relația dintre două propoziții (conținere, contradicție, neutralitate)
Întrebare și răspuns și raționament de bun simț: introduceți un articol și mai multe răspunsuri și afișați acuratețea răspunsului
Recunoașterea asemănării semantice: Determinați dacă două propoziții sunt legate semantic
Categorie: Stabiliți cărei categorii îi aparține textul introdus
Deși GPT-1 are unele efecte asupra sarcinilor neajustate, capacitatea sa de generalizare este mult mai mică decât cea a sarcinilor supravegheate ajustate.
GPT-2 a sosit și el așa cum era programat în 2019. Cu toate acestea, GPT-2 nu a realizat prea multe inovații structurale și design-uri pe rețeaua originală. A folosit doar mai mulți parametri de rețea și un set de date mai mare: totalul maxim al modelului Are 48 de straturi și 1,5 miliarde de parametri ținta de învățare folosește un model de pre-formare nesupravegheat pentru a efectua sarcini supravegheate. În ceea ce privește performanța, pe lângă capabilitățile de înțelegere, GPT-2 a demonstrat pentru prima dată un talent puternic în generație: citirea rezumatelor, chatul, continuarea scrierii, inventarea poveștilor și chiar generarea de știri false, e-mailuri de phishing sau jocuri de rol. online. Nu este o problemă. După ce „a devenit mai mare”, GPT-2 și-a demonstrat capabilitățile universale și puternice și a obținut cea mai bună performanță la acea vreme în mai multe sarcini specifice de modelare a limbii.
După aceea, GPT-3 a apărut ca model nesupravegheat (acum adesea numit model auto-supravegheat), aproape că poate îndeplini majoritatea sarcinilor de procesare a limbajului natural, cum ar fi căutarea orientată spre probleme, înțelegerea lecturii, inferența semantică și traducerea automată. , generarea articolului și întrebarea și răspunsul automat etc. În plus, modelul funcționează bine în multe sarcini, cum ar fi atingerea nivelului actual de ultimă generație în sarcinile de traducere automată franceză-engleză și germană-engleză 52% precizie), comparabilă cu ghicitul aleatoriu), și ceea ce este și mai surprinzător este că atinge o precizie de aproape 100% în sarcinile de adunare și scădere din două cifre și poate chiar genera automat cod pe baza descrierii sarcinii. Un model nesupravegheat are multe funcții și efecte bune și se pare că oamenii văd speranța unei inteligențe artificiale generale Acesta poate fi principalul motiv pentru care GPT-3 are un impact atât de mare.
Ce este mai exact modelul GPT-3?
De fapt, GPT-3 este un model simplu de limbaj statistic. Din perspectiva învățării automate, modelele de limbaj modelează distribuția probabilității secvențelor de cuvinte, adică folosind fragmentele care au fost spuse ca condiții pentru a prezice distribuția probabilității diferitelor cuvinte care apar în momentul următor. Pe de o parte, modelul de limbaj poate măsura gradul în care o propoziție se conformează cu gramatica limbii (de exemplu, măsurând dacă răspunsul generat automat de sistemul de dialog om-calculator este natural și fluent) și poate fi, de asemenea, utilizat pentru a prezice și a genera propoziții noi. De exemplu, pentru un clip „E ora 12, să mergem împreună la un restaurant”, modelul lingvistic poate prezice cuvintele care pot apărea după „restaurant”. Un model de limbaj general va prezice că următorul cuvânt este „mănâncă”.
De obicei, dacă un model de limbă este puternic depinde în principal de două puncte: în primul rând, dacă modelul poate folosi toate informațiile de context istoric În exemplul de mai sus, dacă nu poate capta informațiile semantice pe termen lung de „12 noon”. modelul de limbaj va fi aproape incapabil să prezică data viitoare. În al doilea rând, depinde și dacă există un context istoric suficient de bogat pentru ca modelul să poată fi învățat, adică dacă corpusul de instruire este suficient de bogat. Deoarece modelul de limbă este învățarea auto-supravegheată, scopul optimizării este de a maximiza probabilitatea modelului de limbă a textului văzut, astfel încât orice text poate fi folosit ca date de antrenament fără etichetare.
Datorită performanței mai puternice a lui GPT-3 și a mult mai mulți parametri, acesta conține mai mult text subiect, ceea ce este evident mai bun decât generația anterioară GPT-2. Fiind cea mai mare rețea neuronală densă disponibilă în prezent, GPT-3 poate converti descrierile paginilor web în coduri corespunzătoare, poate imita narațiunile umane, poate crea poezii personalizate, poate genera scenarii de joc și chiar poate imita filozofii decedați, prezicând adevăratul sens al vieții. Și GPT-3 nu necesită reglare fină, necesită doar câteva mostre de tipul de ieșire (o cantitate mică de învățare) pentru a face față problemelor gramaticale dificile. Se poate spune că GPT-3 pare să fi satisfăcut toată imaginația noastră pentru experții lingvistici.
Notă: cele de mai sus se referă în principal la următoarele articole:
1. GPT 4 este pe cale să fie lansat și este comparabil cu creierul uman. Mulți jucători mari din industrie nu pot sta pe loc! -Xu Jiecheng, Yun Zhao -Cont public 51 CTO Technology Stack- 2022-11-24 18:08
2. Răspunde-ți curiozitatea despre GPT-3 într-un articol! Ce este GPT-3? De ce este atât de excelent? -Zhang Jiajun Institute of Automation, Academia Chineză de Științe Publicat la Beijing pe 2020-11-11 17:25
3.Lotul: 329 | InstructGPT, un model de limbă mai prietenos și mai blând - cont public DeeplearningAI-2022-02-07 12:30
Care sunt problemele cu GPT-3?
Dar GTP-3 nu este perfect Una dintre principalele probleme de care oamenii sunt cel mai îngrijorați în inteligența artificială este că chatbot-urile și instrumentele de generare de text sunt susceptibile să învețe toate textele de pe Internet, la rândul lor, incorecte, ofensatoare. sau chiar se produce un limbaj ofensator, care va afecta pe deplin următoarea lor aplicație.
OpenAI a propus, de asemenea, că un GPT-4 mai puternic va fi lansat în viitorul apropiat:
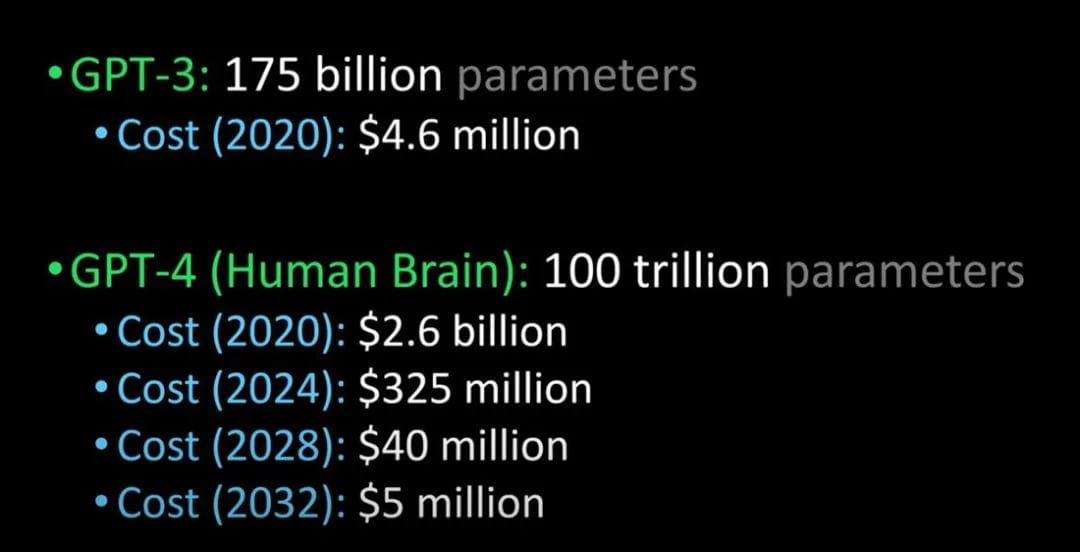
Comparând GPT-3 cu GPT-4 și creierul uman (Credit imagine: Lex Fridman @youtube)
Se spune că GPT-4 va fi lansat anul viitor. Poate trece testul Turing și poate fi atât de avansat încât nu se poate distinge de oameni.
ChatGP și InstructGPT
ChatGPT și InstructGPT
Când vorbim despre Chatgpt, trebuie să vorbim despre „predecesorul” său InstructGPT.
La începutul anului 2022, OpenAI a lansat InstructGPT în această cercetare, în comparație cu GPT-3, OpenAI a folosit cercetarea de aliniere pentru a antrena un model de limbaj care este mai realist, mai inofensiv și care urmărește mai bine intențiile utilizatorului versiunea GPT-3 care minimizează ieșirea dăunătoare, nerealistă și părtinitoare.
Cum funcționează InstructGPT?
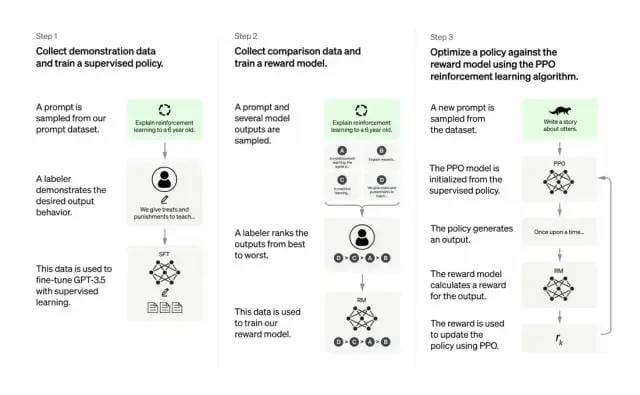
Dezvoltatorii fac acest lucru combinând învățarea supravegheată + învățarea de întărire din feedbackul uman. Pentru a îmbunătăți calitatea ieșirii a GPT-3. În acest tip de învățare, oamenii clasifică rezultatele potențiale ale unui model, algoritmii de învățare prin întărire recompensează modele care produc materiale similare rezultatelor de nivel înalt.
Setul de date de antrenament începe prin crearea de prompturi, dintre care unele se bazează pe inputul utilizatorilor GPT-3, cum ar fi „Spune-mi o poveste despre o broască” sau „Explică aterizarea pe lună unui copil de 6 ani în câteva propoziții. ”
Dezvoltatorii au împărțit promptul în trei părți și au creat răspunsuri pentru fiecare parte în mod diferit:
Scriitorii umani răspund la primul set de solicitări. Dezvoltatorii au reglat fin un GPT-3 instruit și l-au transformat în InstructGPT pentru a genera răspunsuri existente pentru fiecare prompt.
Următorul pas este să antrenezi un model pentru a recompensa răspunsurile mai bune cu recompense mai mari. Pentru al doilea set de solicitări, modelul optimizat generează răspunsuri multiple. Evaluatorii umani clasează fiecare răspuns. Având în vedere un prompt și două răspunsuri, un model de recompensă (un alt GPT-3 pre-antrenat) a învățat să calculeze o recompensă mai mare pentru răspunsul cu o evaluare foarte bună și o recompensă mai scăzută pentru răspunsul cu rating scăzut.
Dezvoltatorii au ajustat în continuare modelul de limbaj folosind un al treilea set de indicii și metoda de învățare prin consolidare Proximal Policy Optimization (PPO). Când este dat un prompt, modelul de limbă generează un răspuns, iar modelul de recompensă îl recompensează în consecință. PPO folosește recompense pentru a actualiza modelul lingvistic.
Referință pentru acest paragraf: Lotul: 329 | InstructGPT, un model de limbaj mai prietenos și mai blând-cont public DeeplearningAI- 2022-02-07 12:30.
Ce este important? Esența este că inteligența artificială trebuie să fie inteligență artificială responsabilă
Modelul de limbaj OpenAI poate ajuta în domeniile educației, terapeuților virtuali, ajutoarelor de scris, jocurilor de rol etc. În aceste domenii, existența părtinirii sociale, a dezinformarii și a informațiilor toxice este mai supărătoare, iar sistemele care pot evita aceste defecte pot fii mai capabil.
Care sunt diferențele dintre procesele de instruire ale Chatgpt și InstructGPT?
În general, Chatgpt, ca și InstructGPT de mai sus, este antrenat folosind RLHF (Învățare prin consolidare din feedback uman). Diferența este modul în care datele sunt configurate pentru antrenament (și colectate). (Explicație aici: modelul InstructGPT anterior a dat o ieșire pentru o intrare și apoi a comparat-o cu datele de antrenament. Da, au existat recompense și nu penalități; actualul Chatgpt este o intrare, iar modelul oferă mai multe ieșiri, apoi oamenii da Această sortare a rezultatelor permite modelului să clasifice aceste rezultate de la „mai asemănător omului” la „prostii”, permițând modelului să învețe modul în care oamenii sortează. Această strategie se numește învățare supravegheată acest paragraf)
Care sunt limitările ChatGPT?
după cum urmează:
a) În timpul fazei de învățare prin întărire (RL), nu există o sursă specifică de adevăr și răspunsuri standard la întrebările dumneavoastră.
b) Modelul este antrenat să fie mai precaut și poate respinge răspunsurile (pentru a evita fals pozitive ale solicitărilor).
c) Instruirea supravegheată poate induce în eroare/prejudecă modelul spre cunoașterea răspunsului ideal, mai degrabă decât modelul să genereze un set aleatoriu de răspunsuri și doar recenzenții umani care aleg răspunsurile bune/cel mai bine clasate
Notă: ChatGPT este sensibil la formulare. , uneori modelul ajunge să nu răspundă la o frază, dar cu o ușoară modificare la întrebare/expresie ajunge să răspundă corect. Formatorii au tendința de a prefera răspunsurile mai lungi, deoarece acestea pot apărea mai cuprinzătoare, ceea ce duce la o tendință pentru răspunsuri mai lungi și la utilizarea excesivă a anumitor fraze în model Dacă promptul sau întrebarea inițială este ambiguă, modelul nu va cere clarificări adecvate.
Limitările autoidentificate ale ChatGPT sunt următoarele.
Răspunsuri care sună plauzibil, dar incorecte:
a) Nu există o sursă reală de adevăr care să rezolve această problemă în timpul fazei de învățare prin consolidare (RL).
b) Modelul de antrenament pentru a fi mai precaut poate refuza în mod eronat să răspundă (fals pozitiv de prompturi supărătoare).
c) Instruirea supravegheată poate induce în eroare/prejudecăți modelul tinde să cunoască răspunsul ideal, mai degrabă decât modelul să genereze un set aleatoriu de răspunsuri și doar recenzenții umani care selectează un răspuns bun/înalt clasat.ChatGPT este sensibil la formulare. Uneori, modelul sfârșește fără răspuns pentru o frază, dar cu o ușoară modificare la întrebare/expresie, ajunge să răspundă corect.
Formatorii preferă răspunsuri mai lungi, care ar putea părea mai cuprinzătoare, ceea ce duce la o tendință către răspunsuri pronunțate și utilizarea excesivă a anumitor fraze. Modelul nu solicită clarificări în mod corespunzător dacă solicitarea sau întrebarea inițială este ambiguă. Un strat de siguranță pentru a refuza solicitările neadecvate prin intermediul API-ului Moderation. a fost implementat. Cu toate acestea, ne putem aștepta în continuare la răspunsuri fals negative și pozitive.
referinte:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 este pe cale să fie lansat și este comparabil cu creierul uman Mulți jucători mari din industrie nu pot sta nemișcați! -Xu Jiecheng, Yun Zhao -Cont public 51 CTO Technology Stack- 2022-11-24 18:08
5. Răspunde-ți curiozitatea despre GPT-3 într-un articol! Ce este GPT-3? De ce este atât de excelent? -Zhang Jiajun Institute of Automation, Academia Chineză de Științe Publicat la Beijing pe 2020-11-11 17:25
6.Lotul: 329 | InstructGPT, un model de limbă mai prietenos și mai blând - cont public DeeplearningAI-2022-02-07 12:30