
Principais conclusões
Na Binance, usamos aprendizado de máquina (ML) para resolver vários problemas de negócios, incluindo, entre outros, fraude de controle de conta (ATO), golpes P2P e detalhes de pagamento roubados.
Usando operações de aprendizado de máquina (MLOps), nossos cientistas de dados de IA da Binance Risk construíram um pipeline de ML de ponta a ponta em tempo real que fornece continuamente serviços de ML prontos para produção.

Por que usamos MLOps?
Para começar, criar um serviço de ML é um processo iterativo. Os cientistas de dados experimentam constantemente para melhorar uma métrica específica, seja offline ou online, com base no objetivo de agregar valor ao negócio. Então, como podemos tornar esse processo mais eficiente — por exemplo, reduzindo o tempo de colocação no mercado do modelo de ML?
Em segundo lugar, o comportamento dos serviços de ML é afetado não apenas pelo código que nós, os desenvolvedores, definimos, mas também pelos dados que coleta. Essa ideia, também conhecida como desvio de conceito, é enfatizada no artigo do Google intitulado Hidden Technical Debt in Machine Learning Systems.
Tomemos a fraude como exemplo; o golpista não é apenas uma máquina, mas um ser humano que se adapta e muda constantemente a forma como ataca. Como tal, a distribuição de dados subjacente evoluirá para refletir as mudanças nos vetores de ataque. Como podemos garantir efetivamente que o modelo de produção considere o padrão de dados mais recente?
Para superar os desafios mencionados acima, utilizamos um conceito denominado MLOps, termo proposto inicialmente pelo Google em 2018. No MLOps, focamos no desempenho do modelo e na infraestrutura de suporte ao sistema de produção. Isso nos permite construir serviços de ML escaláveis, altamente disponíveis, confiáveis e de fácil manutenção.
Dividindo nosso pipeline de ML ponta a ponta em tempo real
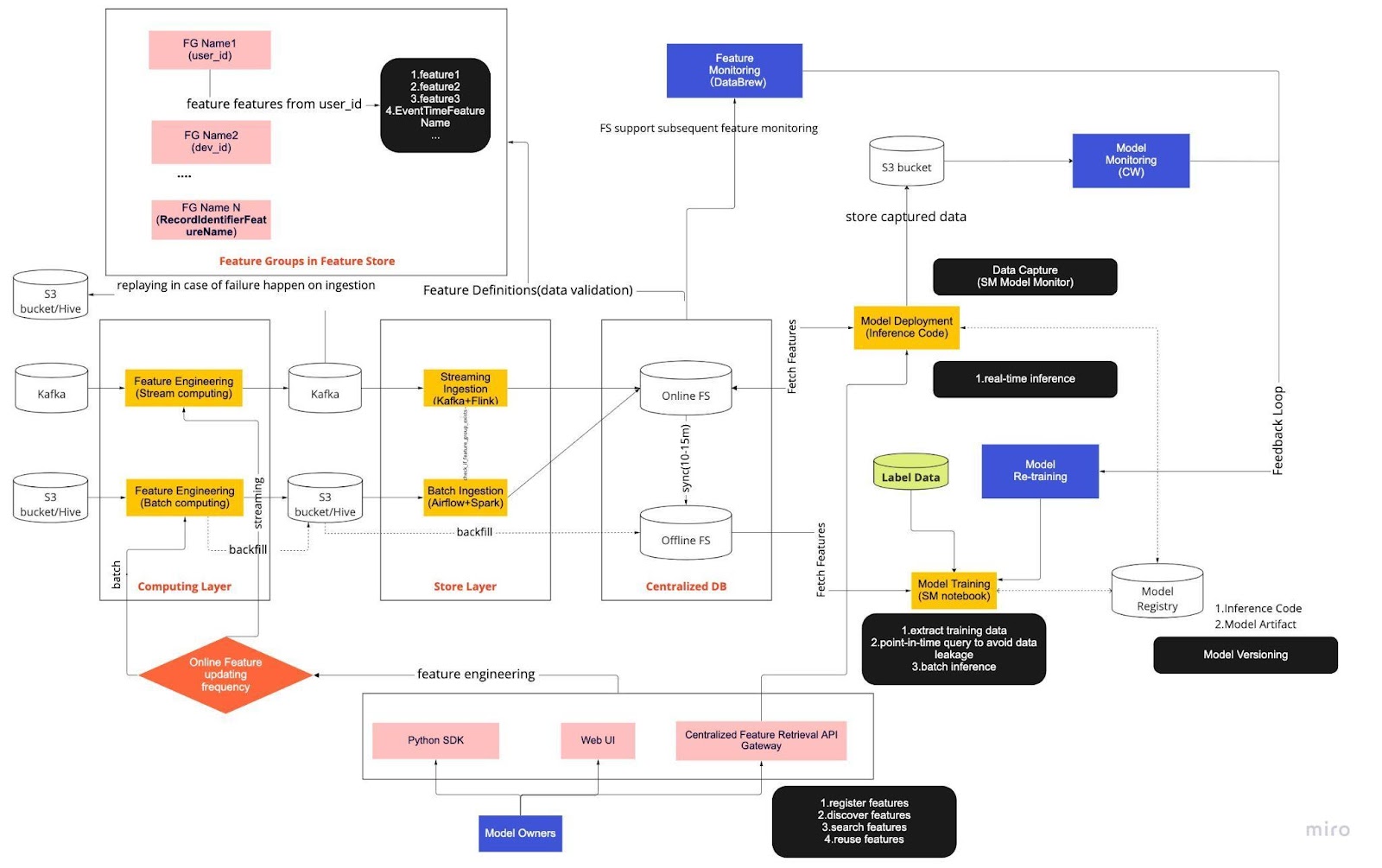
Pense no diagrama acima como nosso procedimento operacional padrão (SOP) para desenvolvimento de modelo em tempo real com um armazenamento de recursos. O pipeline de ML ponta a ponta determina como nossa equipe aplica MLops e é construído com dois tipos de requisitos: funcionais e não funcionais.
Funcional
Processamento de dados
Treinamento de modelo
Desenvolvimento de Modelo
Implantação de modelo
Monitoramento
requisitos não Funcionais
Escalável
Altamente disponível
Confiável
Sustentável
O pipeline é dividido em seis componentes principais:
Camada de computação
Camada de armazenamento
Banco de dados centralizado
Treinamento de modelo
Implantação de modelo
Monitoramento de modelo
1. Camada de Computação

A camada de computação é a principal responsável pela engenharia de recursos, o processo de transformação de dados brutos em recursos úteis.
Classificamos a camada de computação em dois tipos com base na frequência com que são atualizadas: computação em fluxo para intervalos de um minuto/segundo e computação em lote para intervalos diários/de hora em hora.
Os dados de entrada da camada de computação geralmente vêm do banco de dados baseado em eventos, que inclui Apache Kafka e Kinesis, ou do banco de dados OLAP, que inclui Apache Hive para soluções de código aberto e Snowflake para soluções em nuvem.
2. Camada de armazenamento
A camada de armazenamento é onde registramos as definições de recursos e as implantamos em nosso armazenamento de recursos, bem como realizamos o preenchimento, um processo que nos permite reconstruir recursos por meio de dados históricos sempre que um novo recurso é definido. O preenchimento normalmente é um trabalho único que nossos cientistas de dados podem realizar em um ambiente de notebook. Como o Kafka só pode armazenar eventos dos últimos sete dias, ele emprega um mecanismo de backup na tabela s3/hive para aumentar a tolerância a falhas.
Você notará que a camada intermediária, Hive e Kafka, está deliberadamente alojada entre as camadas de computação e de armazenamento. Pense neste posicionamento como um buffer entre os recursos de computação e escrita. Uma analogia seria separar o produtor do consumidor. A computação de fluxo é o produtor, enquanto a ingestão de fluxo é o consumidor.
A dissociação da computação e da ingestão oferece vários benefícios para nossos pipelines de ML. Para começar, podemos aumentar a robustez do pipeline em caso de falhas. Nossos cientistas de dados ainda podem extrair valor dos recursos do banco de dados centralizado, mesmo que a ingestão ou a camada de computação estejam indisponíveis devido a problemas operacionais, de hardware ou de rede.
Além disso, podemos dimensionar diferentes partes da infraestrutura individualmente e reduzir a energia necessária para construir e operar o gasoduto. Por exemplo, se falhar por qualquer motivo, a camada de ingestão não bloqueará a camada de computação. Na frente da inovação, podemos experimentar e adotar novas tecnologias, como uma nova versão da aplicação Flink, sem afetar a nossa infraestrutura existente.

Tanto a camada de computação quanto a camada de armazenamento são o que chamamos de pipelines de recursos automatizados. Esses pipelines são independentes, executados em programações variadas e são categorizados como pipelines de streaming ou em lote. Veja como os dois pipelines funcionam de maneira diferente: um grupo de recursos em um pipeline em lote pode ser atualizado todas as noites, enquanto outro grupo é atualizado de hora em hora. Num pipeline de streaming, o grupo de funcionalidades é atualizado em tempo real à medida que os dados de origem chegam num fluxo de entrada, como um tópico Apache Kafka.
3. Banco de dados centralizado
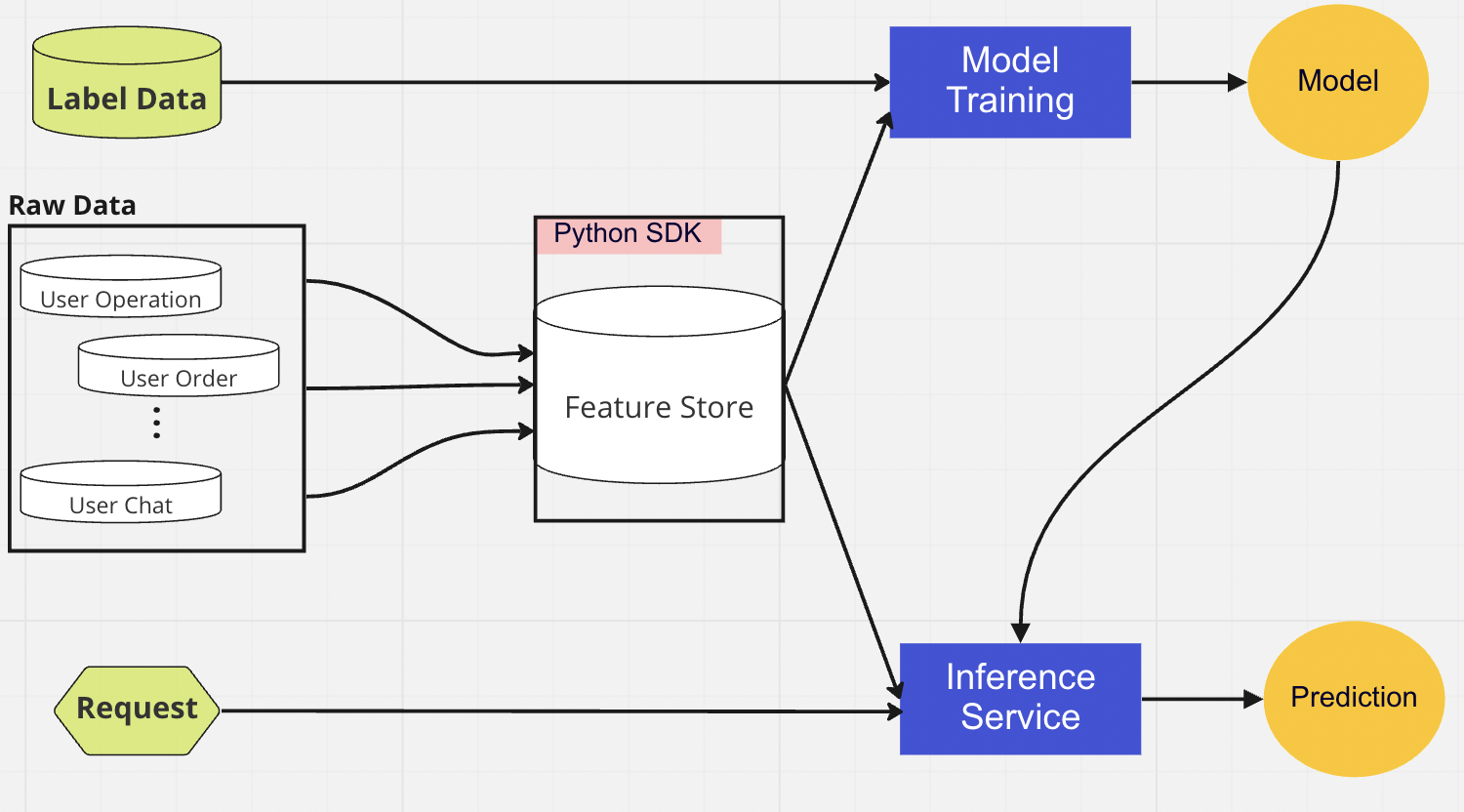
A camada de banco de dados centralizada é onde nossos cientistas de dados apresentam seus dados prontos para recursos em um armazenamento de recursos online ou offline.
O feature store online é um armazenamento de baixa latência e alta disponibilidade que permite a consulta de registros em tempo real. Por outro lado, o feature store offline fornece um repositório seguro e escalonável de todos os dados de recursos. Isso permite que os cientistas criem conjuntos de dados de treinamento, validação ou pontuação em lote a partir de um conjunto de grupos de recursos gerenciados centralmente com um registro histórico completo de valores de recursos no sistema de armazenamento de objetos.
Ambos os armazenamentos de recursos são sincronizados automaticamente entre si a cada 10-15 minutos para evitar distorções no fornecimento de treinamento. Em um artigo futuro, nos aprofundaremos em como usamos armazenamentos de recursos nos pipelines.
4. Treinamento de modelo
A camada de treinamento do modelo é onde nossos cientistas extraem dados de treinamento do armazenamento de recursos off-line para ajustar nossos serviços de ML. Usamos consultas pontuais para evitar vazamento de dados durante o processo de extração.
Além disso, esta camada inclui um componente crucial conhecido como ciclo de feedback de retreinamento de modelo. O retreinamento de modelos minimiza o risco de desvio de conceito, garantindo que os modelos implantados representem com precisão os padrões de dados mais recentes – por exemplo, um hacker alterando seu comportamento de ataque.
5. Implantação do modelo
Para a implantação do modelo, usamos principalmente um serviço de pontuação baseado em nuvem como a espinha dorsal do nosso serviço de dados em tempo real. Aqui está um diagrama que mostra como o código de inferência atual se integra ao feature store.

6. Monitoramento de Modelo
Nessa camada, nossa equipe monitora as métricas de uso para pontuar serviços como QPS, latência, memória e taxa de utilização de CPU/GPU. Além dessas métricas básicas, usamos dados capturados para verificar a distribuição de recursos ao longo do tempo, a distorção do serviço de treinamento e o desvio de previsão para garantir o mínimo desvio de conceito.
Considerações finais
Para finalizar, dividir vagamente nossa infraestrutura de pipeline em uma camada de computação, camada de armazenamento e banco de dados centralizado nos dá três benefícios principais em relação a uma arquitetura mais fortemente acoplada.
Pipelines mais robustos em caso de falhas
Maior flexibilidade na escolha de quais ferramentas implementar
Componentes escaláveis de forma independente
Interessado em usar o ML para proteger o maior ecossistema criptográfico do mundo e seus usuários? Confira Binance Engineering/AI em nossa página de carreiras para vagas de emprego abertas.