
A Stability AI lançou um novo artigo em seu blog sobre o Stable Diffusion 2. Nele, a Stability AI propõe um novo algoritmo que é mais eficiente e robusto que o anterior, ao mesmo tempo em que o compara com outros métodos de última geração.

O modelo Stable Diffusion V1 original da CompVis revolucionou a natureza dos modelos de IA de código aberto e produziu centenas de modelos e avanços diferentes ao redor do mundo. Ele viu uma das escaladas mais rápidas para 10.000 estrelas no Github, acumulando 33.000 em menos de dois meses, mais rápido do que mais programas no Github.
O lançamento original do Stable Diffusion V1 foi liderado pela equipe dinâmica formada por Robin Rombach (IA de Estabilidade) e Patrick Esser (ML de Pista) do CompVis Group da LMU Munique, liderados pelo Prof. Dr. Björn Ommer. Eles se basearam no trabalho anterior do laboratório com Modelos de Difusão Latente e receberam apoio crítico do LAION e da Eleuther AI.

 O que torna o Stable Diffusion v1 diferente do Stable Diffusion v2?
O que torna o Stable Diffusion v1 diferente do Stable Diffusion v2?
O Stable Diffusion 2.0 inclui uma série de melhorias e recursos significativos em relação à versão anterior, então vamos dar uma olhada neles.
A versão Stable Diffusion 2.0 apresenta modelos robustos de conversão de texto em imagem, treinados com um novo codificador de texto (OpenCLIP) desenvolvido pela LAION com o auxílio da Stability AI, o que melhora significativamente a qualidade das imagens geradas em relação às versões V1 anteriores. Os modelos de conversão de texto em imagem desta versão podem gerar imagens com resoluções padrão de 512×512 pixels e 768×768 pixels.
Esses modelos são treinados usando um subconjunto estético do conjunto de dados LAION-5B gerado pela equipe DeepFloyd da Stability AI, que é então filtrado para excluir conteúdo adulto usando o filtro NSFW da LAION.
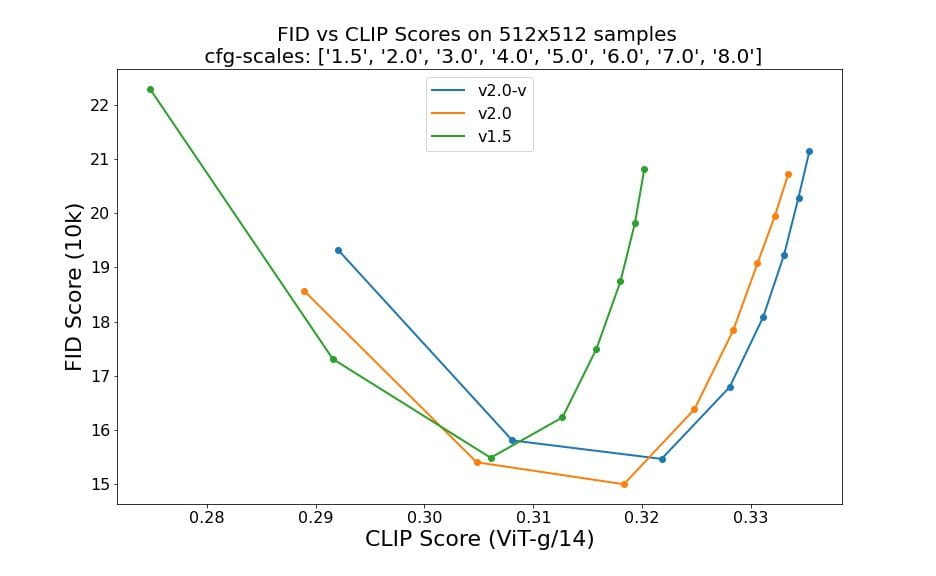
Avaliações usando 50 etapas de amostra DDIM, 50 escalas de orientação sem classificador e 1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0 e 8,0 indicam melhorias relativas dos pontos de verificação:
O Stable Diffusion 2.0 agora incorpora um modelo de Upscaler Diffusion, que aumenta a resolução da imagem em quatro vezes. Um exemplo do nosso modelo ampliando uma imagem gerada de baixa qualidade (128×128) para uma imagem de resolução mais alta é mostrado abaixo (512×512). O Stable Diffusion 2.0, quando combinado com nossos modelos de texto para imagem, agora pode gerar imagens com resoluções de 2048×2048 ou superiores.

O novo modelo de difusão estável guiado por profundidade, depth2img, estende o recurso imagem a imagem anterior da V1 com possibilidades criativas totalmente novas. O Depth2img determina a profundidade de uma imagem de entrada (usando um modelo existente) e, em seguida, gera novas imagens com base no texto e nas informações de profundidade. O Depth-to-Image pode oferecer uma infinidade de novas aplicações criativas, oferecendo alterações que parecem significativamente diferentes do original, mantendo a coerência e a profundidade da imagem.
O que há de novo no Stable Diffusion 2?
O novo modelo de difusão estável oferece uma resolução de 768×768.
O U-Net possui a mesma quantidade de parâmetros da versão 1.5, mas é treinado do zero e usa o OpenCLIP-ViT/H como codificador de texto. Um modelo de predição v é o SD 2.0-v.
O modelo acima mencionado foi ajustado a partir do SD 2.0-base, que também é disponibilizado e foi treinado como um modelo típico de predição de ruído em imagens 512×512.
Um modelo de difusão guiado por texto latente com escala x4 foi adicionado.
Modelo de difusão estável guiado por profundidade de base SD 2.0 refinado. O modelo pode ser utilizado para img2img com preservação de estrutura e síntese condicional à forma, sendo condicionado a estimativas de profundidade monoculares deduzidas por MiDaS.
Um modelo aprimorado de pintura guiada por texto, criado com base no SD 2.0.
Os desenvolvedores trabalharam arduamente, assim como na iteração inicial do Stable Diffusion, para otimizar o modelo para rodar em uma única GPU — eles queriam torná-lo acessível ao maior número possível de pessoas desde o início. Eles já viram o que acontece quando milhões de pessoas colocam as mãos nesses modelos e colaboram para construir coisas absolutamente extraordinárias. Este é o poder do código aberto: aproveitar o vasto potencial de milhões de pessoas talentosas que podem não ter os recursos para treinar um modelo de ponta, mas têm a capacidade de fazer coisas incríveis com um.

Esta nova atualização, combinada com novos recursos poderosos como depth2img e melhores capacidades de aumento de resolução, servirá como base para uma infinidade de novos aplicativos e permitirá uma explosão de novo potencial criativo.
Saiba mais sobre difusão estável:
IA de difusão estável cria mundos de sonho para VR e metaverso
O artista usa Stable Diffusion para produzir o primeiro filme de animação de IA completo
Conheça a pintura de vídeo: edição orientada a texto com difusão estável e atlas neurais
A postagem O algoritmo Stable Diffusion 2 da Stability AI finalmente é público: novo modelo depth2img, upscaler de super-resolução, sem conteúdo adulto apareceu primeiro no Metaverse Post.