
Principais conclusões
A Binance aproveita o gerenciamento de capacidade para picos de tráfego não planejados causados por alta volatilidade, garantindo infraestrutura e recursos de computação adequados e oportunos para as demandas de negócios.
Testes de carga da Binance no ambiente de produção (em vez de um ambiente de teste) para obter benchmarks de serviço precisos. Este método ajuda a validar se a nossa alocação de recursos é adequada para atender uma carga definida.
A infraestrutura da Binance lida com grandes quantidades de tráfego e a manutenção de um serviço do qual os usuários podem confiar requer gerenciamento de capacidade adequado e testes de carga automáticos.

Por que a Binance precisa de um processo especializado de gerenciamento de capacidade?
O gerenciamento de capacidade é a base da estabilidade do sistema. Implica dimensionar corretamente os recursos de aplicativos e infraestrutura de acordo com as demandas de negócios atuais e futuras e com o custo correto. Para ajudar a atingir esse objetivo, criamos ferramentas e pipelines de gerenciamento de capacidade para evitar sobrecarga e ajudar as empresas a fornecer uma experiência de usuário tranquila.
Os mercados de criptomoedas frequentemente lidam com períodos de volatilidade mais regulares do que os mercados financeiros tradicionais. Isso significa que o sistema da Binance deve suportar esse aumento de tráfego de tempos em tempos, à medida que os usuários reagem aos movimentos do mercado. Com um gerenciamento de capacidade adequado, mantemos a capacidade adequada para a demanda geral dos negócios e esses cenários de aumento de tráfego. Este ponto-chave é exatamente o que torna os processos de gestão de capacidade da Binance únicos e desafiadores.
Vejamos os fatores que muitas vezes atrapalham o processo e levam a um serviço lento ou indisponível. Primeiro, temos a sobrecarga, geralmente causada por um aumento repentino no tráfego. Por exemplo, isso pode resultar de um evento de marketing, uma notificação push ou até mesmo um ataque DDoS (negação de serviço distribuída).
O pico de tráfego e a capacidade insuficiente afetam a funcionalidade do sistema como:
O serviço exige cada vez mais trabalho.
O tempo de resposta aumenta até o ponto em que nenhuma solicitação pode ser respondida dentro do tempo limite do cliente. Essa degradação geralmente ocorre devido à saturação de recursos (CPU, memória, IO, rede, etc.) ou pausas prolongadas de GC no próprio serviço ou em suas dependências.
O resultado é que o serviço não conseguirá processar as solicitações prontamente.
Quebrando o processo
Agora que discutimos o princípio geral do gerenciamento de capacidade, vamos ver como a Binance aplica isso aos seus negócios. Aqui está uma visão geral da arquitetura do nosso sistema de gerenciamento de capacidade com alguns fluxos de trabalho importantes.
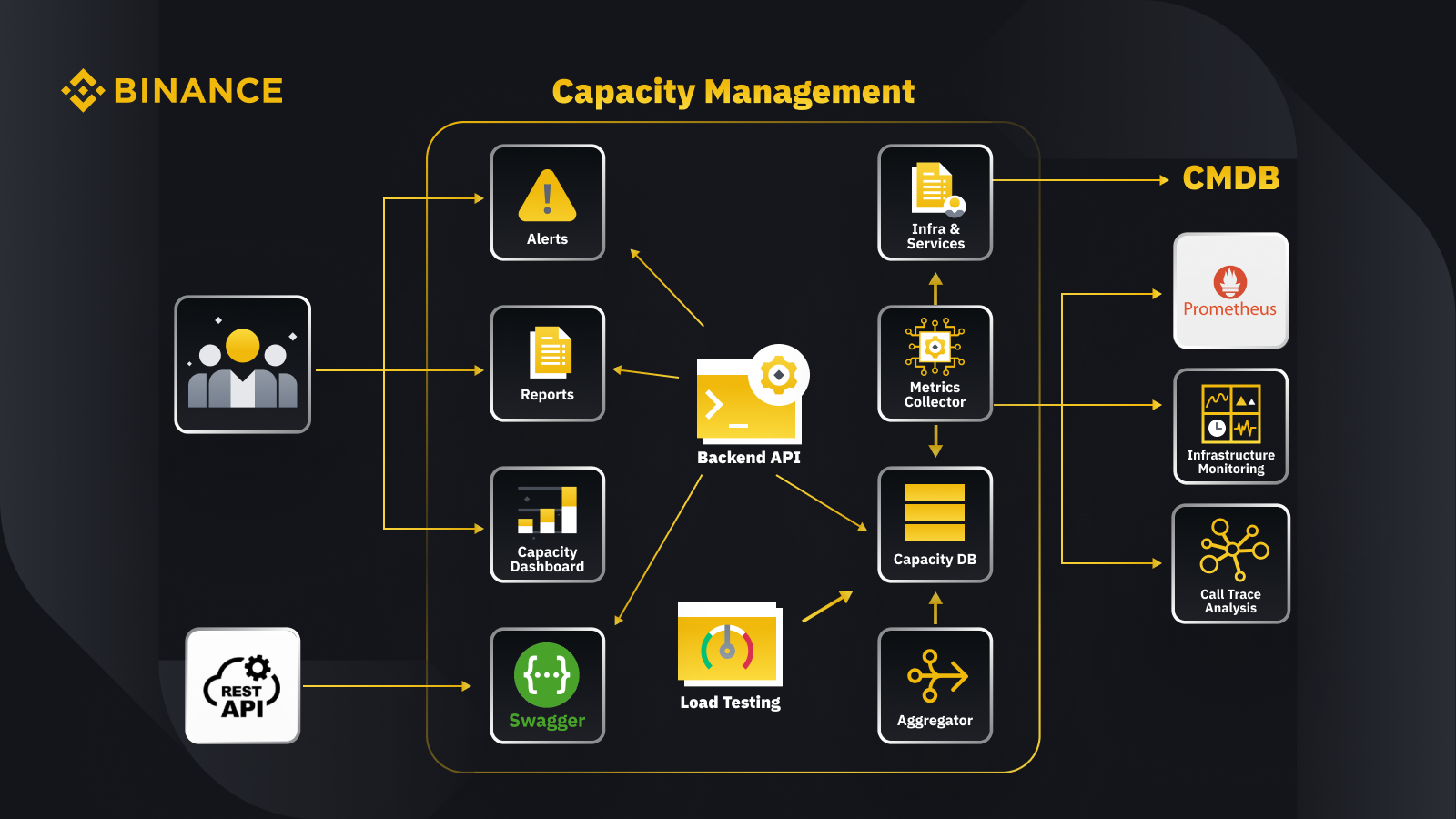
Ao buscar dados do banco de dados de gerenciamento de configuração (CMDB), geramos as configurações de infra e serviços. Os itens nessas configurações são os objetos de gerenciamento de capacidade.
O coletor de métricas busca métricas de capacidade do Prometheus para os dados da camada de negócios e de serviço, do Monitoramento de Infraestrutura para métricas da camada de recursos e do sistema de análise de rastreamento de chamadas para informações de rastreamento. O coletor de métricas armazena os dados no banco de dados de capacidade (CDB).
O sistema de testes de carga realiza testes de estresse nos serviços e armazena os dados de benchmark no CDB.
O agregador obtém os dados de capacidade do CDB e os agrega para dimensões diárias e de maior valor histórico (ATH). Após a agregação, ele grava os dados agregados de volta no CDB.
Ao processar os dados do CDB, a API de back-end fornece interfaces para o painel de capacidade, alertas e relatórios, bem como o restante da API e dados de capacidade relacionados para integração.
As partes interessadas obtêm insights sobre a capacidade por meio do painel de capacidade, alertas e relatórios. Eles também podem usar outros sistemas relacionados, incluindo monitoramento de dados de capacidade de serviços com API REST fornecida pelo sistema de gerenciamento de capacidade com Swagger.
Estratégia
Nossa estratégia de gerenciamento e planejamento de capacidade depende do processamento orientado aos picos. O processamento orientado por pico é a carga de trabalho experimentada pelos recursos de um serviço (servidores web, bancos de dados, etc.) durante o pico de uso.
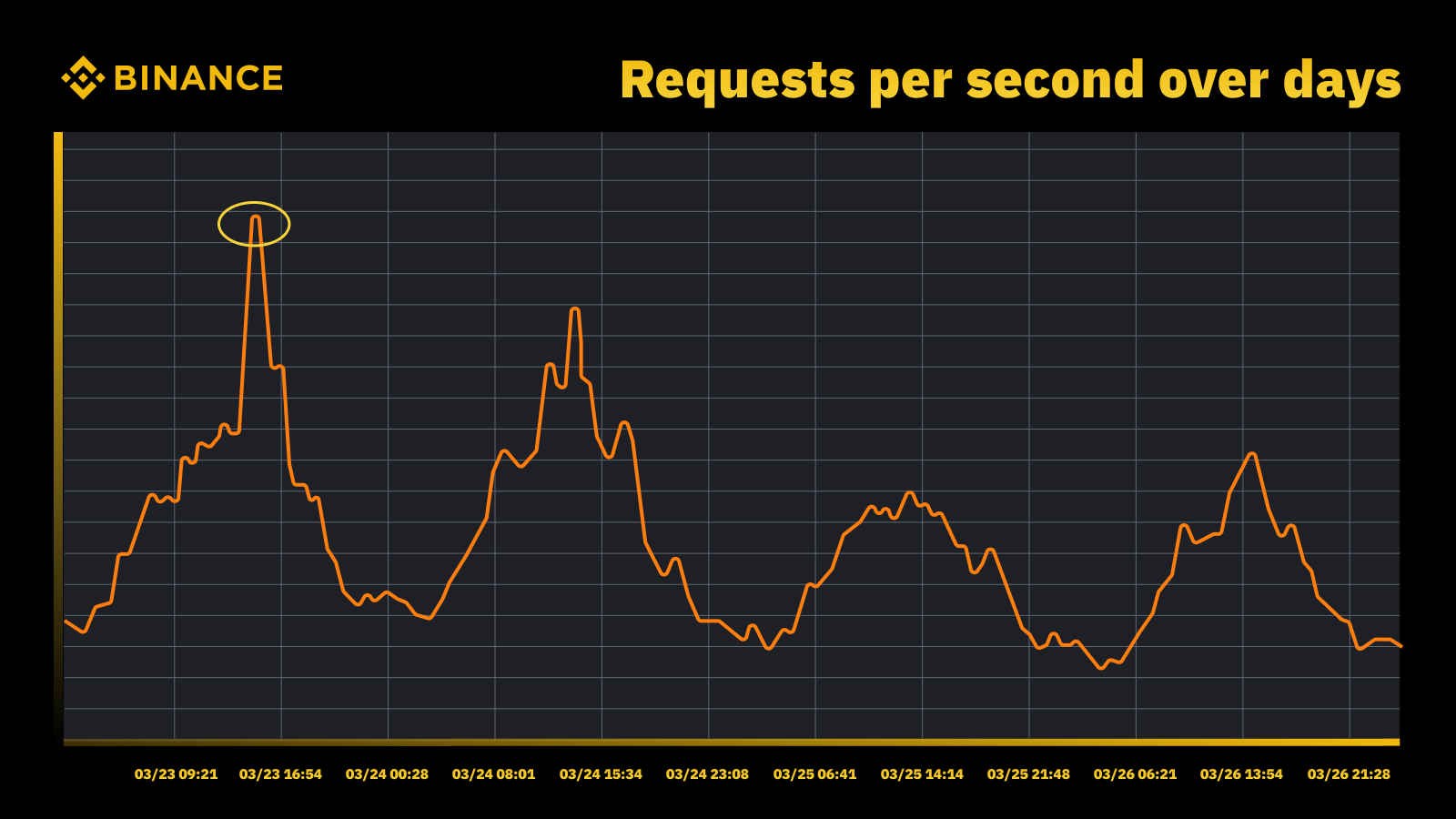
Aumento do tráfego quando o Fed aumentou a taxa em março de 2023
Analisamos os picos periódicos e os usamos para impulsionar a trajetória da capacidade. Tal como acontece com qualquer recurso orientado por picos, queremos descobrir quando os picos ocorrem e depois explorar o que realmente está acontecendo durante esses ciclos.
Outra coisa importante que consideramos junto com a prevenção da sobrecarga é o escalonamento automático. O escalonamento automático lida com a sobrecarga aumentando dinamicamente a capacidade com mais instâncias do serviço. O excesso de tráfego é então distribuído e o tráfego tratado por uma única instância do serviço (ou dependência) permanece gerenciável.
O escalonamento automático tem seu lugar, mas é insuficiente para lidar sozinho com situações de sobrecarga. Geralmente não consegue reagir rápido o suficiente a um aumento repentino no tráfego e só funciona melhor quando há um aumento gradual.
Medição
A medição desempenha um papel crucial no trabalho de gerenciamento de capacidade da Binance, e a coleta de dados é nossa primeira etapa de medição. Com base nos padrões da Information Technology Infrastructure Library (ITIL), coletamos dados para medição nos subprocessos de gestão de capacidade, a saber:
Recurso - consumo de recursos da infraestrutura de TI impulsionado pelo uso de aplicativos/serviços. Concentra-se em métricas de desempenho interno de recursos de computação físicos e virtuais, incluindo CPU do servidor, memória, armazenamento em disco, largura de banda da rede, etc.
Serviço. As medidas de desempenho, SLA, latência e rendimento em nível de aplicativo que surgem das atividades de negócios. Concentra-se em métricas de desempenho externo com base em como os usuários percebem o serviço, incluindo latência do serviço, taxa de transferência, picos, etc.
Negócios. Coleta dados que medem as atividades comerciais processadas pelo aplicativo de destino, incluindo pedidos, registro de usuários, pagamentos, etc.
O gerenciamento da capacidade baseado apenas na utilização dos recursos da infraestrutura levará a um planejamento impreciso. Isso ocorre porque pode não representar os volumes reais de negócios e a produtividade que impulsionam a capacidade da nossa infraestrutura.
Os eventos programados proporcionam um excelente local para discutir mais a fundo este assunto. Participe do Watch Web Summit 2022 na Binance Live para compartilhar até 15.000 BUSD na campanha Crypto Box Rewards. Além das métricas subjacentes da camada de recursos e serviços, também precisávamos considerar os volumes de negócios. Baseamos o planejamento de capacidade aqui em métricas de negócios, como o número estimado de espectadores de transmissão ao vivo, solicitações máximas em andamento para uma Crypto Box, latência ponta a ponta e outros fatores.
Depois de coletar os dados, nossos processos de gerenciamento de capacidade agregam e resumem os diversos pontos de dados coletados em relação a um driver de capacidade específico. O valor agregado de uma métrica é um valor único que pode ser usado em alertas de capacidade, relatórios e outras funções relacionadas à capacidade.
Podemos aplicar vários métodos de agregação de dados a pontos de dados periódicos, como soma, média, mediana, mínimo, máximo, percentil e máximo histórico (ATH).

O método escolhido determina os resultados do processo de gerenciamento de capacidade e as decisões resultantes. Selecionamos diferentes métodos com base em diferentes cenários. Por exemplo, usamos o método máximo para serviços críticos e pontos de dados relacionados. Para registrar o maior tráfego, usamos o método ATH.
Para diferentes casos de uso, usamos diferentes tipos de granularidade para agregação de dados. Na maioria dos casos, usamos minuto, hora, dia ou ATH.
Com granularidade minuciosa, medimos a carga de trabalho de um serviço para alertas de sobrecarga em tempo hábil.
Usamos dados agregados por hora para construir dados diários e agregamos os dados por hora para registrar o pico diário.
Normalmente usamos dados diários para relatórios de capacidade e aproveitamos os dados ATH para modelagem e planejamento de capacidade.
Uma das principais métricas do gerenciamento de capacidade é o benchmarking de serviços. Isso nos ajuda a medir com precisão o desempenho e a capacidade do serviço. Obtemos o benchmark de serviço com testes de carga e abordaremos isso com mais detalhes posteriormente.
Gerenciamento de capacidade baseado em prioridade
Até agora, vimos como coletamos métricas de capacidade e agregamos dados em diferentes tipos de granularidade. Outra área crítica a discutir é a prioridade, o que é útil no contexto de alertas e relatórios de capacidade. Depois de classificar os ativos de TI, o uso limitado de infraestrutura e recursos de computação são priorizados e atribuídos primeiro a serviços e atividades críticas.
Pode haver diversas maneiras de definir a criticidade do serviço e da solicitação. Uma referência útil é o Google. No livro SRE. Eles definem os níveis de criticidade como CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS etc. Da mesma forma, definimos vários níveis de prioridade, como P0, P1, P2 e assim por diante.
Definimos os níveis de prioridade da seguinte forma:
P0: Para os serviços e solicitações mais críticos, aqueles que resultarão em um impacto sério e visível ao usuário caso falhem.
P1: Para os serviços e solicitações que resultarão em impacto visível ao usuário, mas o impacto é menor que o de P0. Espera-se que os serviços P0 e P1 sejam fornecidos com capacidade suficiente.
P2: Esta é a prioridade padrão para trabalhos em lote e trabalhos offline. Esses serviços e solicitações podem não resultar em um impacto visível ao usuário se estiverem parcialmente indisponíveis.
O que é teste de carga e por que o usamos em um ambiente de produção?
O teste de carga é um processo de teste de software não funcional em que o desempenho de um aplicativo é testado sob uma carga de trabalho específica. Isso ajuda a determinar como o aplicativo se comporta ao ser acessado por vários usuários finais simultaneamente.
Na Binance, criamos uma solução que nos permite executar testes de carga em produção. Normalmente, os testes de carga são executados em um ambiente de teste, mas não poderíamos usar essa opção com base em nossos objetivos gerais de gerenciamento de capacidade. Os testes de carga em um ambiente de produção nos permitiram:
Colete uma referência precisa de nossos serviços em condições de carga reais.
Aumente a confiança no sistema e em sua confiabilidade e desempenho.
Identifique gargalos no sistema antes que eles aconteçam no ambiente de produção.
Habilite o monitoramento contínuo de ambientes de produção.
Habilite o gerenciamento proativo da capacidade com ciclos de testes normalizados que acontecem regularmente.
Abaixo você pode ver nossa estrutura de teste de carga com algumas conclusões importantes:

A estrutura de microsserviços da Binance tem uma camada base para suportar roteamento de tráfego orientado por configuração e baseado em sinalizações, o que é essencial para nossa abordagem TIP.
A análise canário automatizada (ACA) é adotada para avaliar a instância que estamos testando. Ele compara as principais métricas coletadas no sistema de monitoramento, para que possamos pausar/encerrar o teste se ocorrer algum problema inesperado para minimizar os impactos ao usuário.
Benchmarks e métricas são coletados durante o teste de carga para gerar insights de dados sobre comportamentos e desempenho de aplicativos.
As APIs estão expostas para compartilhar dados valiosos de desempenho em vários cenários, por exemplo, gerenciamento de capacidade e garantia de qualidade. Isso ajuda a construir um ecossistema aberto.
Criamos fluxos de trabalho de automação para orquestrar todas as etapas e pontos de controle de uma perspectiva de teste ponta a ponta. Também oferecemos a flexibilidade de integração com outros sistemas, como pipeline de CI/CD e portal de operação.
Nossa abordagem de testes em produção (TIP)
Uma abordagem tradicional de teste de desempenho (execução de testes em um ambiente de teste com tráfego simulado ou espelhado) oferece alguns benefícios. No entanto, a implantação de um ambiente de teste semelhante ao de produção tem mais desvantagens em nosso contexto:
Quase duplica o custo da infraestrutura e os esforços de manutenção.
É incrivelmente complexo fazer com que tudo funcione de ponta a ponta na produção, especialmente em um ambiente de microsserviços de grande escala em diversas unidades de negócios.
Isso adiciona mais riscos à privacidade e à segurança dos dados, pois, inevitavelmente, poderemos precisar duplicar os dados na preparação.
O tráfego simulado nunca replicará o que realmente acontece na produção. O benchmark obtido no ambiente de teste seria impreciso e teria menos valor
O teste em produção, também conhecido como TIP, é uma metodologia de teste shift-right em que novos códigos, recursos e versões são testados no ambiente de produção. O teste de carga em produção que adotamos é altamente benéfico, pois nos ajuda:
Analise a estabilidade e robustez do sistema.
Descubra benchmarks e gargalos de aplicativos sob diversos níveis de tráfego, especificações de servidor e parâmetros de aplicativos.
Roteamento baseado em FlowFlag
Nosso roteamento baseado em FlowFlag incorporado na estrutura base de microsserviços é a base para tornar o TIP possível. Isto é verdade para casos específicos, incluindo aplicações que usam descoberta de serviço Eureka para distribuição de tráfego.
Conforme ilustrado no diagrama, o servidor web Binance como pontos de entrada rotula uma porcentagem do tráfego conforme especificado nas configurações com cabeçalhos FlowFlag. Durante o teste de carga, podemos selecionar um host de um serviço específico e marcá-lo como a instância de desempenho de destino no configs, então essas solicitações de perf rotuladas serão eventualmente roteadas para a instância de perf quando chegarem ao serviço para processamento.
É totalmente orientado por configuração e carregamento a quente, podemos ajustar facilmente a porcentagem da carga de trabalho usando automação sem precisar implantar uma nova versão
Pode ser amplamente aplicado à maioria dos nossos serviços, uma vez que o mecanismo faz parte do gateway e do pacote básico
Um único ponto de mudança também significa reversão fácil para reduzir riscos na produção

Ao mesmo tempo em que transformamos nossa solução para ser mais nativa da nuvem, também estamos explorando como podemos construir uma abordagem semelhante para oferecer suporte a outros roteamentos de tráfego oferecidos por provedores de nuvem pública ou Kubernetes.
Análise canário automatizada para minimizar riscos de impacto ao usuário
A implantação canário é uma estratégia de implantação para reduzir o risco de implantação de uma nova versão de software em produção. Normalmente envolve a implantação de uma nova versão do software, chamada de versão canário, para um pequeno subconjunto de usuários junto com a versão estável em execução. Em seguida, dividimos o tráfego entre as duas versões para que uma parte das solicitações recebidas seja desviada para o canário.
A qualidade da versão canário é então avaliada pela chamada análise canário. Isso compara as principais métricas que descrevem o comportamento das versões antiga e nova. Se houver degradação significativa das métricas, o canário será abortado e todo o tráfego será roteado para a versão estável para minimizar o impacto do comportamento inesperado.
Usamos o mesmo conceito para construir nossa solução automática de teste de carga. A solução usa a plataforma Kayenta para análise automatizada de canários (ACA) via Spinnaker para permitir implantações automatizadas de canários. Nosso fluxo típico de teste de carga ao seguir este método é assim:
Por meio do fluxo de trabalho, adicionamos carga de tráfego de forma incremental (por exemplo, 5%, 10%, 25%, 50%) ao host de destino conforme especificado ou até atingir seu ponto de ruptura.
Sob cada carga, a análise canário é executada repetidamente com Kayenta por um determinado período de tempo (por exemplo, 5 minutos) para comparar as principais métricas do host testado com o período de pré-carregamento como linha de base e o período pós-carregamento atual como o experimento.
A comparação (modelo de configuração canário) concentra-se em verificar se o host de destino:
Atinge restrições de recursos, por exemplo, o uso da CPU excede 90%.
Tem um aumento significativo nas métricas de falha, por exemplo, logs de erros, exceções HTTP ou rejeições de limite de taxa.
As métricas principais do aplicativo ainda são razoáveis, por exemplo, uma latência HTTP de menos de 2 segundos (personalizável para cada serviço)
Para cada análise, Kayenta nos fornece um relatório para indicar o resultado, e o teste termina imediatamente após a falha.
Essa detecção de falha geralmente leva menos de 30 segundos, reduzindo significativamente a chance de impactar a experiência dos nossos usuários finais.

Habilitando insights de dados
É crucial coletar informações suficientes sobre todos os processos e execuções de testes descritos anteriormente. O objetivo final é melhorar a confiabilidade e robustez do nosso sistema, o que é impossível sem insights de dados.
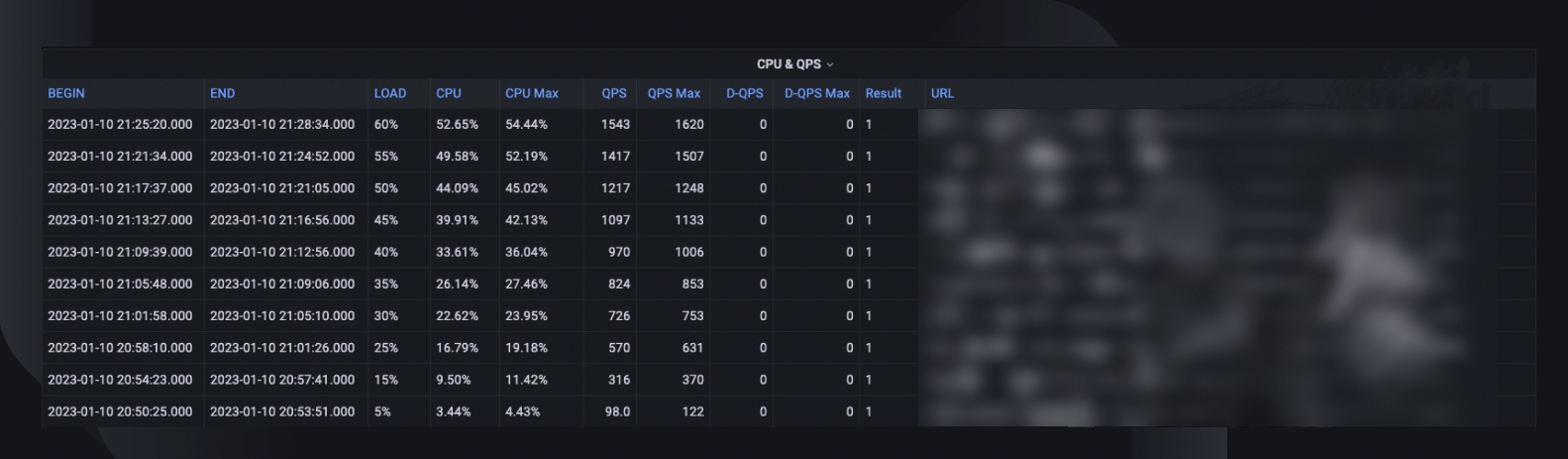
Um resumo geral do teste captura a porcentagem máxima de carga que o host foi capaz de suportar, o pico de uso da CPU e o QPS do host. Com base nisso, ele também estima a contagem de instâncias que poderemos precisar implantar para atender à nossa reserva de capacidade, considerando o QPS mais alto de todos os tempos dos serviços.
Outras informações valiosas para análise incluem a versão do software, especificações do servidor, contagem de implantações e um link para o painel do monitor, onde podemos relembrar o que aconteceu durante o teste.

Uma curva de benchmark indica como o desempenho mudou nos últimos três meses para que possamos descobrir possíveis problemas relacionados a um lançamento de aplicativo específico.

As tendências de CPU e QPS mostram como o uso da CPU se correlacionou com o volume de solicitações que o servidor teve que lidar. Essa métrica pode ajudar a estimar a capacidade do servidor para o crescimento do tráfego de entrada.
O comportamento da latência da API captura como o tempo de resposta varia sob diferentes condições de carga para as cinco principais APIs. Podemos então otimizar o sistema, se necessário, em um nível de API individual.

As métricas de distribuição de carga da API nos ajudam a entender como a composição da API afeta o desempenho do serviço e fornecem mais insights sobre áreas de melhoria.
Normalização e produtização
À medida que nosso sistema continua a crescer e evoluir, continuaremos monitorando e melhorando a estabilidade e a confiabilidade do serviço. Continuaremos isso através de:
Um cronograma regular e estabelecido de testes de carga para serviços críticos.
Testes de carga automáticos como parte de nossos pipelines de CI/CD.
Aumento da produção de toda a solução para preparar a adoção em larga escala em toda a organização.
Limitações
Existem algumas limitações na abordagem atual de teste de carga:
O roteamento baseado em FlowFlag só é aplicável à nossa estrutura de microsserviços. Queremos expandir a solução para mais cenários de roteamento, aproveitando o recurso de roteamento ponderado comum dos balanceadores de carga em nuvem ou do Kubernetes Ingress.
Como baseamos o teste no tráfego real de usuários em produção, não podemos realizar testes de recursos em APIs ou casos de uso específicos. Além disso, para serviços com volume muito baixo, o valor seria limitado, pois talvez não consigamos identificar o seu gargalo.
Realizamos esses testes em serviços individuais, em vez de cobrir cadeias de chamadas de ponta a ponta.
Às vezes, os testes em produção podem impactar usuários reais se ocorrerem falhas. Portanto, devemos ter análise de falhas e reversão automática com recursos completos de automação.
Considerações finais
É fundamental pensarmos em cenários de pico de tráfego para evitar a sobrecarga do sistema e garantir seu tempo de atividade. É por isso que criamos os processos de gerenciamento de capacidade e teste de carga descritos neste artigo. Para resumir:
Nosso gerenciamento de capacidade é orientado para picos e integrado em todos os estágios do ciclo de vida do serviço, evitando sobrecarga com atividades como medição, definição de prioridade, alertas e relatórios de capacidade, etc. Em última análise, é isso que torna os processos e necessidades da Binance únicos em comparação com uma situação típica de gerenciamento de capacidade. .
O benchmark de serviço obtido nos testes de carga é o ponto focal do gerenciamento e planejamento da capacidade. Ele determina com precisão os recursos de infraestrutura necessários para dar suporte às demandas comerciais atuais e futuras. Em última análise, isso teve que ser realizado em produção com uma solução exclusiva construída pela Binance que nos permitisse atender às nossas necessidades específicas.
Com tudo isso junto, esperamos que você veja que um bom planejamento e estruturas completas ajudam a criar o serviço que os Binancianos conhecem e apreciam.
Referências
Dominic Ogbonna, A-Z de Gerenciamento de Capacidade: Guia Prático para Implementação de Monitoramento de TI Empresarial e Planejamento de Capacidade, Capítulo 4, Capítulo 6
Luis Quesada Torres, Doug Colish, SRE Melhores Práticas para Gerenciamento de Capacidade
Alejandro Forero Cuervo, Sarah Chavis, livro Google SRE, Capítulo 21 - Manipulação de sobrecarga
Leitura adicional
(Blog) Como a Binance Ledger potencializa sua experiência na Binance
(Blog) Apresentando Binance Oracle VRF: a próxima geração de aleatoriedade verificável
(Blog) Binance se junta à FIDO Alliance em preparação para implementação de senha