
Autor original: YBB Capital Zeke

Prefácio
Em 16 de fevereiro, a OpenAI anunciou o mais recente modelo de difusão de geração de vídeo controlado por texto "Sora", que demonstrou outro marco na IA generativa por meio de vários vídeos gerados de alta qualidade cobrindo uma ampla gama de tipos de dados visuais. Ao contrário das ferramentas de geração de vídeo de IA, como o Pika, que ainda estão no estado de geração de alguns segundos de vídeo a partir de múltiplas imagens, Sora consegue geração de vídeo escalonável treinando no espaço latente comprimido de vídeos e imagens, decompondo-os em manchas de posição espaço-temporal. Além disso, o modelo também reflete a capacidade de simular o mundo físico e o mundo digital. A demonstração de 60 segundos finalmente apresentada não é exagero para dizer que se trata de um “simulador universal do mundo físico”.
Em termos de método de construção, Sora continua o caminho técnico de "fonte de dados-transformador-difusão-emergência" do modelo GPT anterior, o que significa que seu desenvolvimento maduro também requer poder de computação como motor, e porque a quantidade de dados necessária para o treinamento em vídeo é muito maior que o texto. A quantidade de dados de treinamento aumentará ainda mais a demanda por poder de computação. No entanto, já discutimos a importância do poder computacional na era da IA em nosso artigo anterior (Prévia do curso potencial: Mercado de poder computacional descentralizado), e com o recente aumento na popularidade da IA, já existe um grande número de projetos de potência computacional no mercado começaram a surgir, e outros projetos Depin (armazenamento, potência computacional, etc.) que se beneficiaram passivamente também experimentaram um aumento. Então, além do Depin, com que tipo de faíscas a interseção da Web3 e da IA pode colidir? Que outras oportunidades esta faixa contém? O principal objetivo deste artigo é atualizar e completar os artigos anteriores, e pensar nas possibilidades da Web3 na era da IA.
Três direções principais na história do desenvolvimento da IA
Inteligência Artificial (Inteligência Artificial) é uma ciência e tecnologia emergente projetada para simular, expandir e aprimorar a inteligência humana. Desde o seu nascimento nas décadas de 1950 e 1960, a inteligência artificial passou por mais de meio século de desenvolvimento e agora se tornou uma importante tecnologia que promove mudanças na vida social e em todas as esferas da vida. Neste processo, o desenvolvimento interligado das três principais direções de investigação do simbolismo, do conexionismo e do behaviorismo tornou-se a pedra angular do rápido desenvolvimento da IA hoje.
Simbolismo
Também conhecido como logicismo ou regularismo, é a crença de que é possível simular a inteligência humana através do processamento de símbolos. Este método utiliza símbolos para representar e operar objetos, conceitos e suas inter-relações no domínio do problema, e utiliza raciocínio lógico para resolver problemas, especialmente em sistemas especialistas e representação de conhecimento, que tem alcançado resultados notáveis. A ideia central do simbolismo é que o comportamento inteligente pode ser alcançado através da operação de símbolos e do raciocínio lógico, onde os símbolos representam um alto grau de abstração do mundo real;
Conexionismo
Ou chamado de método de rede neural, visa alcançar inteligência imitando a estrutura e função do cérebro humano. Este método alcança o aprendizado construindo uma rede de muitas unidades de processamento simples (semelhantes aos neurônios) e ajustando a força das conexões entre essas unidades (semelhantes às sinapses). O conexionismo enfatiza particularmente a capacidade de aprender e generalizar a partir de dados e é particularmente adequado para problemas de reconhecimento de padrões, classificação e mapeamento contínuo de entradas-saídas. A aprendizagem profunda, como desenvolvimento do conexionismo, fez avanços em áreas como reconhecimento de imagem, reconhecimento de fala e processamento de linguagem natural;
Behaviorismo
O Behaviorismo está intimamente relacionado com a pesquisa da robótica biônica e de sistemas inteligentes autônomos, enfatizando que os agentes inteligentes podem aprender através da interação com o meio ambiente. Ao contrário dos dois primeiros, o behaviorismo não se concentra na simulação de representações internas ou processos de pensamento, mas sim na obtenção de um comportamento adaptativo através de ciclos de percepção e ação. O Behaviorismo acredita que a inteligência é demonstrada através da interação dinâmica e da aprendizagem com o ambiente. Este método é particularmente eficaz quando aplicado a robôs móveis e sistemas de controle adaptativos que precisam atuar em ambientes complexos e imprevisíveis.
Embora existam diferenças essenciais entre essas três direções de pesquisa, na pesquisa e aplicações reais de IA, elas também podem interagir e integrar-se para promover conjuntamente o desenvolvimento do campo de IA.
Visão geral do princípio AIGC
A IA generativa (Conteúdo Gerado por Inteligência Artificial, AIGC), que está atualmente em desenvolvimento explosivo, é uma evolução e aplicação do conexionismo que pode imitar a criatividade humana para gerar novos conteúdos. Esses modelos são treinados usando grandes conjuntos de dados e algoritmos de aprendizado profundo para aprender as estruturas, relacionamentos e padrões subjacentes presentes nos dados. Gere resultados novos e exclusivos com base nas solicitações de entrada do usuário, incluindo imagens, vídeos, código, música, designs, traduções, respostas a perguntas e texto. O AIGC atual é composto basicamente por três elementos: Deep Learning (DL), big data e poder computacional em larga escala.
aprendizagem profunda
O aprendizado profundo é um subcampo do aprendizado de máquina (ML), e os algoritmos de aprendizado profundo são redes neurais modeladas a partir do cérebro humano. Por exemplo, o cérebro humano contém milhões de neurônios interconectados que trabalham juntos para aprender e processar informações. Da mesma forma, as redes neurais de aprendizagem profunda (ou redes neurais artificiais) são compostas por múltiplas camadas de neurônios artificiais trabalhando juntas dentro de um computador. Neurônios artificiais são módulos de software chamados nós que usam cálculos matemáticos para processar dados. Redes neurais artificiais são algoritmos de aprendizado profundo que usam esses nós para resolver problemas complexos.
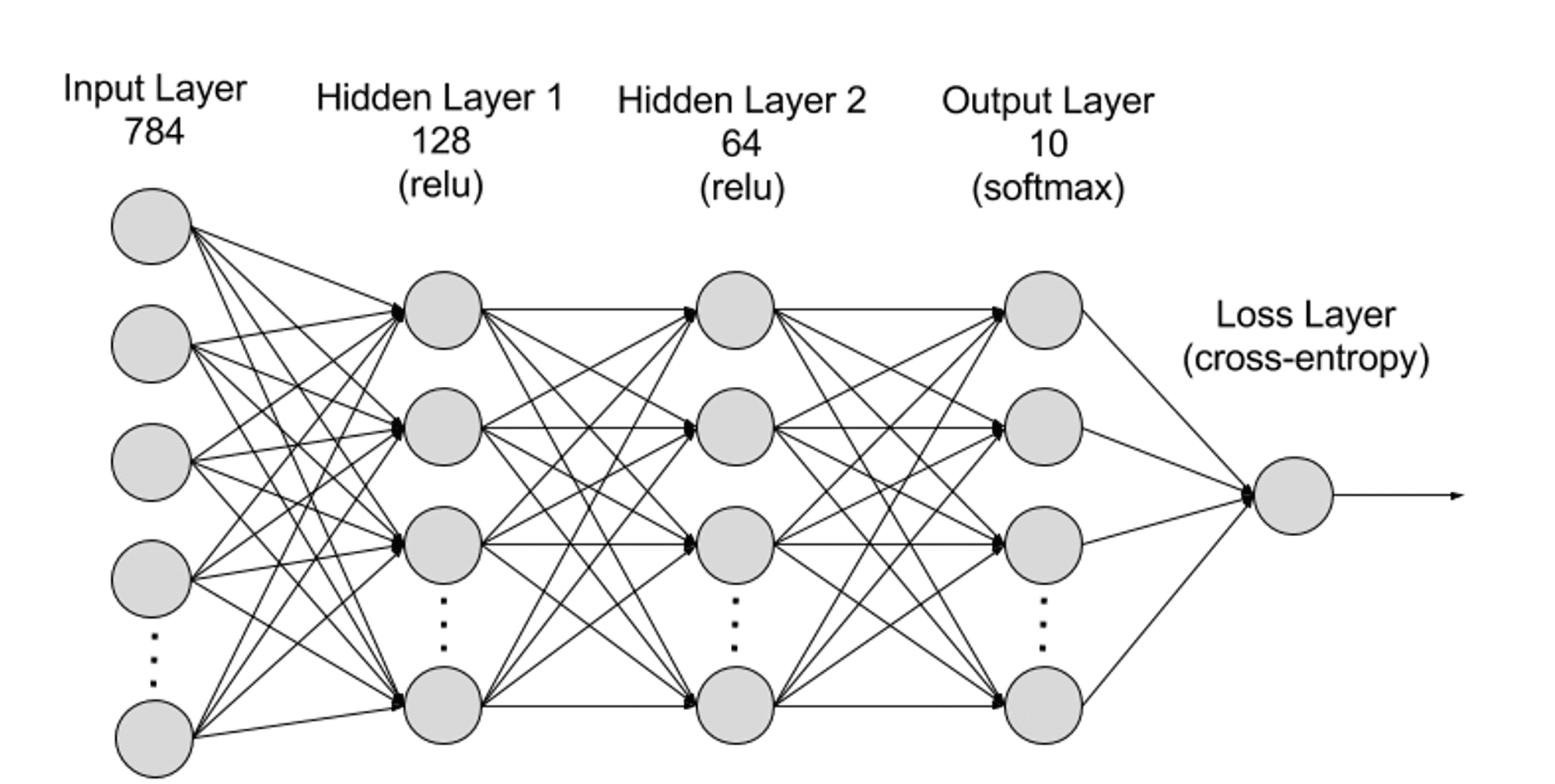
As redes neurais podem ser divididas hierarquicamente em camadas de entrada, camadas ocultas e camadas de saída, e as conexões entre as diferentes camadas são parâmetros.
Camada de entrada: A camada de entrada é a primeira camada da rede neural e é responsável por receber dados de entrada externos. Cada neurônio na camada de entrada corresponde a uma característica dos dados de entrada. Por exemplo, ao processar dados de imagem, cada neurônio pode corresponder a um valor de pixel na imagem;
Camada oculta: a camada de entrada processa os dados e os passa para outras camadas da rede neural. Essas camadas ocultas processam informações em diferentes níveis, ajustando seu comportamento à medida que recebem novas informações. As redes de aprendizagem profunda têm centenas de camadas ocultas e podem ser usadas para analisar problemas de muitas perspectivas diferentes. Por exemplo, se você receber a imagem de um animal desconhecido que deve classificar, poderá compará-lo com animais que já conhece. Por exemplo, você pode dizer que tipo de animal é pelo formato de suas orelhas, pelo número de patas e pelo tamanho de suas pupilas. As camadas ocultas em redes neurais profundas funcionam da mesma maneira. Se um algoritmo de aprendizagem profunda estiver tentando classificar a imagem de um animal, cada uma de suas camadas ocultas processará uma característica diferente do animal e tentará classificá-la com precisão;
Camada de Saída: A camada de saída é a última camada da rede neural e é responsável por gerar a saída da rede. Cada neurônio na camada de saída representa uma possível categoria ou valor de saída. Por exemplo, num problema de classificação, cada neurónio da camada de saída pode corresponder a uma categoria, enquanto num problema de regressão, a camada de saída pode ter apenas um neurónio cujo valor representa o resultado da predição;
Parâmetros: Nas redes neurais, as conexões entre as diferentes camadas são representadas por parâmetros de pesos e vieses, que são otimizados durante o processo de treinamento para permitir que a rede identifique com precisão padrões nos dados e faça previsões. O aumento dos parâmetros pode melhorar a capacidade do modelo da rede neural, ou seja, a capacidade do modelo de aprender e representar padrões complexos nos dados. Mas, correspondentemente, o aumento dos parâmetros aumentará a demanda por poder computacional.
grandes dados
Para serem treinadas de forma eficaz, as redes neurais geralmente requerem grandes quantidades de dados diversos e de alta qualidade de múltiplas fontes. É a base para o treinamento e validação do modelo de aprendizado de máquina. Ao analisar big data, os modelos de aprendizado de máquina podem aprender padrões e relacionamentos nos dados para fazer previsões ou classificações.
Poder de computação em grande escala
A estrutura complexa multicamadas da rede neural, um grande número de parâmetros, requisitos de processamento de big data e métodos de treinamento iterativos (na fase de treinamento, o modelo precisa ser iterado repetidamente, e durante o processo de treinamento, propagação para frente e para trás propagação são necessários para cada cálculo de camada, incluindo o cálculo da função de ativação, cálculo da função de perda, cálculo de gradiente e atualização de peso), requisitos de cálculo de alta precisão, capacidades de computação paralela, técnicas de otimização e regularização e processos de avaliação e verificação de modelo levam em conjunto ao seu demanda por alto poder de computação.

Sora
Como o modelo de IA de última geração de vídeo lançado pela OpenAI, Sora representa um enorme avanço na capacidade da inteligência artificial de processar e compreender diversos dados visuais. Ao usar rede de compressão de vídeo e tecnologia de correção espaço-temporal, Sora é capaz de converter dados visuais massivos capturados por diferentes dispositivos de todo o mundo em uma representação unificada, alcançando assim processamento e compreensão eficientes de conteúdo visual complexo. Baseando-se no modelo de Difusão condicionado por texto, Sora pode gerar vídeos ou imagens altamente correspondentes com base em instruções de texto, mostrando criatividade e adaptabilidade extremamente altas.
No entanto, embora Sora tenha feito avanços na geração de vídeos e na simulação de interações do mundo real, ele ainda enfrenta algumas limitações, incluindo a precisão da simulação do mundo físico, a consistência da geração de vídeos longos, a compreensão de instruções de texto complexas e o treinamento e a eficiência de geração. E Sora essencialmente alcança uma estética violenta através do antigo caminho tecnológico de "Big Data-Transformer-Diffusion-Emergency" através do poder de computação em nível de monopólio da OpenAI e da vantagem de ser o pioneiro. Outras empresas de IA ainda têm que passar por desvios técnicos. .
Embora Sora não tenha muito a ver com blockchain, pessoalmente acho que nos próximos um ou dois anos. Como a influência do Sora forçará outras ferramentas de geração de IA de alta qualidade a emergirem e se desenvolverem rapidamente, e se irradiará para muitas faixas, como GameFi, redes sociais, plataformas de criação e Depin dentro da Web3, é necessário ter uma compreensão geral de Sora. Como a IA será efetivamente combinada com a Web3 no futuro pode ser um ponto-chave que precisamos pensar.
Quatro caminhos principais de AI x Web3
Como mencionado acima, podemos saber que a base subjacente necessária para a IA generativa consiste, na verdade, em apenas três pontos: algoritmo, dados e poder computacional. Por outro lado, do ponto de vista da versatilidade e dos efeitos de geração, a IA é uma ferramenta que subverte o. modo de produção. O maior papel do blockchain é duplo: reconstrução das relações de produção e descentralização. Portanto, pessoalmente acho que existem quatro caminhos que podem ser gerados pela colisão dos dois:
Poder de computação descentralizado
Como artigos relacionados foram escritos no passado, o objetivo principal deste parágrafo é atualizar o status atual da faixa de potência computacional. Quando se trata de IA, o poder computacional é sempre um fator inevitável. A demanda da IA por poder computacional é tão grande que era inimaginável após o nascimento de Sora. Recentemente, durante o Fórum Económico Mundial de 2024 em Davos, Suíça, o CEO da OpenAI, Sam Altman, afirmou sem rodeios que o poder e a energia da computação são os maiores grilhões nesta fase, e a sua importância no futuro será até igual à moeda. Em 10 de Fevereiro, Sam Altman anunciou um plano extremamente surpreendente no Twitter para angariar 7 biliões de dólares (equivalente a 40% do PIB nacional da China em 2023) para reescrever o actual padrão global da indústria de semicondutores. Ao escrever artigos relacionados ao poder da computação, minha imaginação ainda estava limitada a bloqueios nacionais e monopólios gigantescos. Hoje em dia, é uma loucura que uma empresa queira controlar a indústria global de semicondutores.
Portanto, a importância do poder computacional descentralizado é evidente. As características do blockchain podem de fato resolver o problema atual do monopólio extremo do poder computacional e da compra cara de GPUs dedicadas. Do ponto de vista do que a IA exige, o uso do poder da computação pode ser dividido em duas direções: inferência e treinamento. Atualmente, existem apenas alguns projetos com foco no treinamento, desde a necessidade de redes descentralizadas até a combinação com o design de redes neurais. a necessidade de ultra-hardware A alta demanda está destinada a ser uma direção com limites extremamente altos e extremamente difíceis de implementar. O raciocínio é relativamente simples. Por um lado, o design da rede descentralizada não é complicado e, por outro lado, os requisitos de hardware e largura de banda são baixos, o que é considerado uma direção relativamente comum no momento.
O espaço de imaginação do mercado centralizado de poder de computação é enorme e está frequentemente associado à palavra-chave “nível de trilhão”. É também o tópico mais comentado na era da IA. No entanto, a julgar pelo grande número de projetos que surgiram recentemente, a maioria deles ainda está correndo para as prateleiras para ganhar popularidade. Sempre erguendo bem alto a bandeira correta da descentralização, mas mantendo silêncio sobre a ineficiência das redes descentralizadas. E há um alto grau de homogeneidade no design. Um grande número de projetos são muito semelhantes (L2 com um clique mais design de mineração), o que pode eventualmente levar a uma situação em que é realmente difícil obter uma parte da trilha tradicional de IA. .
Algoritmo e sistema de colaboração de modelo
Algoritmos de aprendizado de máquina referem-se a esses algoritmos que podem aprender regras e padrões a partir de dados e fazer previsões ou decisões com base neles. Os algoritmos exigem muita tecnologia porque seu design e otimização exigem profundo conhecimento e inovação tecnológica. Os algoritmos são o núcleo do treinamento de modelos de IA e definem como os dados são transformados em insights ou decisões úteis. Os algoritmos de IA generativos mais comuns, como Generative Adversarial Network (GAN), Variational Autoencoder (VAE) e Transformer, são projetados para um campo específico (como pintura, reconhecimento de linguagem, tradução e geração de vídeo) ou em outras palavras. , nasce com base no propósito e, em seguida, um modelo de IA dedicado é treinado por meio do algoritmo.
Portanto, existem tantos algoritmos e modelos, cada um com os seus próprios méritos. Podemos integrá-los num modelo que pode ser tanto civil como militar? O Bittensor, que se tornou muito popular recentemente, é líder nessa direção. Ele usa incentivos de mineração para permitir que diferentes modelos e algoritmos de IA colaborem e aprendam uns com os outros, criando assim modelos de IA mais eficientes e versáteis. Também focando nessa direção estão a Commune AI (colaboração de código), etc. No entanto, para as empresas atuais de IA, algoritmos e modelos são suas próprias armas mágicas e não serão emprestados à vontade.
Portanto, a narrativa da ecologia colaborativa de IA é muito nova e interessante. O ecossistema colaborativo aproveita o blockchain para integrar as desvantagens da ilha de algoritmos de IA, mas ainda não se sabe se pode criar valor correspondente. Afinal, os algoritmos e modelos de código fechado das principais empresas de IA têm uma capacidade muito forte de atualização, iteração e integração. Por exemplo, em menos de dois anos de desenvolvimento, o OpenAI iterou dos primeiros modelos de geração de texto para modelos gerados em vários campos. Projetos como o Bittensor fizeram grandes progressos em modelos e algoritmos. As áreas visadas podem exigir novas abordagens.
Big data descentralizado
De uma perspectiva simples, usar dados privados para alimentar IA e rotular dados são instruções muito consistentes com o blockchain. Você só precisa prestar atenção em como evitar dados indesejados e maldades, e o armazenamento de dados também pode usar FIL, AR Espere por. o projeto Depin se beneficiará. De uma perspectiva complexa, o uso de dados blockchain para aprendizado de máquina (ML) para resolver a acessibilidade dos dados blockchain também é uma direção interessante (uma das direções de exploração de Gizé).
Em teoria, os dados da blockchain podem ser acessados a qualquer momento e refletem o status de toda a blockchain. Mas para quem está fora do ecossistema blockchain, acessar essas enormes quantidades de dados não é fácil. Armazenar um blockchain em sua totalidade requer amplo conhecimento e uma grande quantidade de recursos de hardware dedicados. Para superar os desafios de acesso a dados blockchain, diversas soluções surgiram na indústria. Por exemplo, os provedores de RPC acessam nós por meio de APIs, enquanto os serviços de indexação possibilitam a extração de dados por meio de SQL e GraphQL, ambos desempenhando um papel fundamental na solução do problema. No entanto, esses métodos têm limitações. Os serviços RPC não são adequados para cenários de uso de alta densidade que exigem grandes quantidades de consulta de dados e muitas vezes não atendem à demanda. Ao mesmo tempo, embora o serviço de indexação forneça uma forma mais estruturada de recuperação de dados, a complexidade do protocolo Web3 torna extremamente difícil a construção de consultas eficientes, às vezes exigindo a escrita de centenas ou mesmo milhares de linhas de código complexo. Essa complexidade é um enorme obstáculo para os profissionais de dados em geral e para aqueles que não entendem profundamente os detalhes da Web3. O efeito cumulativo dessas limitações destaca a necessidade de uma maneira mais fácil de obter e utilizar dados de blockchain que possam promover uma adoção e inovação mais amplas na área.
Então, combinando dados de blockchain de alta qualidade com ZKML (aprendizado de máquina à prova de conhecimento zero, reduzindo a carga de aprendizado de máquina na cadeia), pode ser possível criar um conjunto de dados que resolva o problema de acessibilidade do blockchain, e a IA pode significativamente reduzir o custo do limite de blockchain para acessibilidade de dados, para que, com o tempo, desenvolvedores, pesquisadores e entusiastas na área de ML possam acessar mais conjuntos de dados relevantes e de alta qualidade para construir soluções eficazes e inovadoras.
Dapp com IA
Desde que o ChatGPT 3 se tornou popular em 2023, o Dapp com tecnologia de IA se tornou uma direção muito comum. A IA generativa extremamente versátil pode ser acessada por meio de API, simplificando e analisando de forma inteligente plataformas de dados, robôs de negociação, enciclopédias blockchain e outras aplicações. Por outro lado, você também pode atuar como um chatbot (como Myshell) ou um companheiro de IA (Sleepless AI), ou até mesmo criar NPCs em jogos em cadeia por meio de IA generativa. Porém, como as barreiras técnicas são muito baixas, a maioria delas é ajustada após o acesso a uma API, e a integração com o projeto em si não é perfeita, por isso raramente é mencionada.
Mas após a chegada de Sora, eu pessoalmente acho que a direção da IA que fortalece a GameFi (incluindo o Metaverso) e a plataforma criativa será o foco da próxima etapa. Devido à natureza ascendente do campo Web3, será definitivamente difícil produzir produtos que concorram com jogos tradicionais ou empresas criativas, e o surgimento do Sora provavelmente quebrará esse dilema (talvez em apenas dois ou três anos). A julgar pela demonstração de Sora, ela já tem potencial para competir com empresas de micro-curtas-metragens. A cultura comunitária ativa da Web3 também pode dar origem a um grande número de ideias interessantes. Quando a restrição é apenas a imaginação, a indústria de baixo para cima. As barreiras de cima para baixo entre as indústrias tradicionais serão derrubadas.
Conclusão
À medida que as ferramentas generativas de IA continuam a avançar, experimentaremos mais “momentos iPhone” que marcarão época no futuro. Embora muitas pessoas zombem da combinação de IA e Web3, na verdade, acho que não há problemas com a direção atual. Na verdade, existem apenas três pontos problemáticos que precisam ser resolvidos: necessidade, eficiência e adequação. Embora a integração dos dois esteja em fase exploratória, isso não impede que esta pista se torne a corrente principal do próximo mercado altista.
Manter sempre a curiosidade e a aceitação por coisas novas é uma mentalidade obrigatória para nós. Historicamente, a mudança de carros para substituir as carruagens puxadas por cavalos tornou-se uma conclusão precipitada. Assim como as inscrições e os NFTs no passado, existem. muitos preconceitos. Você apenas perderá a oportunidade.