
O GPT-4 alcançou pontuações mais altas do que o GPT-3.5 em vários benchmarks. Este é um grande avanço para as máquinas, pois prova que agora elas podem não apenas resolver problemas para os quais foram originalmente projetadas, mas também podem fazê-lo melhor do que os estudantes universitários.

Há algumas coisas a serem levadas em consideração ao analisar esse resultado. Primeiramente, o GPT-4 não recebeu nenhum treinamento específico para esses exames. Prosseguiu usando os testes mais recentes disponíveis ao público (no caso das Olimpíadas e perguntas de resposta gratuita de AP) ou comprando as edições de exames práticos de 2022–2023. Em segundo lugar, é importante notar que o desempenho do GPT-4 pode não refletir necessariamente as capacidades dos candidatos humanos, uma vez que funciona com base num conjunto diferente de princípios e algoritmos.
Esta é uma grande conquista, pois mostra que as máquinas não só são capazes de ter uma inteligência semelhante à humana, mas também podem superar-nos. Isto abre caminho para um futuro onde as máquinas possam assumir tarefas cada vez mais complexas, conduzindo, em última análise, a um futuro em que possam ajudar-nos na nossa vida quotidiana.
 A capacidade do GPT-4 de superar os humanos em determinadas tarefas levanta questões sobre o futuro da inteligência artificial e o seu potencial impacto no mercado de trabalho. Destaca também a necessidade de investigação e desenvolvimento contínuos neste domínio para garantir que a IA seja utilizada de forma ética e responsável. Leia mais: Mais de 5 modelos de IA de texto para imagem mais esperados de 2023
A capacidade do GPT-4 de superar os humanos em determinadas tarefas levanta questões sobre o futuro da inteligência artificial e o seu potencial impacto no mercado de trabalho. Destaca também a necessidade de investigação e desenvolvimento contínuos neste domínio para garantir que a IA seja utilizada de forma ética e responsável. Leia mais: Mais de 5 modelos de IA de texto para imagem mais esperados de 2023
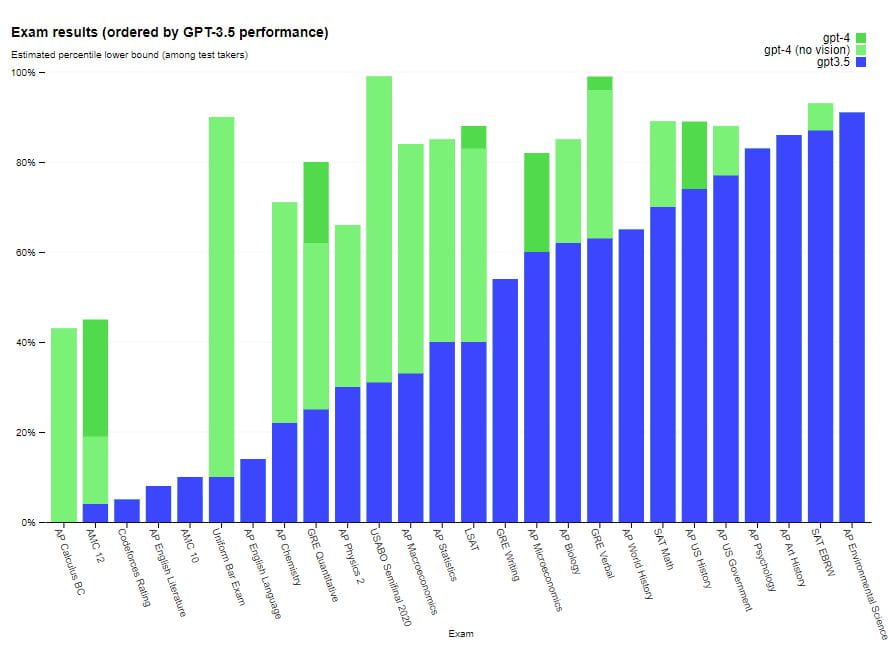
GPT-4, por exemplo, passa em um exame simulado da ordem com uma pontuação entre os 10% melhores participantes do teste; A pontuação do GPT-3.5 ficou entre os 10% inferiores. Esta melhoria significativa no desempenho do GPT-4 se deve aos seus maiores dados de treinamento e arquitetura aprimorada. Espera-se que tenha uma ampla gama de aplicações em vários campos, incluindo processamento de linguagem natural e escrita automatizada.
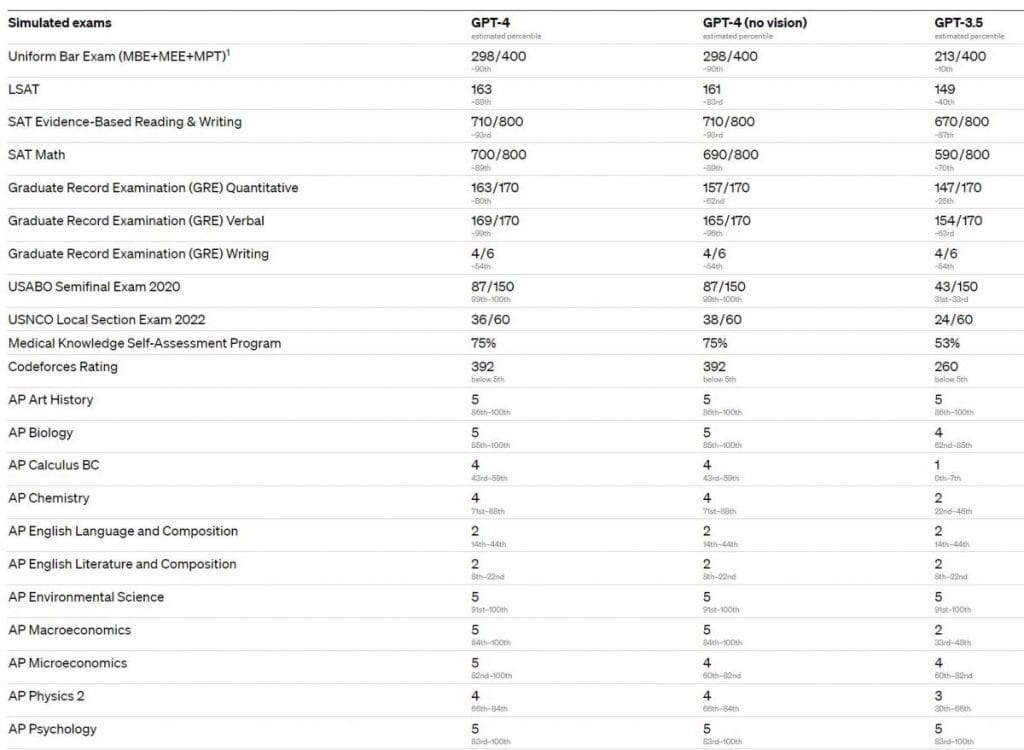 O GPT-4 apresenta desempenho de nível humano na maioria desses exames profissionais e acadêmicos. Notavelmente, ele passou em uma versão simulada do Uniform Bar Examination com uma pontuação entre os 10% melhores participantes do teste. As capacidades do modelo nos exames parecem resultar principalmente do processo de pré-formação e não são significativamente afetadas pelo RLHF. Em questões de múltipla escolha, tanto o modelo básico GPT-4 quanto o modelo RLHF tiveram desempenho médio igualmente bom entre os desenvolvedores do exame testado.
O GPT-4 apresenta desempenho de nível humano na maioria desses exames profissionais e acadêmicos. Notavelmente, ele passou em uma versão simulada do Uniform Bar Examination com uma pontuação entre os 10% melhores participantes do teste. As capacidades do modelo nos exames parecem resultar principalmente do processo de pré-formação e não são significativamente afetadas pelo RLHF. Em questões de múltipla escolha, tanto o modelo básico GPT-4 quanto o modelo RLHF tiveram desempenho médio igualmente bom entre os desenvolvedores do exame testado.
A maioria dos modelos de última geração (SOTA), incluindo aqueles que podem usar protocolos de treinamento adicionais ou design específico de benchmark, bem como modelos de grande linguagem existentes, são significativamente superados pelo GPT-4.
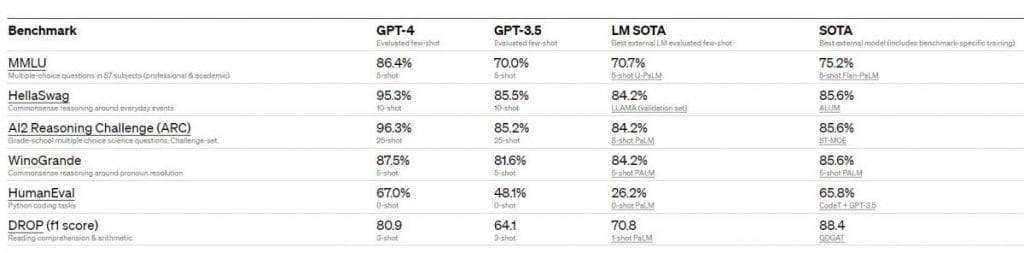 Desempenho do GPT-4 em termos de padrões acadêmicos. Os desenvolvedores comparam o GPT-4 com o melhor SOTA para poucas fotos avaliadas por LM, bem como o melhor SOTA com treinamento específico de benchmark. Com exceção do DROP, o GPT-4 supera todos os LMs atuais em todos os benchmarks e SOTA com treinamento específico de benchmark.
Desempenho do GPT-4 em termos de padrões acadêmicos. Os desenvolvedores comparam o GPT-4 com o melhor SOTA para poucas fotos avaliadas por LM, bem como o melhor SOTA com treinamento específico de benchmark. Com exceção do DROP, o GPT-4 supera todos os LMs atuais em todos os benchmarks e SOTA com treinamento específico de benchmark.
Internamente, os desenvolvedores têm utilizado o GPT-4, que teve um impacto significativo em atividades como programação, vendas, suporte e moderação de conteúdo. A segunda etapa do nosso método de alinhamento está em andamento, à medida que os desenvolvedores o utilizam para ajudar os humanos na revisão dos resultados da IA.
O conjunto de dados MMLU (Massive Multi-Task Language Understanding) contém perguntas de uma ampla variedade de tópicos sobre compreensão de linguagem em diferentes tarefas (abrangendo 57 domínios, incluindo matemática, biologia, direito, ciências sociais e humanas, etc.). Existem quatro respostas possíveis para a pergunta, uma das quais está correta. Ou seja, a adivinhação aleatória mostra um resultado de 25% de respostas corretas. Veja na imagem abaixo exemplos de dúvidas e suas dificuldades. O marcador pessoal médio (isto é, não é um cientista, nem um professor — uma pessoa comum que trabalha como marcação) responde corretamente a 35% das perguntas; no entanto, os especialistas podem atingir uma pontuação de +/- 90%.
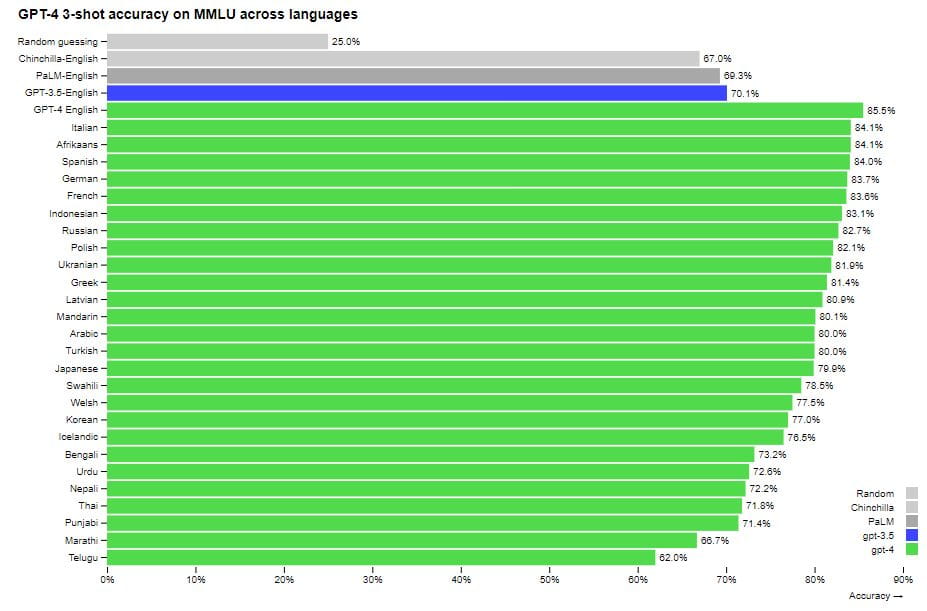 Desempenho do GPT-4 em vários idiomas em comparação com modelos anteriores em inglês no MMLU. O GPT-4 excede o desempenho da língua inglesa dos modelos linguísticos existentes para a grande maioria das línguas examinadas, incluindo línguas de poucos recursos, como o letão, o galês e o suaíli. Leia mais: 5 razões para usar o Bing com tecnologia de IA em vez do Google
Desempenho do GPT-4 em vários idiomas em comparação com modelos anteriores em inglês no MMLU. O GPT-4 excede o desempenho da língua inglesa dos modelos linguísticos existentes para a grande maioria das línguas examinadas, incluindo línguas de poucos recursos, como o letão, o galês e o suaíli. Leia mais: 5 razões para usar o Bing com tecnologia de IA em vez do Google
Originalmente, todo o conjunto de dados estava em inglês. Mas e se as perguntas e respostas forem traduzidas para outros idiomas, especialmente os menos comuns? O modelo funcionará para eles de alguma forma? Neste teste, o serviço Microsoft Azure Translate foi utilizado para tradução. As traduções não são perfeitas; em alguns casos, informações importantes são perdidas. Porém, mesmo neste caso, o GPT-4 tem um bom desempenho em outros idiomas. Nas versões traduzidas do MMLU, o GPT-4 supera o nível de inglês de outros grandes modelos (incluindo o do Google) em 24 dos 26 idiomas examinados.
Além do mais, o GPT-4 tem um desempenho melhor em idiomas raros do que o ChatGPT em inglês (o ChatGPT alcançou uma pontuação de 70,1%, enquanto a pontuação do novo modelo para o tailandês foi de 71,8%). A pontuação do teste em inglês foi a mais alta, com o GPT-4 tendo um desempenho 10% melhor que outros modelos, incluindo o maior PaLM do Google. Alcançou uma pontuação de 86,4%, enquanto um grupo de especialistas – 90%.
No verão de 2023, a IA poderá ter alcançado um novo nível de poder graças ao ChatGPT, um chatbot que usa o algoritmo GPT-4 e supera o GPT-3 por um fator de 570. Uma variedade de elementos contribuem para o sucesso do ChatGPT, incluindo seu design para ser mais “humano” e seu uso de mineração de dados de ponta e processamento de linguagem natural para aumentar sua eficácia e precisão.
Microsoft e OpenAI anunciaram sua renovação de colaboração e planos para que a pesquisa do Bing adote recursos de pesquisa aprimorados por IA em janeiro. O substituto muito sofisticado do modelo GPT3.5, GPT4, acaba de ser lançado e tem o potencial de melhorar significativamente a capacidade da pesquisa do Bing de compreender consultas em linguagem natural e fornecer resultados mais precisos. É uma boa ideia ter um bom plano de backup caso algo dê errado.
Leia mais notícias relacionadas:
Conheça ChatGPT: a IA que pode matar o Google
ChatGPT passa no exame de MBA da Wharton
A evolução dos chatbots da era T9 e GPT-1 para ChatGPT
A postagem GPT-4 supera GPT-3.5 em toda a linha em uma variedade de benchmarks de estudo apareceu pela primeira vez no Metaverse Post.