
O 3D Avatar Diffusion é um algoritmo de aprendizado de máquina que pode capturar uma única imagem 2D de um rosto humano e criar um avatar tridimensional (3D). O avatar pode então ser usado para criar uma experiência de realidade virtual (VR) ou realidade aumentada (AR) ou simplesmente fornecer uma visão 3D realista da pessoa para jogos ou outros fins.
O modelo de difusão foi desenvolvido por uma equipe de pesquisadores da Microsoft Research e é descrito em artigo publicado na revista arXiv.

O 3D Avatar Diffusion é baseado em um tipo de algoritmo de aprendizado de máquina denominado modelo de difusão. Os modelos de difusão são modelos generativos, o que significa que podem gerar novos dados semelhantes aos dados de treinamento. Modelos de difusão já foram usados para gerar imagens 3D a partir de imagens 2D, mas o ADM é o primeiro modelo de difusão que pode gerar um avatar 3D realista a partir de uma única imagem 2D.
Para treinar o modelo, os pesquisadores usaram um conjunto de dados de mais de 200 mil modelos faciais 3D. O conjunto de dados incluiu uma grande variedade de rostos com diferentes tons de pele, estilos de cabelo e características faciais. O ADM foi então capaz de aprender a relação entre a imagem 2D e o modelo facial 3D e gerar um avatar 3D realista a partir de uma única imagem 2D.
O modelo também pode ser usado para gerar um avatar a partir de uma foto tirada de um ângulo diferente
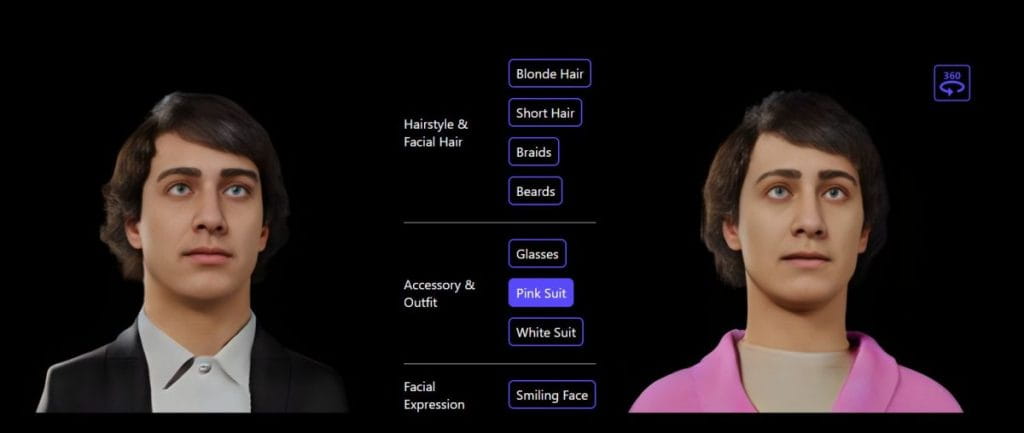 Para o avatar 3D personalizado, o modelo Rodin oferece manipulação guiada por texto. A edição em linguagem natural é uma maneira intuitiva de alterar muitos recursos diferentes do avatar 3D.
Para o avatar 3D personalizado, o modelo Rodin oferece manipulação guiada por texto. A edição em linguagem natural é uma maneira intuitiva de alterar muitos recursos diferentes do avatar 3D.
Este estudo propõe um modelo generativo 3D que cria automaticamente avatares digitais 3D que são representados como campos de radiação neural usando modelos de difusão. Devido aos requisitos proibitivos de memória e processamento associados ao 3D, criar os recursos avançados necessários para avatares de alta qualidade é um grande problema. Os desenvolvedores sugerem que a rede de difusão roll-out (Rodin) resolva esse problema.
 Em termos de gênero, idade, raça, expressão, acessórios faciais, etc., o modelo apresenta notável diversidade geracional.
Em termos de gênero, idade, raça, expressão, acessórios faciais, etc., o modelo apresenta notável diversidade geracional.
Esta rede implementa vários mapas de recursos 2D de um campo de radiação neural em um único plano de recursos 2D, onde o modelo executa a difusão com reconhecimento de 3D. O modelo Rodin usa convolução com reconhecimento de 3D, que atende aos recursos projetados no plano de recursos 2D de acordo com seu relacionamento original em 3D, para fornecer a eficiência computacional necessária enquanto mantém a integridade da difusão em 3D.
Leia mais sobre IA:
VALL-E: O novo modelo de conversão de texto em fala da Microsoft pode duplicar a voz de todos em três segundos
O VALL-E da Microsoft parece ser o software fraudulento mais perigoso de todos os tempos
Artista cria script antirroubo para proteger arte e usa a mesma marca d'água dos geradores de IA
Microsoft e Google em 2023: o principal confronto do ano entre titãs da IA
A postagem A Microsoft lançou um modelo de difusão que pode construir um avatar 3D a partir de uma única foto de uma pessoa apareceu pela primeira vez no Metaverse Post.