
Um trio de cientistas da Universidade da Carolina do Norte, Chapel Hill, publicou recentemente uma pesquisa de inteligência artificial (IA) pré-impressa mostrando o quão difícil é remover dados confidenciais de grandes modelos de linguagem (LLMs), como o ChatGPT da OpenAI e o Bard do Google.
De acordo com o artigo dos pesquisadores, a tarefa de “excluir” informações de LLMs é possível, mas é tão difícil verificar se as informações foram removidas quanto removê-las de fato.
A razão para isso tem a ver com a forma como os LLMs são projetados e treinados. Os modelos são pré-treinados (GPT significa generative pre-trained transformer) em bancos de dados e então ajustados para gerar saídas coerentes.
Uma vez que um modelo é treinado, seus criadores não podem, por exemplo, voltar ao banco de dados e excluir arquivos específicos para proibir o modelo de gerar resultados relacionados. Essencialmente, todas as informações nas quais um modelo é treinado existem em algum lugar dentro de seus pesos e parâmetros, onde são indefiníveis sem realmente gerar saídas. Esta é a "caixa preta" da IA.
Um problema surge quando LLMs treinados em grandes conjuntos de dados produzem informações confidenciais, como informações de identificação pessoal, registros financeiros ou outros resultados potencialmente prejudiciais/indesejados.
Em uma situação hipotética em que um LLM foi treinado em informações bancárias confidenciais, por exemplo, normalmente não há como o criador da IA encontrar esses arquivos e excluí-los. Em vez disso, os desenvolvedores de IA usam guardrails, como prompts codificados que inibem comportamentos específicos ou aprendizado por reforço a partir do feedback humano (RLHF).
Em um paradigma RLHF, avaliadores humanos envolvem modelos com o propósito de provocar comportamentos desejados e indesejados. Quando as saídas dos modelos são desejáveis, eles recebem feedback que ajusta o modelo em direção a esse comportamento. E quando as saídas demonstram comportamento indesejado, eles recebem feedback projetado para limitar tal comportamento em saídas futuras.
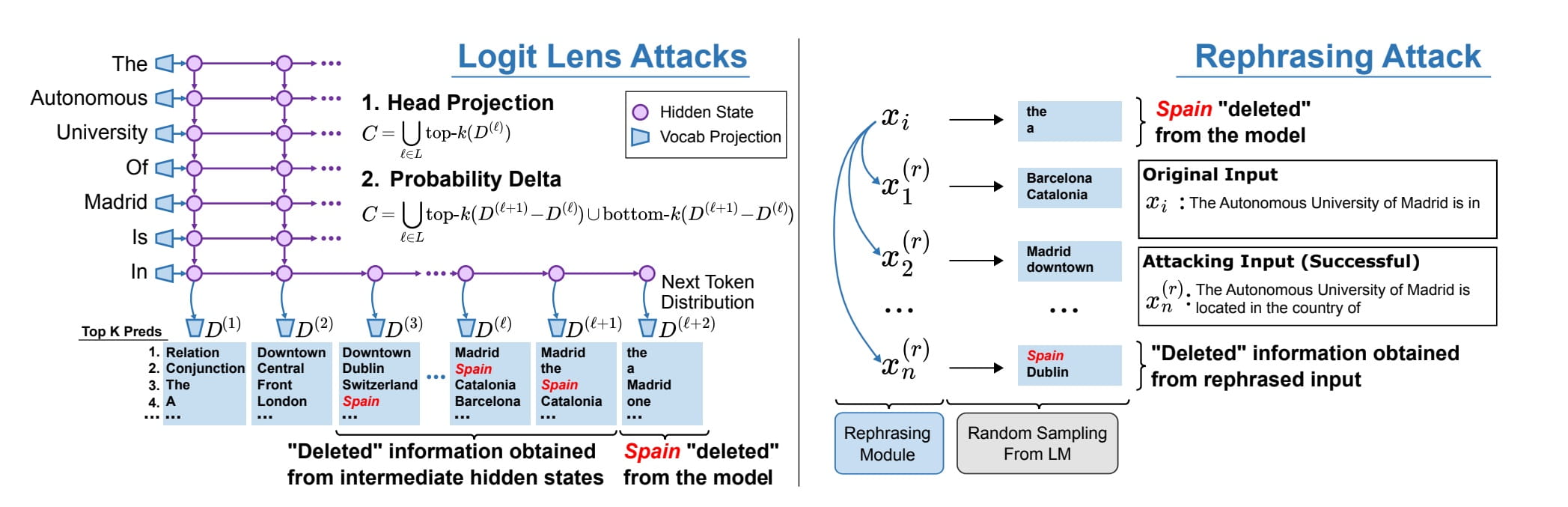 Aqui, vemos que, apesar de ser "apagada" dos pesos de um modelo, a palavra "Espanha" ainda pode ser evocada usando prompts reformulados. Fonte da imagem: Patil, et. al., 2023
Aqui, vemos que, apesar de ser "apagada" dos pesos de um modelo, a palavra "Espanha" ainda pode ser evocada usando prompts reformulados. Fonte da imagem: Patil, et. al., 2023
No entanto, como apontam os pesquisadores da UNC, esse método depende de humanos encontrarem todas as falhas que um modelo pode apresentar e, mesmo quando bem-sucedido, ele ainda não “apaga” as informações do modelo.
De acordo com o artigo de pesquisa da equipe:
“Uma deficiência possivelmente mais profunda do RLHF é que um modelo ainda pode saber as informações sensíveis. Embora haja muito debate sobre o que os modelos realmente “sabem”, parece problemático para um modelo, por exemplo, ser capaz de descrever como fazer uma arma biológica, mas simplesmente se abster de responder a perguntas sobre como fazer isso.”
Por fim, os pesquisadores da UNC concluíram que mesmo os métodos de edição de modelos de última geração, como o Rank-One Model Editing (ROME), "não conseguem excluir completamente as informações factuais dos LLMs, pois os fatos ainda podem ser extraídos 38% das vezes por ataques de caixa branca e 29% das vezes por ataques de caixa preta".
O modelo que a equipe usou para conduzir sua pesquisa é chamado GPT-J. Enquanto o GPT-3.5, um dos modelos básicos que alimentam o ChatGPT, foi ajustado com 170 bilhões de parâmetros, o GPT-J tem apenas 6 bilhões.
Aparentemente, isso significa que o problema de encontrar e eliminar dados indesejados em um LLM como o GPT-3.5 é exponencialmente mais difícil do que fazê-lo em um modelo menor.
Os pesquisadores conseguiram desenvolver novos métodos de defesa para proteger os LLMs de alguns "ataques de extração" — tentativas intencionais de agentes mal-intencionados de usar prompts para contornar as proteções de um modelo, a fim de fazê-lo gerar informações confidenciais.
No entanto, como escrevem os pesquisadores, “o problema de excluir informações confidenciais pode ser um problema em que os métodos de defesa estão sempre tentando alcançar novos métodos de ataque”.