
Fornece recursos de aprendizado de máquina precisos, consistentes e prontos para produção.

Esta peça explora nosso armazenamento de recursos de aprendizado de máquina (ML) com mais detalhes. É uma continuação de nossa postagem anterior no blog que fornece uma visão geral mais ampla de toda a infraestrutura de pipeline de ML.
Por que usamos uma Feature Store?
O feature store, uma das muitas partes do nosso pipeline, é sem dúvida a engrenagem mais importante do sistema. Seu objetivo principal é funcionar como um banco de dados central que gerencia recursos antes de serem enviados para treinamento ou inferência de modelo.
Se você não está familiarizado com o termo, os recursos são essencialmente dados brutos que são refinados, por meio de um processo chamado engenharia de recursos, em algo mais utilizável que nossos modelos de ML podem usar para treinar ou calcular previsões.
Resumindo, as lojas de recursos nos permitem:
Reutilize e compartilhe recursos entre diferentes modelos e equipes
Reduza o tempo necessário para experimentos de ML
Minimize previsões imprecisas devido a graves distorções no fornecimento de treinamento
Para entender melhor a importância de um feature store, aqui está um diagrama de um pipeline de ML que não o utiliza.
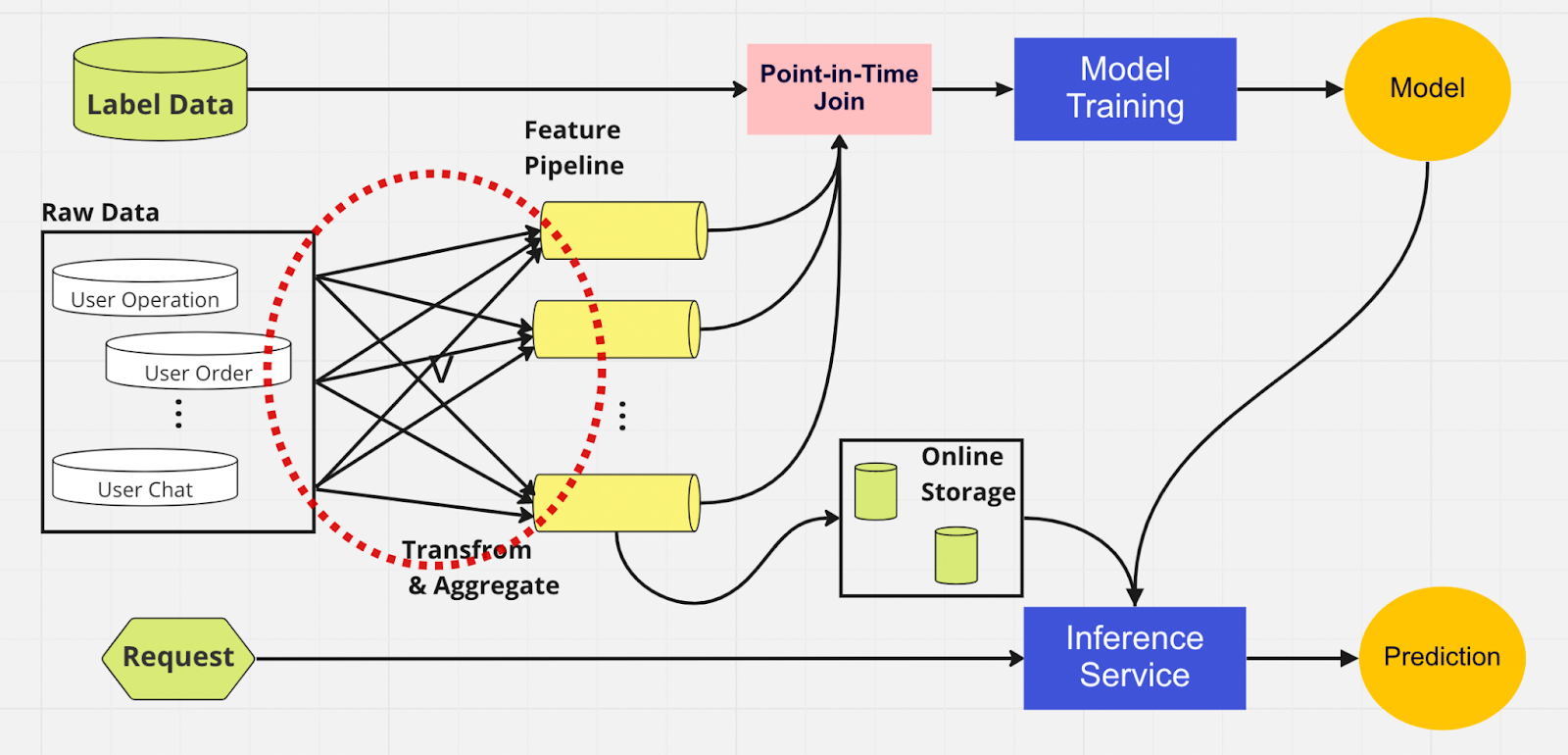
Neste pipeline, as duas partes — treinamento de modelo e serviço de inferência — não conseguem identificar quais recursos já existem e podem ser reutilizados. Isso faz com que o pipeline de ML duplique o processo de engenharia de recursos. Você notará no círculo vermelho no diagrama que o pipeline de ML, em vez de reutilizar recursos, construiu um conjunto de recursos duplicados e pipelines redundantes. Chamamos esse aglomerado de expansão do pipeline de recursos.
Manter essa expansão de recursos torna-se um cenário cada vez mais caro e incontrolável à medida que o negócio cresce e mais usuários entram na plataforma. Pense nisso desta maneira; o cientista de dados deve iniciar o processo de engenharia de recursos, que é longo e tedioso, inteiramente do zero para cada novo modelo criado.
Além disso, a reimplementação excessiva da lógica de recursos introduz um conceito chamado distorção de serviço de treinamento, que é uma discrepância entre os dados durante o estágio de treinamento e inferência. Isso leva a previsões imprecisas e a um comportamento imprevisível do modelo que é difícil de solucionar durante a produção. Antes dos armazenamentos de recursos, nossos cientistas de dados verificavam a consistência dos recursos usando verificações de integridade. Este é um processo manual e demorado que desvia a atenção de tarefas de maior prioridade, como modelagem e engenharia de recursos criteriosa. Agora, vamos explorar um pipeline de ML com um feature store.

Semelhante ao outro pipeline, temos as mesmas fontes de dados e recursos no lado esquerdo. No entanto, em vez de passar por vários pipelines de recursos, temos o feature store como um hub central que atende ambas as fases do pipeline de ML (treinamento de modelo e serviço de inferência). Não há recursos duplicados; todos os processos necessários para construir um recurso, incluindo transformação e agregação, só precisam ser executados uma vez.
Os cientistas de dados podem interagir intuitivamente com o armazenamento de recursos usando nosso Python SDK personalizado para pesquisar, reutilizar e descobrir recursos para treinamento e inferência de modelo de ML downstream.
Essencialmente, o feature store é um banco de dados centralizado que unifica ambas as fases. E como o armazenamento de recursos garante recursos consistentes para treinamento e inferência, podemos reduzir significativamente a distorção do serviço de treinamento.
Observe que as lojas de recursos fazem muito mais do que os pontos mencionados acima. Este é, obviamente, um resumo mais rudimentar de por que usamos um armazenamento de recursos e que podemos dividir em apenas algumas palavras: preparar e enviar recursos para modelos de ML da maneira mais rápida e fácil possível.
Dentro da Feature Store

A figura acima mostra seu layout típico de feature store, seja AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio ou Tetcom. Todas as lojas de recursos oferecem dois tipos de armazenamento: online ou offline.
Os armazenamentos de recursos online são usados para inferência em tempo real, enquanto os armazenamentos de recursos offline são usados para previsão em lote e treinamento de modelo. Devido aos diferentes casos de uso, a métrica que usamos para avaliar o desempenho é totalmente diferente. Em um recurso online, procuramos baixa latência. Para lojas de recursos off-line, queremos alto rendimento.
Os desenvolvedores podem escolher qualquer loja de recursos corporativos ou até mesmo código aberto com base na pilha de tecnologia. O diagrama abaixo descreve as principais diferenças entre as lojas online e offline no AWS SageMaker Feature Store.

Loja online: armazena a cópia mais recente dos recursos e os oferece com baixa latência de milissegundos, cuja velocidade depende do tamanho da carga útil. Para nosso modelo de controle de conta (ATO), que possui oito grupos de recursos e 55 recursos no total, a velocidade é de cerca de 30 ms de latência p99.
Armazenamento offline: um armazenamento somente anexado que permite rastrear todos os recursos históricos e permitir viagens no tempo para evitar vazamento de dados. Os dados são armazenados em formato parquet com particionamento de tempo para aumentar a eficiência de leitura.
Em relação à consistência do recurso, desde que o grupo de recursos esteja configurado para uso online e offline, os dados serão copiados automática e internamente para a loja offline enquanto o recurso é ingerido pela loja online.
Como usamos o Feature Store?

O código mostrado acima esconde muita complexidade. Os armazenamentos de recursos nos permitem simplesmente importar a interface python para treinamento e inferência do modelo.
Usando o armazenamento de recursos, nossos cientistas de dados podem definir facilmente recursos e construir novos modelos sem precisar se preocupar com o tedioso processo de engenharia de dados no back-end.
Melhores práticas para usar um Feature Store
Em nossa postagem anterior do blog, explicamos como usamos uma camada de armazenamento para canalizar recursos para o banco de dados centralizado. Aqui, gostaríamos de compartilhar duas práticas recomendadas ao usar uma feature store:
Não ingerimos recursos que não mudaram
Separamos os recursos em dois grupos lógicos: operações de usuário ativas e inativas.
Considere este exemplo. Digamos que você tenha um limite de otimização de 10 mil TPS para PutRecord em sua loja online. Usando essa hipótese, ingeriremos recursos para 100 milhões de usuários. Não podemos ingeri-los todos de uma vez e, com a nossa velocidade atual, demorará cerca de 2,7 horas para terminar. Para resolver isso, optamos por ingerir apenas recursos atualizados recentemente. Por exemplo, não ingeriremos um recurso se o valor não tiver mudado desde a última vez que foi ingerido.
Para o segundo ponto, digamos que você coloque um conjunto de recursos em um grupo lógico de recursos. Alguns estão ativos, enquanto uma grande parte está inativa, o que significa que a maioria dos recursos permanece inalterada. O passo lógico, em nossa opinião, é dividir ativo e inativo em dois grupos de recursos para agilizar o processo de ingestão.
Para recursos inativos, reduzimos 95% dos dados que precisamos ingerir no armazenamento de recursos para 100 milhões de usuários por hora. Além disso, ainda reduzimos 20% dos dados necessários para recursos ativos. Assim, em vez de três horas, o pipeline de ingestão em lote processa recursos no valor de 100 milhões de usuários em 10 minutos.
Considerações finais
Resumindo, os armazenamentos de recursos nos permitem reutilizar recursos, agilizar a engenharia de recursos e minimizar previsões imprecisas – ao mesmo tempo em que mantemos a consistência entre o treinamento e a inferência.
Interessado em usar o ML para proteger o maior ecossistema criptográfico do mundo e seus usuários? Confira Binance Engineering/AI em nossa página de carreiras para vagas de emprego abertas.
Leitura adicional:
(Blog) Usando MLOps para construir um pipeline de aprendizado de máquina ponta a ponta em tempo real