
Partner Multicoin Capital, Kyle Samani, omawia 7 powodów, dla których modułowe blockchainy są przeceniane.
Napisał: Kyle Samani, partner, Multicoin Capital
Opracowane przez: Luffy, Foresight News
W ciągu ostatnich dwóch lat debata na temat skalowalności blockchainu skupiała się na głównym temacie, jakim jest „debata między modułowością a integracją”.
Należy pamiętać, że dyskusje na temat kryptowalut często łączą systemy „pojedyncze” i „zintegrowane”. Debata techniczna na temat systemów zintegrowanych w porównaniu z systemami modułowymi trwa 40 lat. Na tę rozmowę w przestrzeni kryptowalut należy spojrzeć przez ten sam obiektyw, co na historię, i nie jest to żadna nowa debata.
Rozważając modułowość a integrację, najważniejszą decyzją projektową, jaką może podjąć blockchain, jest stopień, w jakim złożoność stosu jest widoczna dla twórców aplikacji. Klientami blockchain są twórcy aplikacji, dlatego ostateczne decyzje projektowe powinny uwzględniać ich perspektywę.
Obecnie modułowość jest w dużej mierze okrzyknięta głównym sposobem skalowania blockchainów. W tym artykule podważę to założenie wychodząc z podstawowych zasad, odkryję mity kulturowe i ukryte koszty systemów modułowych oraz podzielę się wnioskami, które wyciągnąłem z myślenia o tej debacie w ciągu ostatnich sześciu lat.
Systemy modułowe zwiększają złożoność programowania
Zdecydowanie największym ukrytym kosztem systemów modułowych jest dodatkowa złożoność procesu rozwoju.
Systemy modułowe znacznie zwiększają złożoność, jaką muszą zarządzać twórcy aplikacji, zarówno w kontekście własnych aplikacji (złożoność techniczna), jak i w kontekście interakcji z innymi aplikacjami (złożoność społeczna).
W kontekście kryptowalut modułowe łańcuchy bloków teoretycznie pozwalają na większą specjalizację, ale kosztem stworzenia nowej złożoności. Ta złożoność (zarówno natury technicznej, jak i społecznej) jest przekazywana twórcom aplikacji, co ostatecznie utrudnia tworzenie aplikacji.
Rozważmy na przykład stos OP. Na chwilę obecną wydaje się, że jest to najpopularniejszy framework modułowy. OP Stack zmusza programistów do wyboru pomiędzy przyjęciem Prawa Łańcuchów (co powoduje dużą złożoność społeczną) lub rozwidleniem i zarządzaniem nimi oddzielnie. Obie opcje stwarzają dla konstruktorów znaczną złożoność na dalszym etapie. Jeśli zdecydujesz się na rozwidlenie, czy otrzymasz wsparcie techniczne od innych uczestników ekosystemu (CEX, fiat on-ramp itp.), którzy muszą ponosić koszty, aby zachować zgodność z nowymi standardami technologicznymi? Jeśli zdecydujesz się postępować zgodnie z Prawem Łańcuchów, jakie zasady i ograniczenia zostaną na Ciebie nałożone dzisiaj i jutro?
Źródło: model OSI
Nowoczesne systemy operacyjne (OS) to duże, złożone systemy zawierające setki podsystemów. Nowoczesne systemy operacyjne obsługują warstwy 2–6 na powyższym schemacie. Jest to klasyczny przykład integracji komponentów modułowych w celu zarządzania złożonością stosu udostępnioną twórcom aplikacji. Twórcy aplikacji nie chcą zajmować się niczym poniżej warstwy 7, dlatego istnieją systemy operacyjne: system operacyjny zarządza złożonością poniższych warstw, dzięki czemu twórcy aplikacji mogą skupić się na warstwie 7. Dlatego modułowość nie powinna być celem samym w sobie, ale środkiem do celu.
Każdy większy system oprogramowania na świecie — backendy w chmurze, systemy operacyjne, silniki baz danych, silniki gier itp. — jest wysoce zintegrowany i składa się z wielu modułowych podsystemów. Systemy oprogramowania są zwykle wysoce zintegrowane, aby zmaksymalizować wydajność i zmniejszyć złożoność programowania. To samo dotyczy blockchaina.
Nawiasem mówiąc, Ethereum zmniejsza złożoność, która pojawiła się w erze forków Bitcoina w latach 2011–2014. Zwolennicy modułowości często podkreślają model wzajemnych połączeń systemów otwartych (OSI), argumentując, że dostępność danych (DA) i ich wykonanie należy oddzielić, jednak argument ten jest powszechnie źle rozumiany; Właściwe zrozumienie zagadnienia prowadzi do wniosku odwrotnego: argumentu, że OSI jest systemem zintegrowanym, a nie modułowym.
Łańcuchy modułowe nie mogą szybciej wykonywać kodu
Z założenia powszechną definicją „łańcucha modułowego” jest oddzielenie dostępności danych (DA) i wykonania: jeden zestaw węzłów jest odpowiedzialny za DA, podczas gdy inny zestaw (lub zestawy) węzłów jest odpowiedzialny za wykonanie. Kolekcje węzłów nie muszą się nakładać, ale mogą.
W praktyce oddzielenie DA i wykonania nie poprawia z natury wydajności żadnego z nich, raczej jakiś sprzęt gdzieś na świecie musi wykonywać DA, a jakiś sprzęt gdzieś musi implementować wykonanie. Oddzielenie tych funkcji nie poprawia wydajności żadnej z nich. Chociaż separacja może obniżyć koszty obliczeniowe, można je zmniejszyć jedynie poprzez centralizację wykonywania.
Powtórzę: niezależnie od architektury modułowej czy zintegrowanej, gdzieś jakiś sprzęt musi wykonać swoje zadanie, a rozdzielenie DA i wykonania na oddzielny sprzęt samo w sobie nie przyspiesza ani nie zwiększa ogólnej wydajności systemu.
Niektórzy twierdzą, że modułowość umożliwia równoległe działanie wielu maszyn EVM w sposób zbiorczy, umożliwiając wykonanie skalowanie w poziomie. Chociaż jest to teoretycznie poprawne, pogląd ten w rzeczywistości podkreśla ograniczenia EVM jako procesora jednowątkowego, a nie podstawowe założenie oddzielenia DA i wykonania w kontekście skalowania ogólnej przepustowości systemu.
Sama modułowość nie poprawia przepustowości.
Modułowość zwiększa koszty transakcyjne dla użytkowników
Z definicji każda L1 i L2 jest niezależną księgą aktywów z własnym stanem. Te oddzielne elementy stanu mogą się komunikować, aczkolwiek z dłuższymi opóźnieniami w transakcjach i większą złożonością dla programistów i użytkowników (za pośrednictwem mostów międzyłańcuchowych, takich jak LayerZero i Wormhole).
Im więcej jest ksiąg aktywów, tym bardziej fragmentaryczny staje się globalny stan wszystkich kont. Jest to okropne zarówno dla sieci, jak i użytkowników w wielu sieciach. Fragmentacja państwa może nieść ze sobą szereg konsekwencji:
Zmniejszona płynność, skutkująca większymi poślizgami handlowymi;
Większe całkowite zużycie gazu (transakcje międzyłańcuchowe wymagają co najmniej dwóch transakcji na co najmniej dwóch księgach aktywów);
Zwiększone podwójne liczenie w księgach aktywów (zmniejszając w ten sposób ogólną przepustowość systemu): Kiedy cena ETH-USDC zmieni się na Binance lub Coinbase, pojawią się możliwości arbitrażu w każdej puli ETH-USDC we wszystkich księgach aktywów (można łatwo sobie wyobrazić świat, w którym za każdym razem, gdy zmienia się cena ETH-USDC na Binance lub Coinbase, w różnych księgach aktywów występuje ponad 10 transakcji. Utrzymywanie stałych cen w stanie fragmentarycznym jest niezwykle mało efektywne w przypadku efektywnego wykorzystania przestrzeni blokowej.
Ważne jest, aby zdać sobie sprawę, że utworzenie większej liczby ksiąg aktywów znacznie zwiększa koszty we wszystkich tych wymiarach, zwłaszcza tych związanych z DeFi.
Podstawowymi danymi wejściowymi DeFi jest stan łańcucha (tj. kto jest właścicielem jakich aktywów). Kiedy zespoły uruchamiają łańcuchy aplikacji/rollupy, w naturalny sposób tworzą fragmentację stanu, co jest bardzo szkodliwe dla DeFi, zarówno programistów zarządzających złożonością aplikacji (mosty, portfele, opóźnienia, MEV między łańcuchami itp.), jak i użytkowników ( Poślizg, opóźnienia w rozliczeniach).
Najbardziej idealnym warunkiem dla DeFi jest to, że aktywa są emitowane w jednej księdze aktywów i przedmiotem obrotu w ramach jednej maszyny stanowej. Im większa księga aktywów, tym większą złożonością muszą zarządzać twórcy aplikacji i tym wyższe koszty muszą ponieść użytkownicy.
Pakiet zbiorczy aplikacji nie stworzy nowych możliwości zarabiania dla programistów
Zwolennicy AppChain/Rollup uważają, że zachęty skłonią twórców aplikacji do opracowywania pakietów zbiorczych, zamiast opierać się na L1 lub L2, aby aplikacje mogły same uchwycić wartość MEV. Jednak ten pomysł jest błędny, ponieważ uruchomienie pakietu zbiorczego aplikacji nie jest jedynym sposobem na przechwycenie MEV z powrotem do tokenów warstwy aplikacji i w większości przypadków nie jest to najlepszy sposób. Tokeny warstwy aplikacji mogą przechwytywać MEV z powrotem do własnych tokenów, po prostu kodując logikę w inteligentnych kontraktach we wspólnym łańcuchu. Rozważmy kilka przykładów:
Likwidacja: Jeśli DAO Compound lub Aave chce przechwycić część MEV przepływającą do bota likwidacyjnego, może po prostu zaktualizować swoje odpowiednie umowy, tak aby część opłat aktualnie napływających do likwidatora była płacona własnemu DAO, bez konieczności dla nowego łańcucha/rollupu.
Oracle: tokeny Oracle mogą przechwytywać MEV, zapewniając usługi wsteczne. Oprócz aktualizacji cen, Oracles może również łączyć dowolne transakcje w łańcuchu, które gwarantują uruchomienie natychmiast po aktualizacji cen. Dlatego wyrocznie mogą przechwytywać MEV, udostępniając usługi wsteczne wyszukiwarkom, konstruktorom bloków itp.
Minting NFT: Minting NFT jest pełen botów skalpujących. Można to łatwo złagodzić, po prostu kodując realokację malejących zysków. Na przykład, jeśli ktoś spróbuje odsprzedać swój NFT w ciągu dwóch tygodni od wybicia NFT, 100% wpływów wróci do emitenta lub DAO. Odsetek ten może zmieniać się w czasie.
Nie ma uniwersalnej odpowiedzi na przechwytywanie MEV w tokenach warstwy aplikacji. Jednak przy odrobinie namysłu twórcy aplikacji mogą z łatwością przechwycić MEV z powrotem do własnych tokenów w uniwersalnym łańcuchu. Uruchamianie zupełnie nowego łańcucha jest po prostu niepotrzebne i spowodowałoby dodatkową złożoność techniczną i społeczną dla programistów, a także więcej problemów z portfelem i płynnością dla użytkowników.
Pakiet zbiorczy aplikacji nie może rozwiązać problemów z przeciążeniem między aplikacjami
Wiele osób uważa, że Łańcuch/Rollup Aplikacji gwarantuje, że aplikacje nie będą dotknięte skokami gazu spowodowanymi innymi działaniami w łańcuchu, takimi jak popularne wybijanie NFT. Pogląd ten jest częściowo prawdziwy, ale w większości błędny.
Jest to problem historyczny, a podstawową przyczyną jest jednowątkowy charakter EVM, a nie dlatego, że nie ma oddzielenia DA i wykonania. Wszystkie L2 płacą opłatę L1, a opłaty L1 mogą zostać zwiększone w dowolnym momencie. Podczas szaleństwa na memecoin na początku tego roku opłaty transakcyjne na Arbitrum i Optimism na krótko przekroczyły 10 dolarów. Opłaty za Optimism również ostatnio gwałtownie wzrosły po uruchomieniu Worldcoin.
Jedynymi rozwiązaniami pozwalającymi zaradzić skokom opłat są: 1) maksymalizacja L1 DA, 2) maksymalne udoskonalenie rynku opłat:
Jeśli zasoby L1 są ograniczone, skoki wykorzystania poszczególnych L2 zostaną przeniesione na L1, co spowoduje zwiększenie kosztów na wszystkich pozostałych L2. Dlatego łańcuch aplikacji/Rollup nie jest odporny na skoki gazu.
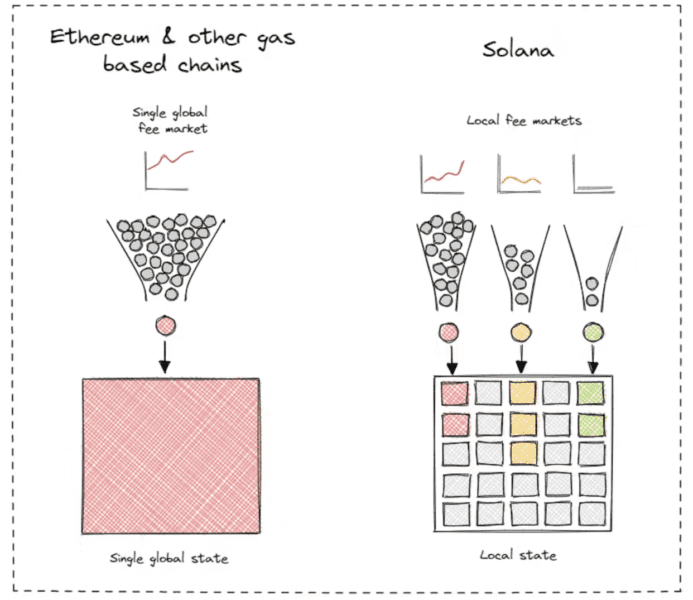
Współistnienie wielu EVM L2 to tylko prosty sposób na wypróbowanie rynku opłat lokalizacyjnych. Jest to lepsze niż umieszczanie rynku opłat w jednym EVM L1, ale nie rozwiązuje to podstawowego problemu. Kiedy zdasz sobie sprawę, że rozwiązaniem jest zlokalizowany rynek opłat, logicznym punktem końcowym będzie rynek opłat według stanu (a nie rynek opłat dla L2).
Do tego wniosku doszły już inne sieci. Solana i Aptos w naturalny sposób lokalizują rynki opłat. Wymagało to rozległych prac inżynieryjnych prowadzonych przez wiele lat dla odpowiednich środowisk wykonawczych. Większość zwolenników rozwiązań modułowych poważnie nie docenia znaczenia i trudności w projektowaniu lokalnych rynków opłat.
Uruchamiając wiele łańcuchów, programiści nie odblokowują rzeczywistego wzrostu wydajności. Gdy istnieją aplikacje generujące zwiększony wolumen transakcji, ma to wpływ na koszty wszystkich łańcuchów L2.
Elastyczność jest przereklamowana
Zwolennicy łańcuchów modułowych twierdzą, że architektura modułowa jest bardziej elastyczna. To stwierdzenie jest oczywiście prawdziwe, ale czy ma to naprawdę znaczenie?
Przez sześć lat próbowałem znaleźć programistów aplikacji, dla których ogólny język L1 nie byłby w stanie zapewnić znaczącej elastyczności. Jednak jak dotąd poza trzema bardzo konkretnymi przypadkami użycia nikt nie był w stanie wyjaśnić, dlaczego elastyczność jest ważna i jak bezpośrednio pomaga w skalowaniu. Trzy konkretne przypadki użycia, w których uważam, że elastyczność jest ważna, to:
Aplikacje korzystające ze stanu „gorącego”. Stan gorący to stan niezbędny do koordynowania pewnego zestawu operacji w czasie rzeczywistym, ale zostanie przesłany do łańcucha tylko tymczasowo i nie będzie istniał wiecznie. Kilka przykładów stanów termicznych:
Zlecenia z limitem w DEX-ach, takich jak dYdX i Sei (wiele zleceń z limitem kończy się anulowaniem).
Przepływ zamówień jest koordynowany i identyfikowany w czasie rzeczywistym w dFlow, protokole ułatwiającym zdecentralizowany rynek przepływu zamówień pomiędzy animatorami rynku a portfelami.
Wyrocznie takie jak Pyth, która jest wyrocznią o niskim opóźnieniu. Pyth działa jako samodzielny łańcuch SVM. Pyth generuje tak dużo danych, że główny zespół Pyth zdecydował, że najlepiej będzie wysyłać aktualizacje cen z dużą częstotliwością do niezależnego łańcucha, a następnie używać Wormhole do powiązania cen z innymi sieciami, jeśli zajdzie taka potrzeba.
Zmodyfikuj łańcuch konsensusu. Najlepszymi przykładami są Osmosis (gdzie wszystkie transakcje są szyfrowane przed wysłaniem do walidatorów) i Thorchain (gdzie transakcje w ramach bloku są traktowane priorytetowo na podstawie uiszczanych opłat).
Wymagana jest infrastruktura, która w jakiś sposób wykorzystuje schemat podpisu progowego (TSS). Przykładami tego są Sommelier, Thorchain, Osmosis, Wormhole i Web3Auth.
Z wyjątkiem Pyth i Wormhole wszystkie przykłady wymienione powyżej są tworzone przy użyciu zestawu Cosmos SDK i działają jako samodzielne łańcuchy. To mówi wiele o przydatności i skalowalności pakietu Cosmos SDK dla wszystkich trzech przypadków użycia: stanów gorących, modyfikacji konsensusu i systemów Threshold Signature Scheme (TSS).
Jednak większość projektów w powyższych trzech przypadkach użycia nie jest aplikacjami, lecz infrastrukturą.
Pyth i dFlow nie są aplikacjami, są infrastrukturą. Sommelier, Wormhole, Sei i Web3Auth to nie aplikacje, to infrastruktura. Wśród nich istnieje tylko jeden konkretny typ aplikacji skierowanej do użytkownika: DEX (dYdX, Osmosis, Thorchain).
Od sześciu lat pytam zwolenników Cosmos i Polkadot o przypadki użycia wynikające z oferowanej przez nie elastyczności. Myślę, że jest wystarczająco dużo danych, aby wyciągnąć pewne wnioski:
Po pierwsze, przykłady infrastruktury nie powinny istnieć w postaci pakietów zbiorczych, ponieważ albo generują zbyt dużo danych o niskiej wartości (takich jak stany gorące, a cały sens stanów gorących polega na tym, że dane nie są przesyłane z powrotem do L1) lub ponieważ działają coś celowo niezgodnego z zasobami w księdze, funkcjonalność związana z aktualizacją statusu (na przykład wszystkie przypadki użycia TSS).
Po drugie, jedyną aplikacją, jaką widziałem, która mogłaby zyskać na zmianie projektu systemu podstawowego, jest DEX. Ponieważ DEX jest zalany MEV, a łańcuchy uniwersalne nie są w stanie dorównać opóźnieniom CEX. Konsensus jest podstawą jakości realizacji transakcji i MEV, więc zmiany oparte na konsensusie w naturalny sposób przyniosą DEX wiele możliwości innowacyjnych. Jednakże, jak wspomniano wcześniej w tym artykule, głównym czynnikiem wpływającym na spot DEX jest aktywo będące przedmiotem obrotu. DEX-y konkurują o aktywa, a co za tym idzie o emitentów aktywów. W tych ramach niezależne łańcuchy DEX raczej nie odniosą sukcesu, ponieważ główną kwestią, którą emitenci aktywów rozważają przy wydawaniu aktywów, nie jest MEV związany z DEX, ale ogólna funkcjonalność inteligentnych kontraktów i włączenie tej funkcjonalności do odpowiednich aplikacji deweloperów.
Jednakże instrumenty pochodne DEX nie muszą konkurować o emitentów aktywów. Opierają się głównie na zabezpieczeniach, takich jak USDC i źródła cen Oracle, i zasadniczo muszą blokować aktywa użytkowników, aby zabezpieczyć pozycje w instrumentach pochodnych. Zatem w sensie niezależnych łańcuchów DEX najprawdopodobniej będą działać w przypadku DEX-ów skupionych na instrumentach pochodnych, takich jak dYdX i Sei.
Rozważmy popularne obecnie zintegrowane aplikacje L1, w tym: gry, systemy DeSoc (takie jak Farcaster i Lens), protokoły DePIN (takie jak Helium, Hivemapper, Render Network, DIMO i Daylight), dźwięk, wymiany NFT i inne . Żaden z nich nie korzysta szczególnie z elastyczności wynikającej z modyfikowania konsensusu, a wszystkie odpowiadające im księgi aktywów mają dość prosty, oczywisty i wspólny zestaw wymagań: niskie opłaty, małe opóźnienia, dostęp do spotowych indeksów DEX, dostęp do monet stabilnych i dostęp do kanałów fiat, takich jak CEX.
Uważam, że mamy teraz wystarczająco dużo danych, aby w pewnym stopniu stwierdzić, że zdecydowana większość aplikacji skierowanych do użytkownika ma te same ogólne wymagania, które wymieniono w poprzednim akapicie. Chociaż niektóre aplikacje mogą optymalizować inne zmienne na marginesie za pomocą niestandardowych funkcji w stosie, kompromisy związane z tymi dostosowaniami zwykle nie są tego warte (więcej mostów, mniej obsługi portfela, mniej wsparcia dla programów indeksowania/zapytań, redukcja legalnej waluty kanały itp.).
Wdrażanie nowych rejestrów zasobów to jeden ze sposobów osiągnięcia elastyczności, ale rzadko dodaje wartość i prawie zawsze powoduje złożoność techniczną i społeczną, przynosząc niewielkie korzyści dla twórców aplikacji.
Rozszerzone DA nie wymaga ponownego kredytu hipotecznego
Usłyszysz także, jak zwolennicy modułowości mówią o ponownym założeniu w kontekście skalowania. Jest to najbardziej spekulacyjny argument zwolenników łańcuchów modułowych, ale warto go omówić.
Z grubsza stwierdza się, że dzięki ponownemu stakowaniu (np. poprzez systemy takie jak EigenLayer) cały ekosystem kryptowalut może ponownie obstawiać ETH nieskończoną liczbę razy, wzmacniając nieograniczoną liczbę warstw DA (np. EigenDA) i warstw wykonawczych. Dlatego też, zapewniając uznanie wartości ETH, skalowalność jest rozwiązana ze wszystkich aspektów.
Pomimo ogromnej niepewności między obecną sytuacją a teoretyczną przyszłością, przyjmujemy za pewnik, że wszystkie założenia dotyczące stratyfikacji działają zgodnie z reklamą.
DA Ethereum wynosi obecnie około 83 KB/s. Wraz z wprowadzeniem protokołu EIP-4844 jeszcze w tym roku prędkość ta może się w przybliżeniu podwoić do około 166 KB/s. EigenDA może dodać dodatkowe 10 MB/s, ale wymaga innego zestawu założeń bezpieczeństwa (nie wszystkie ETH zostaną ponownie zabezpieczone na rzecz EigenDA).
Dla porównania, Solana oferuje obecnie DA o szybkości około 125 MB/s (32 000 fragmentów na blok, 1280 bajtów na strzęp, 2,5 bloku na sekundę). Solana jest znacznie wydajniejsza niż Ethereum i EigenDA. Dodatkowo DA Solany rozszerza się w czasie zgodnie z prawem Nelsona.
Istnieje wiele sposobów na rozszerzenie DA poprzez remortgage i modularyzację, ale mechanizmy te są dziś po prostu niepotrzebne i wprowadzają znaczną złożoność techniczną i społeczną.
Zbudowany dla twórców aplikacji
Po latach rozmyślań doszedłem do wniosku, że modułowość nie powinna być celem samym w sobie.
Blockchain musi służyć swoim klientom (tj. twórcom aplikacji), dlatego blockchain powinien abstrahować od złożoności na poziomie infrastruktury, aby programiści mogli skupić się na budowaniu aplikacji światowej klasy.
Modułowość jest świetna. Jednak kluczem do zbudowania zwycięskiej technologii jest ustalenie, które części stosu należy zintegrować, a które pozostawić innym. W obecnej sytuacji integracja DA i łańcuchów wykonawczych z natury zapewnia prostsze doświadczenia dla użytkowników końcowych i programistów, a ostatecznie zapewni lepszą podstawę dla najlepszych w swojej klasie aplikacji.
Oryginalne łącze
Ten artykuł został przedrukowany z Foresight News za zgodą
Ten artykuł Partner multicoinowy instytucji Venture Capital: Dlaczego modułowy łańcuch bloków jest przewartościowany po raz pierwszy ukazał się na Zombicie.