
Autor: Yiping, IOSG Ventures
napisz z przodu
W miarę jak duże modele językowe (LLM) stają się coraz bardziej popularne, widzimy wiele projektów integrujących sztuczną inteligencję (AI) i blockchain. Coraz częściej łączy się LLM i blockchain, widzimy także możliwości ponownej integracji sztucznej inteligencji z blockchainem. Warto wspomnieć o uczeniu maszynowym o zerowej wiedzy (ZKML).
Sztuczna inteligencja i blockchain to dwie technologie transformacyjne o zasadniczo różnych cechach. Sztuczna inteligencja wymaga dużej mocy obliczeniowej, którą zazwyczaj zapewniają scentralizowane centra danych. Chociaż blockchain zapewnia zdecentralizowane przetwarzanie danych i ochronę prywatności, radzi sobie słabo w przypadku zadań wymagających przetwarzania i przechowywania na dużą skalę. Wciąż badamy i badamy najlepsze praktyki w zakresie integracji sztucznej inteligencji i blockchain. W przyszłości przedstawimy Państwu również kilka aktualnych przypadków projektów łączących „AI + blockchain”.
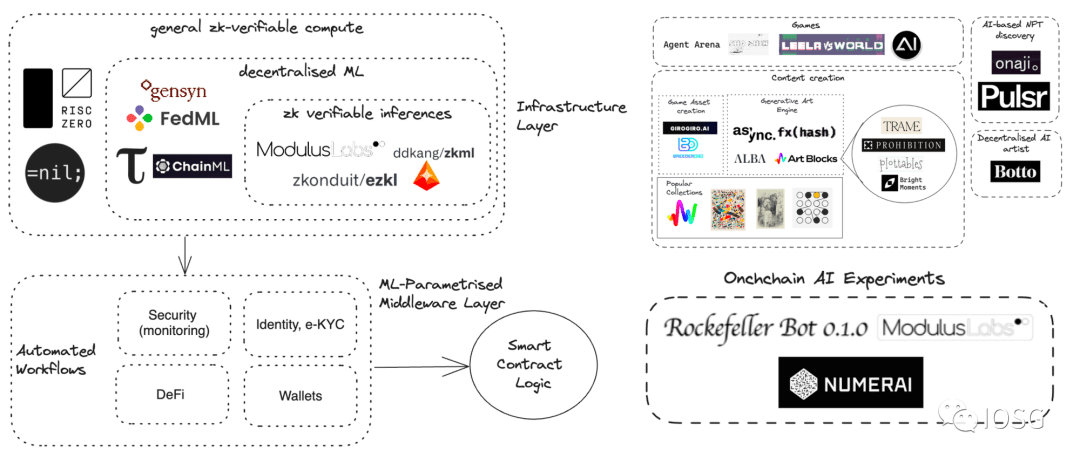
Źródło: IOSG Ventures
Ten raport badawczy jest opublikowany w dwóch częściach. W tym artykule skupimy się na zastosowaniu LLM w dziedzinie szyfrowania i zbadamy strategie wdrażania aplikacji.
Co to jest LLM?
LLM (Large Language Model) to skomputeryzowany model języka składający się ze sztucznej sieci neuronowej o dużej liczbie parametrów (zwykle miliardów). Modele te są szkolone na dużych ilościach tekstu bez etykiety.
Około 2018 roku narodziny LLM całkowicie zmieniły badania nad przetwarzaniem języka naturalnego. W przeciwieństwie do poprzednich metod, które wymagają szkolenia określonego nadzorowanego modelu do określonego zadania, LLM, jako model ogólny, dobrze radzi sobie z różnymi zadaniami. Jego możliwości i zastosowania obejmują:
Zrozumienie i podsumowanie tekstu: LLM może zrozumieć i podsumować duże ilości ludzkiego języka i danych tekstowych. Potrafią wyodrębnić kluczowe informacje i wygenerować zwięzłe podsumowania.
Generuj nową treść: LLM ma możliwość generowania treści tekstowych. Dostarczając podpowiedzi do modelu, może on odpowiadać na pytania, nowo wygenerowany tekst, podsumowania lub analizę nastrojów.
Tłumaczenie: LLM może być używany do tłumaczenia między różnymi językami. Wykorzystują algorytmy głębokiego uczenia się i sieci neuronowe, aby zrozumieć kontekst i relacje między słowami.
Przewiduj i generuj tekst: LLM może przewidywać i generować tekst na podstawie tła kontekstowego, podobnego do treści generowanych przez człowieka, w tym piosenek, wierszy, opowiadań, materiałów marketingowych i nie tylko.
Zastosowania w różnych dziedzinach: Duże modele językowe mają szerokie zastosowanie w zadaniach przetwarzania języka naturalnego. Są wykorzystywane w konwersacyjnej sztucznej inteligencji, chatbotach, służbie zdrowia, tworzeniu oprogramowania, wyszukiwarkach, korepetycjach, narzędziach do pisania i wielu innych.
Do zalet LLM należy zdolność rozumienia dużych ilości danych, możliwość wykonywania wielu zadań językowych oraz potencjał dostosowywania wyników do potrzeb użytkownika.
Typowe zastosowania modeli językowych na dużą skalę
Ze względu na wyjątkowe możliwości rozumienia języka naturalnego, LLM ma znaczny potencjał, a programiści skupiają się głównie na dwóch następujących aspektach:
Zapewnij użytkownikom dokładne i aktualne odpowiedzi w oparciu o obszerne dane i treści kontekstowe
Wykonuj określone zadania przydzielone przez użytkowników, korzystając z różnych agentów i narzędzi
To właśnie te dwa aspekty doprowadziły do gwałtownego wzrostu liczby aplikacji LLM do rozmów z XX. Na przykład rozmawiaj z plikami PDF, rozmawiaj z dokumentami i rozmawiaj z artykułami akademickimi.
Następnie podjęto próby połączenia LLM z różnymi źródłami danych. Programiści z powodzeniem zintegrowali platformy takie jak Github, Notion i niektóre oprogramowanie do robienia notatek z LLM.
Aby przezwyciężyć nieodłączne ograniczenia LLM, do systemu włącza się różne narzędzia. Pierwszym takim narzędziem była wyszukiwarka, zapewniająca LLM możliwość dostępu do najnowszej wiedzy. Dalszy postęp umożliwi integrację narzędzi takich jak WolframAlpha, Google Suites i Etherscan z dużymi modelami językowymi.
Architektura aplikacji LLM
Poniższy rysunek przedstawia przepływ aplikacji LLM w odpowiedzi na zapytania użytkowników: Najpierw odpowiednie źródła danych są konwertowane na osadzone wektory i przechowywane w bazie danych wektorów. Adapter LLM wykorzystuje zapytania użytkowników i wyszukiwania podobieństw w celu znalezienia odpowiedniego kontekstu w bazie danych wektorów. Odpowiedni kontekst jest umieszczany w podpowiedzi i wysyłany do LLM. LLM wykona te monity i użyje narzędzi do wygenerowania odpowiedzi. Czasami LLM są dostrajane do określonych zestawów danych, aby poprawić dokładność i obniżyć koszty.
Przepływ pracy w aplikacji LLM można ogólnie podzielić na trzy główne etapy:
Przygotowanie i osadzanie danych: Ta faza obejmuje zachowanie poufnych informacji (takich jak notatki projektowe) do przyszłego dostępu. Zazwyczaj pliki są segmentowane, przetwarzane poprzez osadzanie modeli i przechowywane w specjalnym typie bazy danych zwanej bazą danych wektorowych.
Formułowanie i wyodrębnianie podpowiedzi: Kiedy użytkownik przesyła żądanie wyszukiwania (w tym przypadku wyszukiwania informacji o projekcie), oprogramowanie tworzy serię podpowiedzi i wprowadza je do modelu językowego. Końcowy monit zwykle zawiera szablon podpowiedzi zakodowany na stałe przez twórcę oprogramowania, prawidłowy przykład wyjściowy w postaci kilku strzałów oraz wszelkie wymagane liczby uzyskane z zewnętrznego interfejsu API i powiązane pliki wyodrębnione z bazy danych wektorów.
Wykonywanie i wnioskowanie o podpowiedziach: Po ukończeniu podpowiedzi są one wprowadzane do istniejącego modelu językowego w celu wnioskowania, który może obejmować zastrzeżone interfejsy API modeli, modele typu open source lub indywidualnie dostrojone modele. Na tym etapie niektórzy programiści mogą również integrować z systemem systemy operacyjne (takie jak rejestrowanie, buforowanie i sprawdzanie poprawności).
Wprowadzenie LLM do kryptografii
Chociaż dziedzina szyfrowania (Web3) ma kilka zastosowań podobnych do sieci Web2, tworzenie dobrych aplikacji LLM w dziedzinie szyfrowania wymaga szczególnej ostrożności.
Ekosystem kryptowalut jest wyjątkowy, z własną kulturą, danymi i konwergencją. LLM dostrojone do tych kryptograficznie ograniczonych zbiorów danych mogą zapewnić doskonałe wyniki przy stosunkowo niskich kosztach. Chociaż dane są powszechnie dostępne, na platformach takich jak HuggingFace wyraźnie brakuje otwartych zbiorów danych. Obecnie istnieje tylko jeden zbiór danych dotyczący inteligentnych kontraktów, który zawiera 113 000 inteligentnych kontraktów.
Deweloperzy również stoją przed wyzwaniem integracji różnych narzędzi z LLM. Narzędzia te różnią się od tych używanych w Web2 i dają LLM możliwość dostępu do danych związanych z transakcjami, interakcji ze zdecentralizowanymi aplikacjami (Dapps) i wykonywania transakcji. Jak dotąd nie znaleźliśmy żadnej integracji Dapps w Langchain.
Chociaż tworzenie wysokiej jakości kryptograficznych aplikacji LLM może wymagać dodatkowych inwestycji, LLM w naturalny sposób pasuje do świata kryptografii. Ta domena zapewnia bogate, czyste i uporządkowane dane. W połączeniu z faktem, że kod Solidity jest ogólnie zwięzły i przejrzysty, ułatwia to LLM generowanie kodu funkcjonalnego.
W „Części 2” omówimy 8 potencjalnych kierunków, w których LLM może pomóc w dziedzinie blockchain, takich jak:
Zintegruj wbudowane możliwości AI/LLM z łańcuchem bloków
Analizuj zapisy transakcji za pomocą LLM
Zidentyfikuj potencjalne boty za pomocą LLM
Pisanie kodu przy użyciu LLM
Czytanie kodu za pomocą LLM
Pomóż społeczności dzięki LLM
Śledź rynek za pomocą LLM
Analizuj projekty za pomocą LLM