Kontynuując poprzednie dwa artykuły na temat kwestii wymagających uwagi w handlu programmatycznym:
Hard-core suche towary - szczegóły i przemyślenia na temat zautomatyzowanego handlu w czasie rzeczywistym w systemach handlu ilościowego (1. Problemy i trudności)
System handlu ilościowego — szczegóły i przemyślenia zautomatyzowanej oferty wiążącej (2. Cel oferty wiążącej)
W tym miejscu będziemy nadal mówić o niektórych szczegółowych umiejętnościach obsługi podczas projektowania kodu.
Baza danych
Jak wspomniano w dwóch poprzednich artykułach, zapis stanu bardziej złożonej kombinacji strategii jest bardzo ważny i wymaga użycia bazy danych.
Tak naprawdę większość firm programistycznych można zaliczyć do kategorii CRUD, co oznacza, że podstawowym procesem jest po prostu dodawanie, usuwanie, modyfikowanie i sprawdzanie bazy danych. Kody handlowe nie są wyjątkiem. Zachowanie w handlu wtórnym na rynku wtórnym o średniej i niskiej częstotliwości w rzeczywistości nie różni się zbytnio od zachowań ludzi kupujących określony skarb. Handel zautomatyzowany koncentruje się na zarządzaniu statusem strategicznym.
Jeśli nie znasz jeszcze relacyjnych baz danych, takich jak SQL, zaleca się bezpośrednie nauczenie się korzystania z baz danych NoSQL w pamięci, takich jak Redis. Jego zaletą jest to, że jest łatwy w uruchomieniu, ma doskonałą wydajność i jest z natury jednowątkowy. Nie ma potrzeby uwzględniania operacji niskiego poziomu, takich jak blokowanie danych podczas odczytu i zapisu. Wadą jest jednak brak klucza podstawowego i nie można realizować takich funkcji jak automatyczne zwiększanie liczby. Jeśli to konieczne, musisz napisać kod, aby go zaimplementować samodzielnie. Jednak nigdy tak długo nie korzystałem z tej funkcji w handlu automatycznym.
Kolejną nieistotną kwestią jest to, że w przypadku baz danych in-memory, jeśli ilość danych, które należy przechowywać, jest stosunkowo duża, wówczas pamięć serwera musi być większa. Jednak w przypadku ogólnego handlu ilościowego wystarczy i jest 4G lub nawet 2G pamięci nie potrzebne. Zapisz tyle danych.
Redis jest naprawdę potężny w prawdziwym świecie. Jeśli Twoja strategia ma wymagania dotyczące wysokiej częstotliwości, może również wdrożyć model subskrypcji wiadomości pub/sub, eliminując potrzebę dodawania różnych dodatkowych modułów MQ. Jeśli korzystasz z relacyjnej bazy danych takiej jak MySQL, jak wspomniano wcześniej, o ile nie korzystałeś wcześniej z niej w praktyce, będziesz musiał zainwestować czas i energię w naukę SQL, stosunkowo obrzydliwego i trudnego języka programowania. Pamiętaj, że wszyscy są tutaj, aby handlować ilościowo, a nie uczyć się pisania kodu. Spróbuj zastosować prostsze rozwiązanie.
Dodatkowo, jeśli chcesz zbudować centrum rynkowe, biorąc pod uwagę wydajność, będziesz także korzystać z bazy danych Redis i dla wygody współpracować z kolejką komunikatów. Rozwiązanie jest proste i odpowiednie dla większości scenariuszy. Można używać jednego serwera (lub wielu serwerów).
projekt kodu
Zasadniczo podczas pisania kodu najważniejsza jest podstawowa struktura danych. Projekt struktury danych nie jest wystarczająco rozsądny, a kod zostanie napisany niezręcznie, ponieważ nieuchronnie spowoduje to sprzęganie różnych modułów ze sobą, co sprawi, że modyfikacje będą bardzo kłopotliwe. Ale żeby to odpowiednio zaprojektować, trzeba mieć pewne doświadczenie handlowe, czyli doświadczenie biznesowe. Wszystko dotyczy pisania kodu, nie ma wiele do powiedzenia. Strategie każdego są inne i nie można ich traktować jednakowo. Jednak niektóre zasady są prawdopodobnie takie same.
Przykładowo po złożeniu zlecenia nie ma gwarancji powodzenia, nawet jeśli jest to zlecenie rynkowe, gdyż może zostać odrzucone przez giełdę. Na przykład centrala jest zbyt zajęta lub następuje tymczasowa utrata pakietów danych sieciowych. Następnie najlepiej zaprojektować stany pośrednie podobne do 2-fazowego zatwierdzenia. Jeśli się nie powiedzie, próbuj dalej (oczywiście nie za często, w przeciwnym razie zostanie zbanowany, jeśli przekroczy limit. Jest do tego specjalny dekorator ponawiania prób). lub dodaj więcej metod korygowania stanu błędu.
W normalnych okolicznościach, nawet jeśli giełda spada, w krótkim czasie odbuduje się. Jeśli nie odzyskasz połączenia, jedna ze stron – albo giełda, albo Twój własny serwer kodów – przestanie działać. Trzeba to monitorować i ostrzegać. Niemożliwym jest, aby zautomatyzowany kod obejmował wszystko. Jeśli nie można go przetworzyć automatycznie, zostanie wygenerowany alarm. Jeśli ręczne przetwarzanie nie zostanie załatwione na czas, o ile nie będziemy nadal otwierać pozycji w celu zwiększenia ekspozycji, problem nie będzie zbyt duży, ponieważ istnieją algorytmiczne zlecenia stop-loss pokrywające dno.
Poniżej znajduje się logika otwarcia strategii, którą sam rozwiązałem:
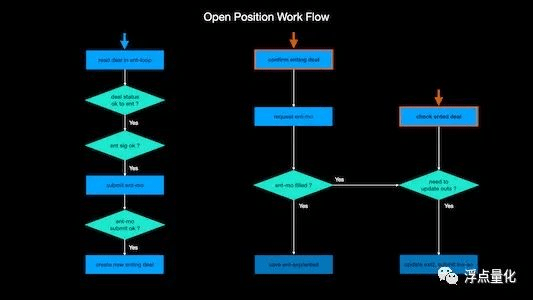
Zasadniczo, rysując podobny schemat blokowy, kod będzie znacznie lepiej zorganizowany, a liczba potencjalnych błędów zostanie zmniejszona. Dlatego przed napisaniem kodu najlepiej narysować schemat blokowy lub uporządkować go w trakcie pisania, tak aby logika była jasna i miał pomysł.
Logika zamykania pozycji jest znacznie bardziej skomplikowana, ponieważ istnieje więcej warunków zamknięcia pozycji, takich jak stop-profit, stop-loss i sygnały wyjścia różnych strategii, które spowodują zamknięcie pozycji. Krótko mówiąc, znaczenie wyjścia jest większe niż wejścia, a prawdziwa oferta jest również nieco bardziej kłopotliwa.
Ponieważ logika strategii każdego z nas jest zdecydowanie inna, nie będę tutaj wdawał się w szczegóły. Najważniejsze jest, aby wyprostować logikę strategiczną i zapobiec występowaniu różnych możliwych błędów.
Jednakże wydają się one skomplikowane i są po prostu zbiorem if else (Python nie ma nawet instrukcji switch). Jeśli warunki są spełnione, przejdź do następnego kroku. Jeśli nie, wyjdź. Nie ma większego problemu.
kontrola czasu
Podczas dokonywania transakcji niewątpliwie bardzo ważny jest czas. Tutaj podzielę się kilkoma innymi moimi umiejętnościami kontroli czasu.
W ogólnym programowaniu, jeśli istnieją zadania, które muszą być wykonywane regularnie, zwykle używane są pakiety zadań cron, takie jak apscheduler. Na przykład zaplanuj zaplanowane zadanie, aby wykryć, czy cena linii K musi otworzyć, czy zamknąć pozycję, gdy tylko nadejdzie odpowiednia godzina.
Pakiet tego rodzaju faktycznie otwiera nowy wątek natychmiast o określonej godzinie (może być z dokładnością do drugiego poziomu), a następnie wykonuje określone zadanie. Problem polega na tym, że jeśli czas wykonania tego zadania jest zbyt długi, następuje następne zadanie zaczną się od nowa. Pojawią się problemy. Chociaż można je rozwiązać, są one bardziej kłopotliwe.
Zwykle korzystam z takich zaplanowanych zadań, gdy muszę regularnie wyprowadzać informacje z dziennika oraz wykonywać autokorektę i autotest programu, które są funkcjami o niskiej częstotliwości i można je szybko wykonać. Funkcje te jedynie odczytują dane z bazy danych i nie wykonują żadnych operacji zapisu ani aktualizacji, więc nie zaszkodzi pozwolić apschedulerowi otworzyć kolejny wątek do przetworzenia.
Jednakże logika wymagająca ciągłego i częstego sprawdzania cen rynkowych lub statusu polityki lokalnej nie jest odpowiednia dla takiego pakietu czasowego i musi być kontrolowana przez pętlę while.
Przykładowo, jeśli strategia wykorzystuje sygnały w obrębie słupka linii K, oznacza to, że sygnał może pojawić się w dowolnym momencie i należy stale sprawdzać cenę bazową lub wolumen obrotu, aby określić, czy należy wykonać odpowiednie operacje. Jeśli na przykład potrzebujesz bardziej precyzyjnej kontroli czasu w tym momencie, wykonaj tylko logikę szeregową otwierania pozycji 10 sekund przed końcem godziny linii k. Jak więc możesz po prostu ocenić, czy jest to ostatnie 10 sekund?
Pozostałą część 3600 wziąłem, używając znacznika czasu.
(Jeśli nie znasz znacznika czasu na komputerze, czyli znacznika czasu, zaczyna się on od średniego czasu Greenwich 1970.1.1. Na przykład jest to około 1691240298 sekundy. Nie ma problemu z dokładnością komputera poziomie mikrosekund.)
Po wzięciu reszty z 3600, jeśli reszta jest większa niż 3590 sekund, jest to ostatnie dziesięć sekund. Błąd może sięgać poziomu milisekund. Jak wspomniano wcześniej, najlepiej, aby główne operacje transakcyjne były wykonywane sekwencyjnie w jednym wątku. W ten sposób można z grubsza kontrolować czas wykonania lub rozmyć okres czasu, co nie będzie stanowić problemu.
Tego rodzaju kontrola wymaga, aby ustawienie czasu własnego serwera nie odbiegało znacząco od czasu standardowego. Jednak tego rodzaju kontrola nie będzie zbyt precyzyjna, może dojść jedynie do drugiego poziomu. Jednak Python nie może bardzo precyzyjnie kontrolować czasu, a te funkcje uśpienia będą powodować błędy rzędu mikrosekund.
Zmniejsz częstotliwość dostępu do API
Jeśli zaadoptowałeś niezależne centrum rynkowe oparte na gnieździe sieciowym w celu udostępniania publicznych informacji rynkowych, takich jak linie K, pomiędzy różnymi strategiami lub nawet różnymi kodami handlowymi, nie ma w tym zakresie obaw związanych z limitami częstotliwości API.
Musimy jednak także terminowo pozyskiwać informacje o koncie, czyli trzy rodzaje informacji: fundusze, pozycje i zlecenia. Chociaż informacje o koncie mogą również korzystać z protokołu websocket i czekać, aż serwer Exchange aktywnie je wypchnie, prostsze jest bezpośrednie użycie pozostałego interfejsu API z trzech powodów.
Po pierwsze, aby zmniejszyć obciążenie informacji o koncie przesyłanych przez websocket, giełda wymaga od centrali co jakiś czas ponownego połączenia lub aktualizacji ListenKey (Binance to 60 minut). Taka sytuacja jest oczywiście bardziej kłopotliwa w utrzymaniu. Chociaż nie jest to duży problem, jeśli prowadzisz hosting API i handlujesz wieloma kontami jednocześnie, musisz aktywować osobny program, aby zapewnić dokładność informacji w czasie rzeczywistym, a logika staje się znacznie bardziej skomplikowana.
Po drugie, niektóre giełdy nie mają funkcji websocket umożliwiającej aktualizację informacji o koncie. W tym przypadku logika handlu nie jest uniwersalna i przełączanie prawdziwych kodów handlowych pomiędzy różnymi giełdami jest bardziej kłopotliwe. Oczywiście większość ludzi nie będzie handlować na wielu giełdach i nie spotka się z taką sytuacją.
Po trzecie, jeśli łącze websocket jest zepsute lub napotyka problemy takie jak wspomniana wcześniej aktualizacja ListenKey lub wygaśnięcie, jeśli program nie wykryje tego na czas, a akurat w tym momencie odbywa się transakcja, to jeśli polegasz tylko na websockecie, spowoduje to porównanie. Duży problem, ponieważ informacje o pominiętej aktualizacji konta nie zostaną ponownie przesłane. Aby uniknąć takich potencjalnych problemów, musisz także polegać na reszcie API, aby uzyskać określone informacje o koncie. Więc ostatecznie musimy polegać na rest API, czy nie jest to niepotrzebne?
Podsumowując, w przypadku transakcji o średniej i niskiej częstotliwości lepiej jest bezpośrednio użyć rest api w celu uzyskania informacji o koncie. W przypadku ważnych źródeł danych najlepiej stosować metodę SSOT (Single Source Of Truth), w przeciwnym razie może to spowodować potencjalne zamieszanie. Pojęcie to można samemu w Google wygooglować i jest bardzo przydatne w programowaniu opierającym się na przetwarzaniu danych.
Następnie, jeśli korzystasz wyłącznie z interfejsu API REST w celu uzyskania informacji o koncie, możesz zachować tymczasową tabelę informacji o koncie w lokalnej pamięci kodów, zwłaszcza o dostępnych środkach, co może zmniejszyć częste wizyty na giełdzie. Kluczem jest szybkość i możesz wysłać wszystkie zamówienia na raz. Podobnie do składania zamówień partiami, a następnie powolnego przetwarzania logiki stojącej za aktualizacją, im szybciej zamówienie zostanie złożone, tym naturalnie mniejszy będzie poślizg.
Dodatkowo, aby określić, czy algorytmiczne zlecenie stop-loss zostało zrealizowane, można skorzystać z ostatnich najwyższych i najniższych cen zamiast bezpośrednio uzyskiwać status zlecenia oczekującego, ponieważ aby ustalić, czy zlecenie zostało zrealizowane, należy odpytać w sposób ciągły, co jest stosunkowo częste i powoduje wiele nieprawidłowych dostępu do interfejsu API. Aktualizacja cen websocket K-line odbywa się bardzo szybko i nie zajmuje limitu częstotliwości API.
W ten sam sposób niektóre polecenia wyjścia mogą również wyglądać w ten sposób. Jeśli Twój sygnał wyjścia opiera się na cenie w obrębie słupka, lepszym rozwiązaniem może być użycie ostatnich najwyższych i najniższych cen. Ponieważ czasami cena uruchamia się i powraca natychmiast, jeśli częstotliwość sprawdzania nie jest zbyt duża, możesz ją przeoczyć. Aby zapewnić spójność swojej strategii handlowej, sprawdzaj najwyższe i najniższe ceny, aby nie przeoczyć cen. Podejście to ma tę dodatkową zaletę, że rzeczywista cena transakcyjna może być korzystniejsza niż rzeczywista cena progowa.
Nie wiem, czy powyższe dwa punkty są łatwe do zrozumienia. Może to wymagać doświadczenia z prawdziwego życia.
Chciałbym podzielić się częścią mojego doświadczenia w tworzeniu prawdziwego kodu, mając nadzieję, że będzie to pomocne dla wszystkich.