

Główne dania na wynos
Binance wykorzystuje zarządzanie wydajnością w przypadku nieplanowanych wzrostów ruchu spowodowanych dużą zmiennością, zapewniając odpowiednią, terminową infrastrukturę i zasoby obliczeniowe dla potrzeb biznesowych.
Testy obciążeniowe Binance w środowisku produkcyjnym (a nie w środowisku testowym), aby uzyskać dokładne testy porównawcze usług. Ta metoda pomaga sprawdzić, czy nasza alokacja zasobów jest odpowiednia do obsługi określonego obciążenia.
Infrastruktura Binance radzi sobie z dużym ruchem, a utrzymanie usługi, na której użytkownicy mogą polegać, wymaga odpowiedniego zarządzania wydajnością i automatycznego testowania obciążenia.

Dlaczego Binance potrzebuje specjalistycznego procesu zarządzania pojemnością?
Zarządzanie wydajnością jest podstawą stabilności systemu. Wymaga to odpowiedniego dopasowania zasobów aplikacji i infrastruktury do bieżących i przyszłych potrzeb biznesowych, przy odpowiednich kosztach. Aby pomóc osiągnąć ten cel, budujemy narzędzia i potoki zarządzania wydajnością, aby uniknąć przeciążenia i pomóc firmom zapewnić płynną obsługę użytkowników.
Rynki kryptowalut często borykają się z bardziej regularnymi okresami zmienności niż tradycyjne rynki finansowe. Oznacza to, że system Binance musi od czasu do czasu wytrzymywać wzrost ruchu, gdy użytkownicy reagują na ruchy rynkowe. Dzięki odpowiedniemu zarządzaniu wydajnością utrzymujemy ją na poziomie odpowiednim do ogólnego zapotrzebowania biznesowego i scenariuszy zwiększonego ruchu. Ten kluczowy punkt jest dokładnie tym, co sprawia, że procesy zarządzania pojemnością Binance są wyjątkowe i stanowią wyzwanie.
Przyjrzyjmy się czynnikom, które często utrudniają ten proces i prowadzą do powolnej lub niedostępnej usługi. Po pierwsze mamy przeciążenia, zwykle spowodowane nagłym wzrostem ruchu. Może to na przykład wynikać ze zdarzenia marketingowego, powiadomienia push, a nawet ataku DDoS (rozproszona odmowa usługi).
Wzrost ruchu i niewystarczająca pojemność wpływają na funkcjonalność systemu, ponieważ:
Usługa wymaga coraz większej pracy.
Czas odpowiedzi wzrasta do tego stopnia, że w ramach limitu czasu klienta nie można odpowiedzieć na żadne żądanie. Ta degradacja zwykle ma miejsce z powodu nasycenia zasobów (procesora, pamięci, wejścia/wyjścia, sieci itp.) lub przedłużających się przerw w działaniu GC w samej usłudze lub jej zależnościach.
W rezultacie usługa nie będzie w stanie szybko przetworzyć żądań.
Rozbicie procesu
Teraz, gdy omówiliśmy ogólną zasadę zarządzania pojemnością, przyjrzyjmy się, jak Binance stosuje ją w swojej działalności. Oto rzut oka na architekturę naszego systemu zarządzania wydajnością z kilkoma kluczowymi przepływami pracy.
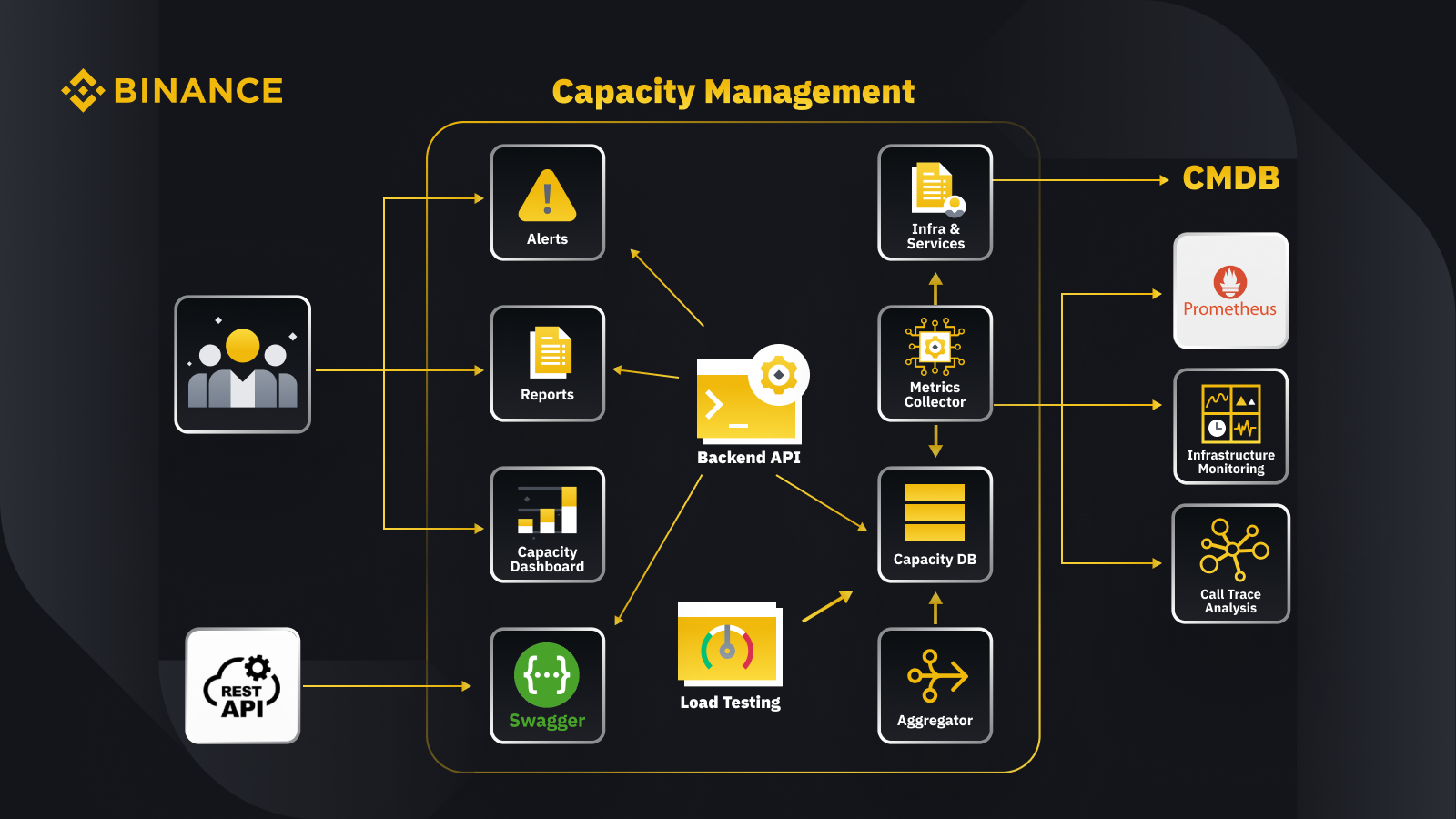
Pobierając dane z bazy danych zarządzania konfiguracją (CMDB), generujemy konfiguracje infrastruktury i usług. Elementy w tych konfiguracjach są obiektami zarządzania wydajnością.
Moduł zbierający metryki pobiera metryki wydajności z programu Prometheus dla danych warstwy biznesowej i usług, monitorowanie infrastruktury w przypadku metryk warstwy zasobów oraz system analizy śledzenia połączeń w celu uzyskania informacji o śledzeniu. Moduł zbierający metryki przechowuje dane w bazie danych pojemności (CDB).
System testów obciążeniowych przeprowadza testy warunków skrajnych usług i przechowuje dane porównawcze w CDB.
Agregator pobiera dane dotyczące pojemności z CDB i agreguje je w wymiarach dziennych i najwyższych w historii (ATH). Po agregacji zapisuje zagregowane dane z powrotem do CDB.
Przetwarzając dane z bazy CDB, interfejs API zaplecza zapewnia interfejsy dla pulpitu nawigacyjnego pojemności, alertów i raportów, a także pozostałego interfejsu API i powiązanych danych dotyczących pojemności na potrzeby integracji.
Zainteresowane strony uzyskują wgląd w pojemność za pośrednictwem pulpitu nawigacyjnego pojemności, alertów i raportów. Mogą także korzystać z innych powiązanych systemów, w tym monitorować dane dotyczące wydajności usług za pomocą rest API udostępnianego przez system zarządzania pojemnością za pomocą Swagger.
Strategia
Nasza strategia zarządzania wydajnością i planowania opiera się na przetwarzaniu zorientowanym na szczyt. Przetwarzanie w trybie szczytowym to obciążenie zasobów usługi (serwery internetowe, bazy danych itp.) w okresie szczytowego wykorzystania.
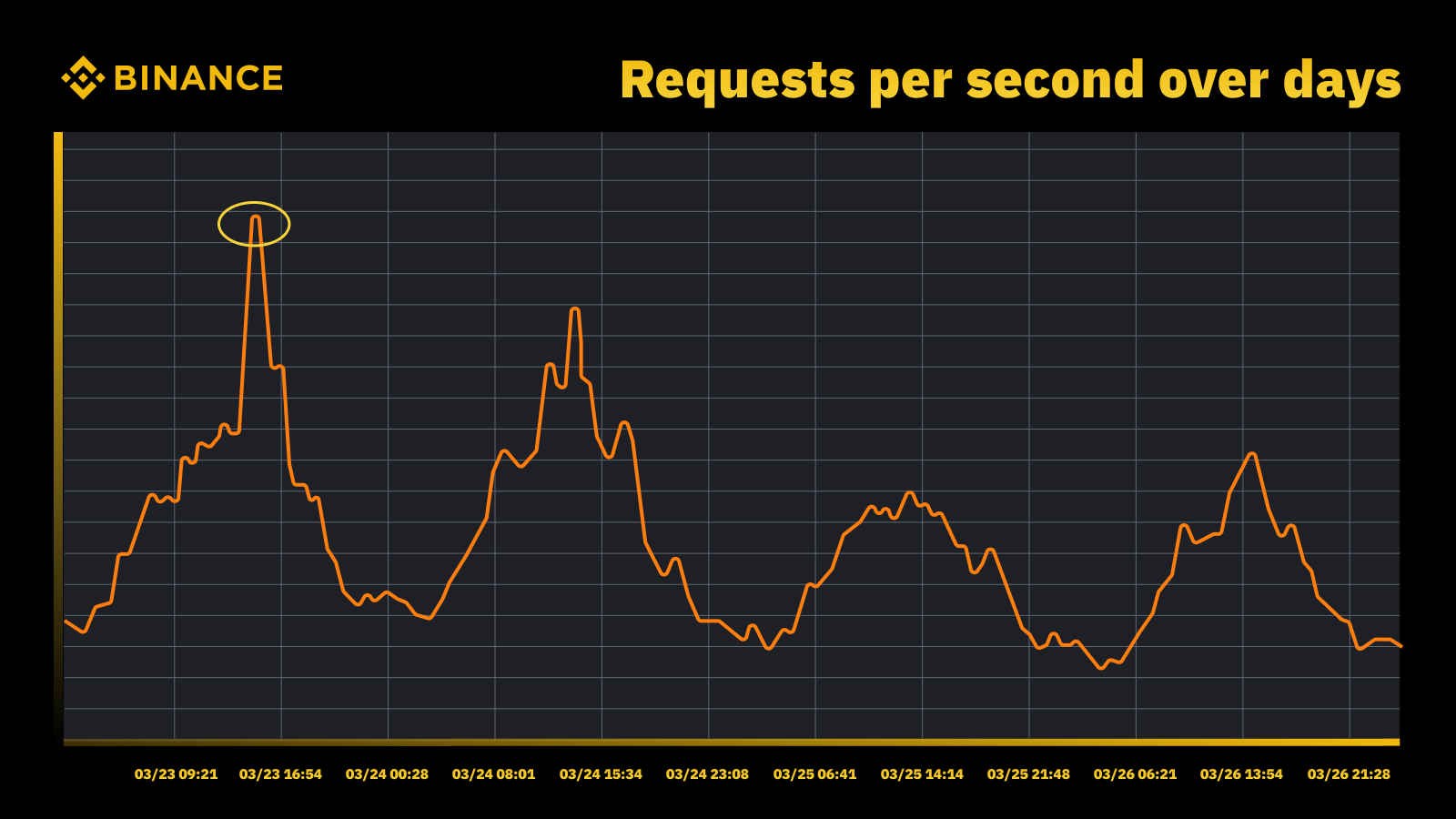
Wzrost ruchu po podniesieniu stopy procentowej przez Fed w marcu 2023 r
Analizujemy okresowe szczyty i wykorzystujemy je do sterowania trajektorią wydajności. Podobnie jak w przypadku każdego zasobu osiąganego w szczytach, chcemy dowiedzieć się, kiedy występują szczyty, a następnie zbadać, co faktycznie dzieje się podczas tych cykli.
Kolejną ważną rzeczą, którą bierzemy pod uwagę oprócz zapobiegania przeciążeniom, jest autoskalowanie. Automatyczne skalowanie obsługuje przeciążenie poprzez dynamiczne zwiększanie pojemności przy większej liczbie wystąpień usługi. Nadmiar ruchu jest następnie rozdzielany, a ruch obsługiwany przez pojedynczą instancję usługi (lub zależności) pozostaje możliwy do zarządzania.
Automatyczne skalowanie ma swoje miejsce, ale nie radzi sobie samodzielnie z sytuacjami przeciążenia. Zwykle nie jest w stanie zareagować wystarczająco szybko na nagły wzrost ruchu i działa najlepiej tylko wtedy, gdy wzrost następuje stopniowo.
Pomiar
Pomiar odgrywa kluczową rolę w pracy związanej z zarządzaniem pojemnością Binance, a gromadzenie danych jest naszym pierwszym krokiem pomiarowym. W oparciu o standardy Information Technology Infrastructure Library (ITIL) zbieramy dane do pomiaru w podprocesach zarządzania wydajnością, a mianowicie:
Zasób — zużycie zasobów infrastruktury IT zależne od wykorzystania aplikacji/usług. Koncentruje się na wewnętrznych metrykach wydajności fizycznych i wirtualnych zasobów obliczeniowych, w tym procesora serwera, pamięci, pamięci dyskowej, przepustowości sieci itp.
Praca. Miary wydajności na poziomie aplikacji, umowy SLA, opóźnienia i przepustowości wynikające z działań biznesowych. Koncentruje się na zewnętrznych wskaźnikach wydajności opartych na tym, jak użytkownicy postrzegają usługę, w tym na opóźnieniach w świadczeniu usług, przepustowości, szczytach itp.
Biznes. Gromadzi dane mierzące działania biznesowe przetwarzane przez aplikację docelową, w tym zamówienia, rejestrację użytkownika, płatności itp.
Zarządzanie wydajnością w oparciu jedynie o wykorzystanie zasobów infrastruktury doprowadzi do niedokładnego planowania. Dzieje się tak dlatego, że może nie odzwierciedlać rzeczywistego wolumenu działalności i przepustowości wpływającej na wydajność naszej infrastruktury.
Zaplanowane wydarzenia stanowią doskonałe miejsce do dalszej dyskusji na ten temat. Weź udział w Watch Web Summit 2022 na Binance Live, aby podzielić się aż do 15 000 BUSD w kampanii Crypto Box Rewards. Oprócz podstawowych wskaźników warstwy zasobów i usług musieliśmy także wziąć pod uwagę wolumen działalności. Planowanie wydajności oparliśmy tutaj na wskaźnikach biznesowych, takich jak szacowana liczba widzów transmisji na żywo, maksymalna liczba żądań w locie dotyczących Crypto Box, kompleksowe opóźnienia i inne czynniki.
Po zebraniu danych nasze procesy zarządzania wydajnością agregują i podsumowują liczne punkty danych zebrane w odniesieniu do konkretnego czynnika wydajności. Zagregowana wartość metryki to pojedyncza wartość, której można używać w alertach dotyczących wydajności, raportowaniu i innych funkcjach związanych z wydajnością.
Możemy zastosować kilka metod agregacji danych do okresowych punktów danych, takich jak suma, średnia, mediana, minimum, maksimum, percentyl i najwyższy poziom w historii (ATH).

Wybrana przez nas metoda określa wyniki procesu zarządzania wydajnością i wynikające z niego decyzje. Wybieramy różne metody w oparciu o różne scenariusze. Na przykład używamy metody maksymalnej dla usług krytycznych i powiązanych punktów danych. Aby odnotować największy ruch, stosujemy metodę ATH.
W różnych przypadkach używamy różnych typów szczegółowości do agregacji danych. W większości przypadków używamy minuty, godziny, dnia lub ATH.
Z minimalną szczegółowością mierzymy obciążenie usługi w celu terminowego powiadamiania o przeciążeniu.
Wykorzystujemy dane zagregowane godzinowo do tworzenia danych dziennych i agregujemy dane godzinowe w celu rejestrowania dziennego szczytu.
Zazwyczaj wykorzystujemy dane dzienne do raportów dotyczących wydajności i wykorzystujemy dane ATH do modelowania i planowania wydajności.
Jednym z podstawowych wskaźników zarządzania wydajnością jest benchmarking usług. Pomaga nam to dokładnie mierzyć wydajność i pojemność usług. Test porównawczy usług uzyskujemy poprzez testowanie obciążenia, a później zajmiemy się tym bardziej szczegółowo.
Zarządzanie wydajnością w oparciu o priorytety
Do tej pory widzieliśmy, jak zbieramy metryki wydajności i agregujemy dane z różnymi typami szczegółowości. Kolejnym krytycznym obszarem do omówienia jest priorytet, który jest pomocny w kontekście alertów i raportów o wydajności. Po dokonaniu rankingu zasobów IT, priorytetowe znaczenie ma ograniczone wykorzystanie infrastruktury i zasoby obliczeniowe, a w pierwszej kolejności przydzielane są krytycznym usługom i działaniom.
Istnieje wiele sposobów definiowania krytyczności usług i żądań. Przydatnym punktem odniesienia jest Google. W książce SRE. Definiują poziomy krytyczności jako CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS itp. Podobnie definiujemy wiele poziomów priorytetów, takich jak P0, P1, P2 i tak dalej.
Poziomy priorytetów definiujemy w następujący sposób:
P0: W przypadku najbardziej krytycznych usług i żądań, których awaria spowoduje poważne, widoczne dla użytkownika skutki.
P1: W przypadku usług i żądań, które spowodują wpływ widoczny dla użytkownika, ale wpływ będzie mniejszy niż w przypadku P0. Oczekuje się, że usługi P0 i P1 będą zapewniane z wystarczającą przepustowością.
P2: Jest to domyślny priorytet dla zadań wsadowych i zadań offline. Te usługi i żądania mogą nie mieć wpływu widocznego dla użytkownika, jeśli są częściowo niedostępne.
Co to jest testowanie obciążenia i dlaczego używamy go w środowisku produkcyjnym?
Testowanie obciążenia to niefunkcjonalny proces testowania oprogramowania, podczas którego sprawdzana jest wydajność aplikacji pod określonym obciążeniem. Pomaga to określić, jak aplikacja zachowuje się, gdy ma do niej dostęp wielu użytkowników końcowych jednocześnie.
W Binance stworzyliśmy rozwiązanie, które umożliwia nam przeprowadzanie testów obciążenia w środowisku produkcyjnym. Zazwyczaj testy obciążenia przeprowadzane są w środowisku testowym, ale nie mogliśmy skorzystać z tej opcji ze względu na nasze ogólne cele w zakresie zarządzania wydajnością. Testy obciążeniowe w środowisku produkcyjnym pozwoliły nam na:
Zbierz dokładny test porównawczy naszych usług w rzeczywistych warunkach obciążenia.
Zwiększ zaufanie do systemu, jego niezawodności i wydajności.
Identyfikuj wąskie gardła w systemie, zanim pojawią się w środowisku produkcyjnym.
Włącz ciągłe monitorowanie środowisk produkcyjnych.
Włącz proaktywne zarządzanie wydajnością dzięki znormalizowanym cyklom testowania, które odbywają się regularnie.
Poniżej możesz zobaczyć nasz framework do testowania obciążenia i kilka kluczowych wniosków:

Struktura mikrousług Binance ma warstwę podstawową obsługującą routing ruchu w oparciu o konfigurację i flagi, co jest niezbędne w naszym podejściu TIP.
Do oceny testowanej instancji stosowana jest automatyczna analiza kanarkowa (ACA). Porównuje kluczowe wskaźniki zebrane w systemie monitorowania, dzięki czemu możemy wstrzymać/zakończyć test, jeśli zdarzy się nieoczekiwany problem, aby zminimalizować wpływ na użytkownika.
Testy porównawcze i metryki są gromadzone podczas testów obciążenia w celu wygenerowania wglądu w dane dotyczące zachowań i wydajności aplikacji.
Interfejsy API mogą udostępniać cenne dane dotyczące wydajności w różnych scenariuszach, na przykład w zarządzaniu wydajnością i zapewnianiu jakości. Pomaga to w budowaniu otwartego ekosystemu.
Tworzymy automatyczne przepływy pracy, aby koordynować wszystkie kroki i punkty kontrolne z perspektywy kompleksowego testowania. Zapewniamy także elastyczność integracji z innymi systemami, takimi jak rurociąg CI/CD i portal operacyjny.
Nasze podejście do testowania w produkcji (TIP).
Tradycyjne podejście do testowania wydajności (przeprowadzanie testów w środowisku przejściowym z symulowanym lub lustrzanym odbiciem ruchu) zapewnia pewne korzyści. Jednakże wdrożenie środowiska pomostowego przypominającego środowisko produkcyjne ma w naszym kontekście więcej wad:
To prawie podwaja koszty infrastruktury i wysiłki konserwacyjne.
Kompleksowa praca w środowisku produkcyjnym jest niezwykle złożona, szczególnie w środowisku mikrousług na dużą skalę obejmującym wiele jednostek biznesowych.
Zwiększa to ryzyko związane z prywatnością i bezpieczeństwem danych, ponieważ nieuchronnie może zaistnieć potrzeba zduplikowania danych w fazie tymczasowej.
Symulowany ruch nigdy nie będzie repliką tego, co faktycznie dzieje się w środowisku produkcyjnym. Benchmark uzyskany w środowisku przejściowym byłby niedokładny i miał mniejszą wartość
Testowanie w środowisku produkcyjnym, znane również jako TIP, to metodologia testowania z przesunięciem w prawo, podczas której nowy kod, funkcje i wydania są testowane w środowisku produkcyjnym. Przyjęte przez nas testy obciążenia w środowisku produkcyjnym są bardzo korzystne, ponieważ pomagają nam:
Przeanalizuj stabilność i odporność systemu.
Odkryj testy porównawcze i wąskie gardła aplikacji przy różnym natężeniu ruchu, specyfikacjach serwerów i parametrach aplikacji.
Routing oparty na FlowFlag
Nasz routing oparty na FlowFlag osadzony w podstawowej strukturze mikrousług jest podstawą umożliwienia TIP. Dotyczy to konkretnych przypadków, w tym aplikacji korzystających z wykrywania usług Eureka do dystrybucji ruchu.
Jak pokazano na diagramie, serwer WWW Binance jako punkty wejścia oznacza pewien procent ruchu zgodnie z konfiguracjami za pomocą nagłówków FlowFlag, podczas testu obciążenia możemy wybrać jednego hosta określonej usługi i oznaczyć go jako docelową instancję wydajności w configs, wówczas te żądania oznaczone etykietą perf zostaną ostatecznie skierowane do instancji perf, gdy dotrą do usługi w celu przetworzenia.
Jest w pełni oparty na konfiguracji i ładowaniu na gorąco, możemy łatwo dostosować procent obciążenia za pomocą automatyzacji bez konieczności wdrażania nowej wersji
Można go szeroko zastosować w większości naszych usług, ponieważ mechanizm jest częścią pakietu bramkowego i podstawowego
Pojedynczy punkt zmiany oznacza również łatwe wycofanie zmian w celu zmniejszenia ryzyka w produkcji

Transformując nasze rozwiązanie tak, aby było bardziej natywne dla chmury, badamy również, w jaki sposób możemy opracować podobne podejście do obsługi innego routingu ruchu oferowanego przez dostawców chmury publicznej lub Kubernetes.
Zautomatyzowana analiza kanarek w celu zminimalizowania ryzyka wpływu na użytkownika
Wdrożenie Canary to strategia wdrażania mająca na celu zmniejszenie ryzyka wdrożenia nowej wersji oprogramowania w środowisku produkcyjnym. Zwykle wiąże się to z wdrożeniem nowej wersji oprogramowania, zwanej wersją kanaryjską, dla niewielkiej grupy użytkowników wraz ze stabilną wersją działającą. Następnie dzielimy ruch pomiędzy obie wersje, tak aby część przychodzących żądań była kierowana do kanarek.
Jakość wersji kanarkowej ocenia się następnie za pomocą tzw. analizy kanarkowej. Porównuje to kluczowe wskaźniki opisujące zachowanie starej i nowej wersji. W przypadku znacznego pogorszenia się metryk działanie programu Canary zostaje przerwane, a cały ruch jest kierowany do wersji stabilnej, aby zminimalizować wpływ nieoczekiwanego zachowania.
Używamy tej samej koncepcji do tworzenia naszego rozwiązania do automatycznego testowania obciążenia. Rozwiązanie wykorzystuje platformę Kayenta do automatycznej analizy kanarek (ACA) za pośrednictwem Spinnakera, aby umożliwić zautomatyzowane wdrażanie kanarek. Nasz typowy przebieg testu obciążenia podczas stosowania tej metody wygląda następująco:
W ramach przepływu pracy stopniowo zwiększamy obciążenie ruchem (np. 5%, 10%, 25%, 50%) do hosta docelowego zgodnie z określeniem lub do momentu osiągnięcia punktu krytycznego.
Przy każdym obciążeniu wielokrotnie przeprowadzana jest analiza Canary za pomocą oprogramowania Kayenta przez pewien czas (np. 5 minut) w celu porównania kluczowych wskaźników testowanego hosta z okresem wstępnego ładowania jako punktem odniesienia i obecnym okresem po załadowaniu jako eksperymentem.
Porównanie (model konfiguracji Canary) koncentruje się na sprawdzeniu, czy host docelowy:
Osiąga ograniczenia zasobów, np. użycie procesora przekracza 90%.
Ma znaczny wzrost wskaźników niepowodzeń, np. dzienników błędów, wyjątków HTTP lub odrzuceń z limitem szybkości.
Czy podstawowe wskaźniki aplikacji są nadal rozsądne, np. opóźnienie HTTP mniejsze niż 2 sekundy (możliwość dostosowania dla każdej usługi)
Dla każdej analizy Kayenta przekazuje nam raport wskazujący wynik, a test kończy się natychmiast w przypadku niepowodzenia.
Wykrycie awarii zajmuje zwykle mniej niż 30 sekund, co znacznie zmniejsza ryzyko wpływu na doświadczenia naszych użytkowników końcowych.

Włączanie wglądu w dane
Kluczowe jest zebranie wystarczających informacji o wszystkich opisanych wcześniej procesach i wykonaniach testów. Ostatecznym celem jest poprawa niezawodności i wytrzymałości naszego systemu, co nie jest możliwe bez wglądu w dane.
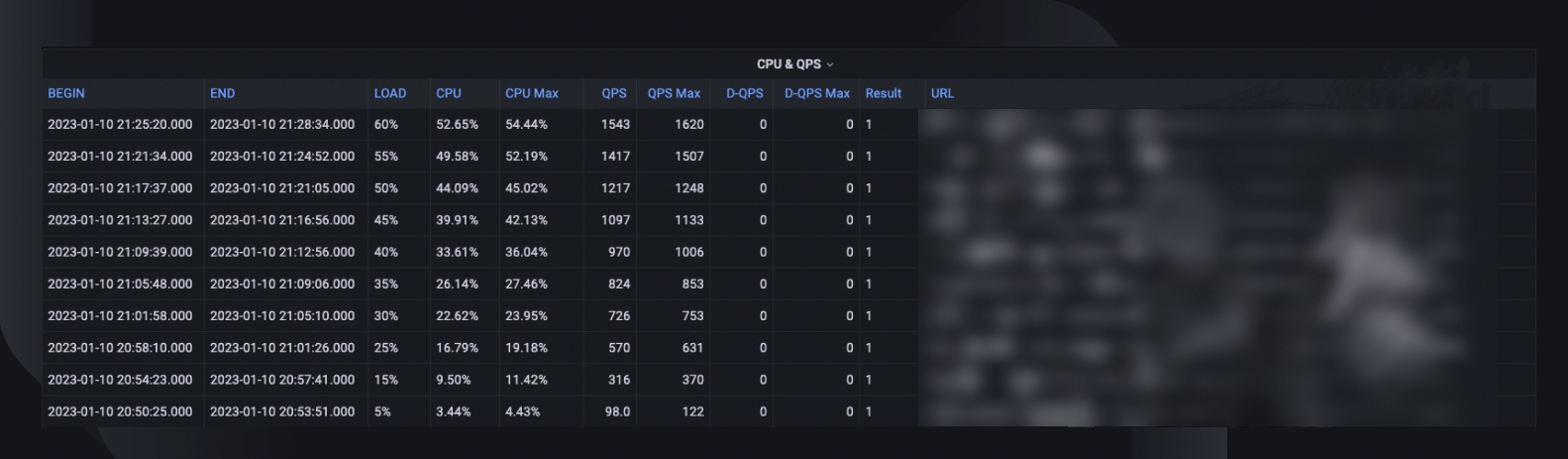
Ogólne podsumowanie testu uwzględnia maksymalny procent obciążenia, jaki host był w stanie obsłużyć, szczytowe wykorzystanie procesora i liczbę klatek na sekundę hosta. Na tej podstawie szacuje również liczbę instancji, które będziemy musieli wdrożyć, aby spełnić naszą rezerwację pojemności, biorąc pod uwagę najwyższy w historii wskaźnik QPS usług.
Inne cenne informacje do analizy obejmują wersję oprogramowania, specyfikację serwera, liczbę wdrożeń i łącze do pulpitu monitora, gdzie możemy spojrzeć wstecz na to, co wydarzyło się podczas testu.

Krzywa testu porównawczego wskazuje, jak zmieniła się wydajność w ciągu ostatnich trzech miesięcy, dzięki czemu możemy wykryć wszelkie możliwe problemy związane z konkretną wersją aplikacji.

Trendy dotyczące procesora i QPS pokazują, jak użycie procesora jest skorelowane z liczbą żądań, które serwer musiał obsłużyć. Ta metryka może pomóc w oszacowaniu wydajności serwerów pod kątem wzrostu ruchu przychodzącego.
Zachowanie opóźnień interfejsu API rejestruje, jak zmienia się czas odpowiedzi w różnych warunkach obciążenia dla pięciu najlepszych interfejsów API. W razie potrzeby możemy wówczas zoptymalizować system na poziomie indywidualnego API.

Metryki rozkładu obciążenia interfejsu API pomagają nam zrozumieć, w jaki sposób skład interfejsu API wpływa na wydajność usługi i dają lepszy wgląd w obszary ulepszeń.
Normalizacja i produktyzacja
W miarę ciągłego rozwoju i ewolucji naszego systemu będziemy śledzić i poprawiać stabilność i niezawodność usług. Będziemy to kontynuować poprzez:
Regularny i ustalony harmonogram testów obciążenia dla usług krytycznych.
Automatyczne testowanie obciążenia w ramach naszych potoków CI/CD.
Zwiększona produktywność całego rozwiązania w celu przygotowania go do wdrożenia na dużą skalę w szerszej organizacji.
Ograniczenia
Istnieją pewne ograniczenia obecnego podejścia do testów obciążenia:
Routing oparty na FlowFlag ma zastosowanie tylko w naszej strukturze mikrousług. Chcemy rozszerzyć rozwiązanie na więcej scenariuszy routingu, wykorzystując typową funkcję routingu ważonego w modułach równoważenia obciążenia w chmurze lub Kubernetes Ingress.
Ponieważ test opieramy na rzeczywistym ruchu użytkowników w środowisku produkcyjnym, nie możemy przeprowadzić testów funkcjonalności w oparciu o konkretne interfejsy API lub przypadki użycia. Ponadto w przypadku usług o bardzo niskim wolumenie wartość byłaby ograniczona, ponieważ możemy nie być w stanie zidentyfikować wąskiego gardła.
Przeprowadzamy te testy w odniesieniu do poszczególnych usług, a nie obejmujących kompleksowe łańcuchy połączeń.
Testy w środowisku produkcyjnym mogą czasami mieć wpływ na prawdziwych użytkowników, jeśli wystąpią awarie. Dlatego musimy mieć analizę błędów i automatyczne przywracanie stanu z pełnymi możliwościami automatyzacji.
Zamykające myśli
Niezwykle istotne jest dla nas przemyślenie scenariuszy wzmożonego ruchu, aby zapobiec przeciążeniu systemu i zapewnić jego nieprzerwaną pracę. Dlatego opracowaliśmy procesy zarządzania wydajnością i testowania obciążenia opisane w tym artykule. Podsumowując:
Nasze zarządzanie wydajnością jest zorientowane na szczyt i jest wbudowane w każdy etap cyklu życia usługi, zapobiegając przeciążeniu czynnościami takimi jak pomiary, ustawianie priorytetów, alerty i raporty dotyczące wydajności itp. To ostatecznie sprawia, że procesy i potrzeby Binance są wyjątkowe w porównaniu z typową sytuacją zarządzania wydajnością .
Benchmark usług uzyskany w wyniku testów obciążenia jest centralnym punktem zarządzania wydajnością i planowania. Dokładnie określa zasoby infrastruktury potrzebne do obsługi obecnych i przyszłych potrzeb biznesowych. Ostatecznie należało to wykonać w środowisku produkcyjnym za pomocą unikalnego rozwiązania stworzonego przez Binance, które pozwoliło nam zaspokoić nasze specyficzne potrzeby.
Mamy nadzieję, że podsumowując to wszystko, zobaczysz, że dobre planowanie i dokładne ramy pomagają stworzyć usługę, którą użytkownicy Binanci znają i lubią.
Bibliografia
Dominic Ogbonna, A-Z of Performance Management: Praktyczny przewodnik dotyczący wdrażania monitorowania IT w przedsiębiorstwie i planowania wydajności, rozdział 4, rozdział 6
Luis Quesada Torres, Doug Colish, Najlepsze praktyki SRE w zakresie zarządzania wydajnością
Alejandro Forero Cuervo, Sarah Chavis, książka Google SRE, rozdział 21 – Obsługa przeciążenia
Dalsze czytanie
(Blog) Jak Binance Ledger wspomaga Twoje doświadczenie Binance
(Blog) Przedstawiamy Binance Oracle VRF: Następną generację weryfikowalnej losowości
(Blog) Binance dołącza do sojuszu FIDO w ramach przygotowań do wdrożenia klucza dostępu