
GPT-4 osiągnął wyższe wyniki niż GPT-3.5 w różnych testach porównawczych. Jest to ogromny przełom w dziedzinie maszyn, ponieważ udowadnia, że obecnie mogą one nie tylko rozwiązywać problemy, do których pierwotnie zostały zaprojektowane, ale także lepiej niż studenci uniwersytetu.

Patrząc na ten wynik, należy wziąć pod uwagę kilka rzeczy. Po pierwsze, egzaminator GPT-4 nie przeszedł żadnego specjalnego szkolenia w zakresie tych egzaminów. Polegało to na wykorzystaniu najnowszych, ogólnodostępnych testów (w przypadku olimpiad i pytań z bezpłatną odpowiedzią AP) lub zakupieniu edycji egzaminów praktycznych na lata 2022–2023. Po drugie, należy zauważyć, że wydajność GPT-4 niekoniecznie musi odzwierciedlać umiejętności osób zdających test, ponieważ działa on w oparciu o inny zestaw zasad i algorytmów.
To duże osiągnięcie, ponieważ pokazuje, że maszyny nie tylko są zdolne do ludzkiej inteligencji, ale także mogą nas przewyższyć. To otwiera drogę do przyszłości, w której maszyny będą mogły podejmować się coraz bardziej złożonych zadań, co ostatecznie doprowadzi do przyszłości, w której będą mogły pomagać nam w codziennym życiu.
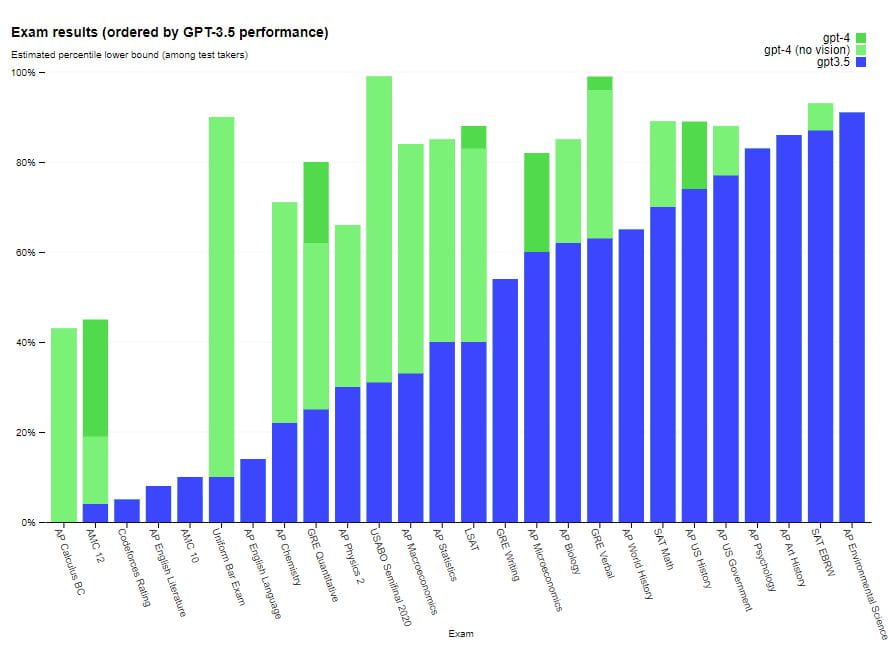 Zdolność GPT-4 do prześcigania ludzi w niektórych zadaniach rodzi pytania o przyszłość sztucznej inteligencji i jej potencjalny wpływ na rynek pracy. Podkreśla również potrzebę dalszych badań i rozwoju w tej dziedzinie, aby zapewnić etyczne i odpowiedzialne korzystanie ze sztucznej inteligencji. Dowiedz się więcej: 5+ najbardziej oczekiwanych modeli AI do przetwarzania tekstu na obraz w 2023 r.
Zdolność GPT-4 do prześcigania ludzi w niektórych zadaniach rodzi pytania o przyszłość sztucznej inteligencji i jej potencjalny wpływ na rynek pracy. Podkreśla również potrzebę dalszych badań i rozwoju w tej dziedzinie, aby zapewnić etyczne i odpowiedzialne korzystanie ze sztucznej inteligencji. Dowiedz się więcej: 5+ najbardziej oczekiwanych modeli AI do przetwarzania tekstu na obraz w 2023 r.
Na przykład GPT-4 zdaje symulowany egzamin adwokacki z wynikiem w górnych 10% zdających; wynik GPT-3.5 był w dolnych 10%. Ta znacząca poprawa w wydajności GPT-4 wynika z większych danych szkoleniowych i ulepszonej architektury. Oczekuje się, że będzie miał szeroki zakres zastosowań w różnych dziedzinach, w tym przetwarzanie języka naturalnego i automatyczne pisanie.
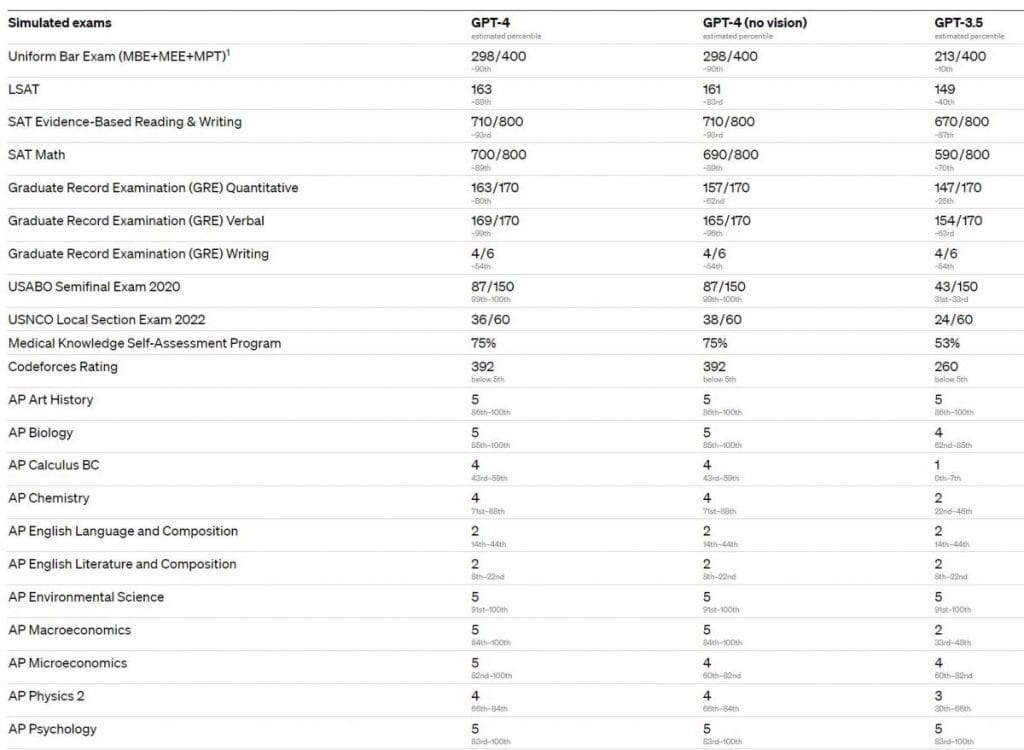 GPT-4 wykazuje wydajność na poziomie ludzkim w większości tych profesjonalnych i akademickich egzaminów. Co godne uwagi, zdał symulowaną wersję Uniform Bar Examination z wynikiem w najlepszych 10% zdających. Możliwości modelu na egzaminach wydają się wynikać przede wszystkim z procesu wstępnego szkolenia i nie są znacząco dotknięte przez RLHF. W pytaniach wielokrotnego wyboru zarówno podstawowy model GPT-4, jak i model RLHF wypadły równie dobrze średnio wśród twórców testowanego egzaminu.
GPT-4 wykazuje wydajność na poziomie ludzkim w większości tych profesjonalnych i akademickich egzaminów. Co godne uwagi, zdał symulowaną wersję Uniform Bar Examination z wynikiem w najlepszych 10% zdających. Możliwości modelu na egzaminach wydają się wynikać przede wszystkim z procesu wstępnego szkolenia i nie są znacząco dotknięte przez RLHF. W pytaniach wielokrotnego wyboru zarówno podstawowy model GPT-4, jak i model RLHF wypadły równie dobrze średnio wśród twórców testowanego egzaminu.
Większość najnowocześniejszych modeli (SOTA), w tym te, które mogą wykorzystywać dodatkowe protokoły szkoleniowe lub projekty specyficzne dla testów porównawczych, a także istniejące duże modele językowe, są znacznie mniej wydajne niż GPT-4.
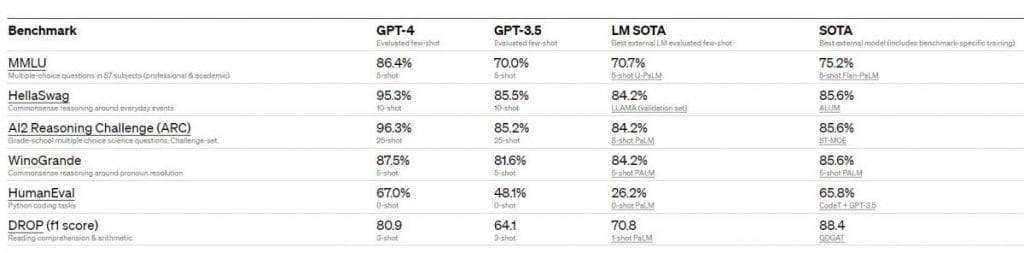 Wydajność GPT-4 pod względem standardów akademickich. Twórcy porównują GPT-4 z najlepszym SOTA dla LM ocenianego przez niewielu, a także najlepszym SOTA z treningiem specyficznym dla benchmarków. Z wyjątkiem DROP, GPT-4 przewyższa wszystkie obecne LM we wszystkich testach porównawczych i SOTA z treningiem specyficznym dla benchmarków.
Wydajność GPT-4 pod względem standardów akademickich. Twórcy porównują GPT-4 z najlepszym SOTA dla LM ocenianego przez niewielu, a także najlepszym SOTA z treningiem specyficznym dla benchmarków. Z wyjątkiem DROP, GPT-4 przewyższa wszystkie obecne LM we wszystkich testach porównawczych i SOTA z treningiem specyficznym dla benchmarków.
Wewnętrznie programiści wykorzystują GPT-4, co miało znaczący wpływ na takie działania jak programowanie, sprzedaż, wsparcie i moderowanie treści. Drugi etap naszej metody dopasowania jest obecnie w toku, ponieważ programiści używają jej, aby pomóc ludziom w przeglądaniu wyników AI.
Zestaw danych MMLU (Massive Multi-Task Language Understanding) zawiera pytania z bardzo szerokiego zakresu tematów dotyczących rozumienia języka w różnych zadaniach (obejmujących 57 dziedzin, w tym matematykę, biologię, prawo, nauki społeczne i humanistyczne itp.). Istnieją cztery możliwe odpowiedzi na pytanie, z których jedna jest poprawna. Oznacza to, że losowe zgadywanie pokazuje wynik 25% poprawnych odpowiedzi. Zobacz poniższy obrazek, aby zobaczyć przykłady pytań i ich trudności. Przeciętny osoba-marker (czyli nie jest to naukowiec, nie jest to profesor — zwykła osoba, która dorabia jako adiustator) odpowiada poprawnie na 35% pytań; jednak eksperci mogą osiągnąć wynik +/- 90%.
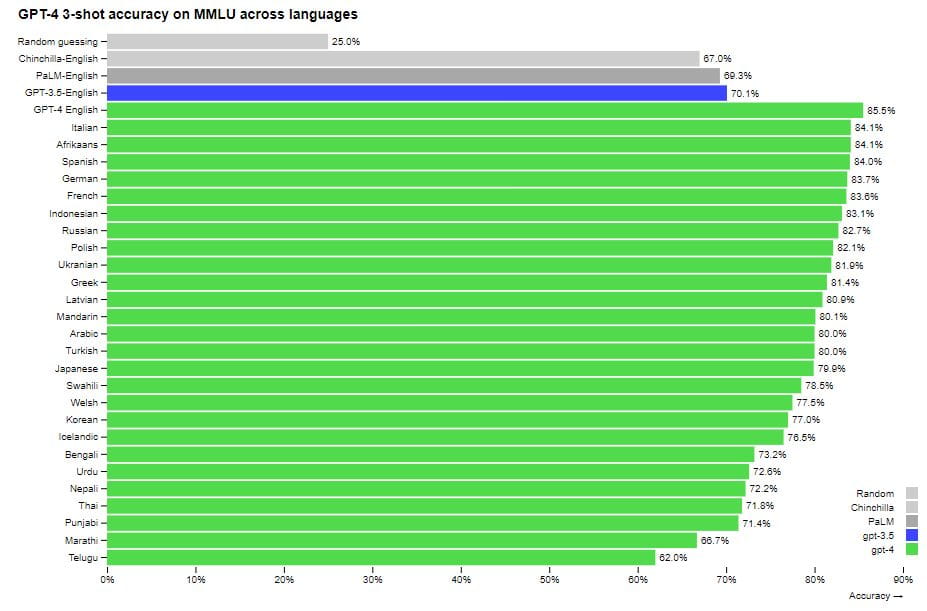 Wydajność GPT-4 w wielu językach w porównaniu do wcześniejszych modeli w języku angielskim na MMLU. GPT-4 przewyższa wydajność języka angielskiego istniejących modeli językowych dla większości badanych języków, w tym języków o niskich zasobach, takich jak łotewski, walijski i suahili. Dowiedz się więcej: 5 powodów, dla których warto używać Binga z obsługą AI zamiast Google
Wydajność GPT-4 w wielu językach w porównaniu do wcześniejszych modeli w języku angielskim na MMLU. GPT-4 przewyższa wydajność języka angielskiego istniejących modeli językowych dla większości badanych języków, w tym języków o niskich zasobach, takich jak łotewski, walijski i suahili. Dowiedz się więcej: 5 powodów, dla których warto używać Binga z obsługą AI zamiast Google
Pierwotnie cały zbiór danych był w języku angielskim. Ale co, jeśli pytania i odpowiedzi zostaną przetłumaczone na inne języki, zwłaszcza te mniej popularne? Czy model będzie dla nich jakoś działał? W tym teście do tłumaczenia użyto usługi Microsoft Azure Translate. Tłumaczenia nie są idealne; w niektórych przypadkach ważne informacje są tracone. Jednak nawet w tym przypadku GPT-4 dobrze sprawdza się w innych językach. W przetłumaczonych wersjach MMLU, GPT-4 przewyższa poziom języka angielskiego innych dużych modeli (w tym Google) o 24 z 26 badanych języków.
Co więcej, GPT-4 radzi sobie lepiej w rzadkich językach niż ChatGPT w języku angielskim (ChatGPT osiągnął wynik 70,1%, podczas gdy wynik nowego modelu dla języka tajskiego wyniósł 71,8%). Wynik testu w języku angielskim był najwyższy, a GPT-4 wypadł o 10% lepiej niż inne modele, w tym największy PaLM od Google. Osiągnął wynik 86,4%, podczas gdy grupa ekspertów — 90%.
Do lata 2023 roku sztuczna inteligencja może osiągnąć nowy poziom mocy dzięki ChatGPT, chatbotowi, który wykorzystuje algorytm GPT-4 i przewyższa GPT-3 o współczynnik 570. Na sukces ChatGPT wpływa wiele elementów, w tym jego projekt, który ma być bardziej „ludzki” oraz wykorzystanie najnowocześniejszej eksploracji danych i przetwarzania języka naturalnego w celu zwiększenia jego skuteczności i dokładności.
Microsoft i OpenAI ogłosiły odnowienie współpracy i plany, aby wyszukiwarka Bing przyjęła funkcje wyszukiwania wspomagane przez AI w styczniu. Właśnie wprowadzono na rynek bardzo wyrafinowany model zastępujący GPT3.5, GPT4, który ma potencjał, aby znacznie zwiększyć zdolność wyszukiwarki Bing do rozumienia zapytań w języku naturalnym i dostarczania dokładniejszych wyników. Dobrym pomysłem jest posiadanie dobrego planu zapasowego na wypadek, gdyby coś poszło nie tak.
Przeczytaj więcej powiązanych wiadomości:
Poznaj ChatGPT: sztuczną inteligencję, która może zabić Google
ChatGPT zdaje egzamin Wharton MBA
Ewolucja chatbotów od ery T9 i GPT-1 do ChatGPT
Artykuł GPT-4 przewyższa GPT-3.5 we wszystkich testach porównawczych ukazał się po raz pierwszy w Metaverse Post.