

Główne wnioski
Binance’s Ledger przechowuje salda kont i transakcje, a także umożliwia usługom dokonywanie transakcji.
Tworzy warunki niezbędne do wysokiej przepustowości, dostępności 24 godziny na dobę, 7 dni w tygodniu i dokładności danych na poziomie bitów.
Rola Binance Ledger za kulisami sprawia, że jest to jedna z najważniejszych technologii Binance. Dowiedz się dokładnie, jak działa i jakie problemy rozwiązuje w działaniu największej na świecie giełdy kryptowalut tutaj.

Czy kiedykolwiek zastanawiałeś się, co dokładnie napędza Binance? Biorąc pod uwagę konieczność przetwarzania milionów transakcji dziennie przez ogromną bazę użytkowników, warto przyjrzeć się temu, co Binance ma pod maską.
Podstawą operacji technicznych Binance jest Ledger. Ledger przechowuje salda kont i transakcje, umożliwiając jednocześnie usługom dokonywanie transakcji.
Binance ma wysokie wymagania co do Ledgera
Jak można sobie wyobrazić, wymagania dla Ledger są wysokie, aby sprostać ogromnemu zapotrzebowaniu użytkowników. Istnieją trzy główne punkty, które należy wziąć pod uwagę:
Wysoka przepustowość z możliwością obsługi dużej liczby transakcji na sekundę (TSP) w godzinach szczytu.
Dostępność 24/7, bez przestojów.
Dokładność danych na poziomie bitowym, bez utraty środków i błędów transakcji.
Przyjrzyjmy się przykładowi podstawowego wpisu w księdze rachunkowej. Oto typowa transakcja, w której konto 1 przekazuje 1 BTC na konto 2.
Saldo przed transakcją:
tabela-1
Saldo po transakcji:
tabela-2
W tej transakcji występują dwa polecenia:
Konto 1 -1 BTC
Konto 2 +1 BTC
Po dokonaniu transakcji zostaną zapisane dwa dzienniki sald w celu przeprowadzenia audytu i uzgodnienia.
tabela-3
Standardowe rozwiązanie branżowe
Jedno ze standardowych rozwiązań Ledger dla branży opiera się na relacyjnej bazie danych. Wracając do poprzedniego przykładu, dwa polecenia transakcji można przetłumaczyć na dwa polecenia SQL i wykonać w transakcji bazy danych (tabela 4).
tabela-4
Zalety rozwiązania
To całkiem proste do wdrożenia.
Łatwo jest zastosować powszechnie stosowane techniki dostrajania baz danych, takie jak podział odczytu/zapisu i partycjonowanie, aby poprawić wydajność.
Dla programistów odzyskiwanie danych po awarii oraz monitorowanie i utrzymywanie komercyjnej bazy danych nie stanowi dużego problemu.
Wady rozwiązania
TPS spadnie gwałtownie, gdy wystąpią warunki wyścigu spowodowane blokadą rzędów.
Trudno jest skalować poziomo w celu poprawy wydajności.
Problem z gorącym kontem
Niestety dla Binance, rozwiązanie branżowe zaprezentowane powyżej nie spełnia jej wysokich wymagań. Gdy następuje transakcja, musi ona utrzymywać blokady wierszy każdego zaangażowanego wiersza. Podczas gdy niektóre konta mają stosunkowo niewiele transakcji do obsłużenia, istnieją oczywiście zajęte konta z wieloma równoczesnymi transakcjami. W takim przypadku tylko jedna transakcja jest w stanie utrzymać blokadę wiersza konta.
Pozostałe transakcje nie mogą wtedy nic zrobić, tylko czekać na zwolnienie blokady. Tę sytuację nazywamy problemem gorącego konta, a wewnętrzne testy pokazują, że TPS spadnie co najmniej 10 razy w tej sytuacji. Możesz zobaczyć ten problem w tabeli 5 poniżej.
Przykład konta gorącego:
tabela-5
Rozwiązanie Ledger firmy Binance
Jak rozwiązać problem gorących kont?
Jednym z możliwych rozwiązań naszego problemu jest innowacyjne przekształcenie modelu wielowątkowego w tryb jednowątkowy. W ten sposób unikniemy problemu warunku wyścigu, a w rezultacie nie będzie problemu z gorącym kontem.
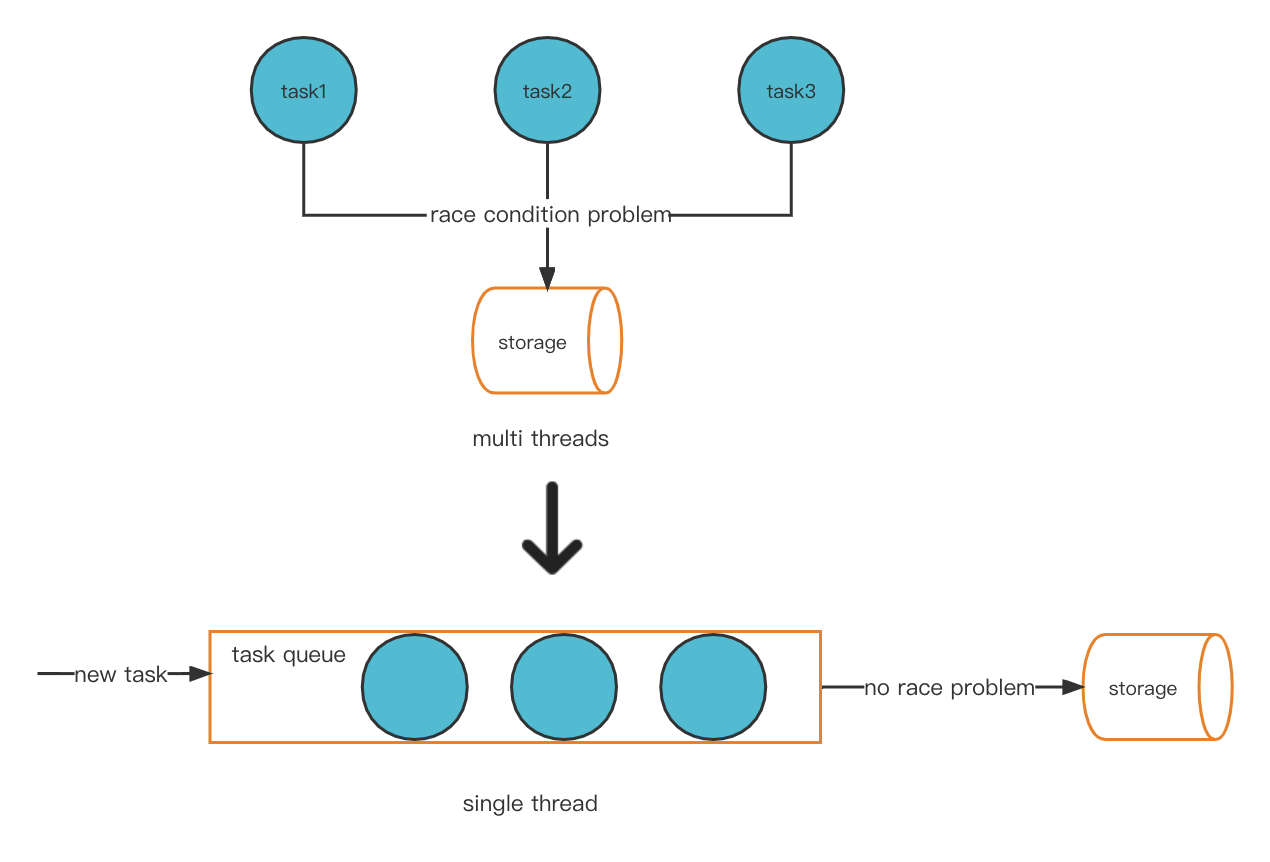
Nowy model wątku
Komunikacja oparta na wiadomościach
Po wdrożeniu naszego nowego modelu wątków, należy rozwiązać problem komunikacji. Warstwa maszyny stanowej jest jednowątkowa, ale warstwa sieciowa jest wielowątkowa, więc jak możemy efektywnie komunikować się między nimi?
Disruptor [1] to kolejny krok w tej układance. Tworzy on kolejkę bez blokad o wysokiej wydajności opartą na projekcie bufora pierścieniowego.
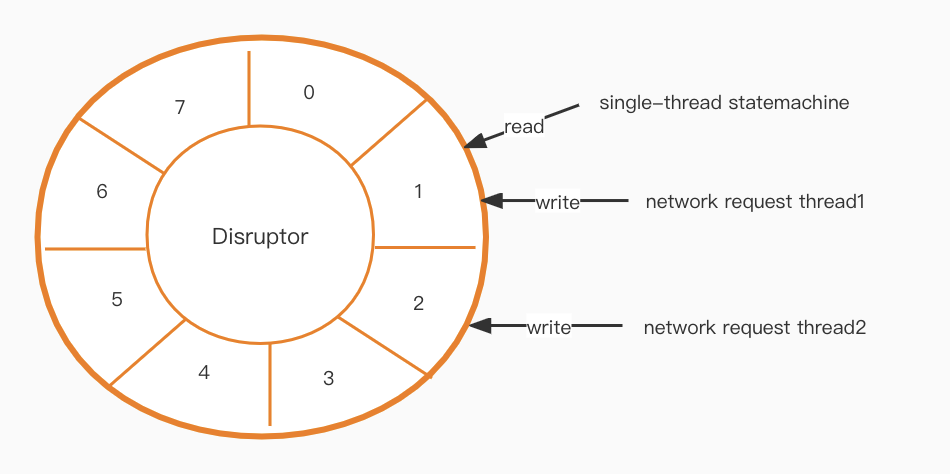
Wysoka dostępność
Do tej pory osiągnęliśmy wysoką wydajność, używając modelu w pamięci i lokalnego magazynu RocksDB [2]. Ale, raz jeszcze, pojawia się nowe wyzwanie. Teraz musimy zadbać o wysoką dostępność danych.
Aby zapewnić spójność danych między węzłami, używamy algorytmu konsensusu Raft [3]. Oznacza to, że liczba kopii zapasowych danych jest równa liczbie obecnych węzłów niebędących węzłami wiodącymi. Algorytm zapewnia również, że system będzie nadal działał, gdy co najmniej połowa węzłów będzie sprawna, co pomoże zapewnić wysoką dostępność usług.
Role domeny Raft:
Lider. Lider przetwarza wszystkie żądania klientów i replikuje operację do wszystkich obserwujących.
Naśladowca. Naśladowcy naśladują lidera we wszystkich operacjach. Jeśli lider zawiedzie, jeden z naśladowców zostanie wybrany na nowego lidera.
Uczący się. Uczący się to niegłosujący obserwujący, którzy wysyłają każdy rekord zmiany idempotentnej/transakcyjnej do innych usług.
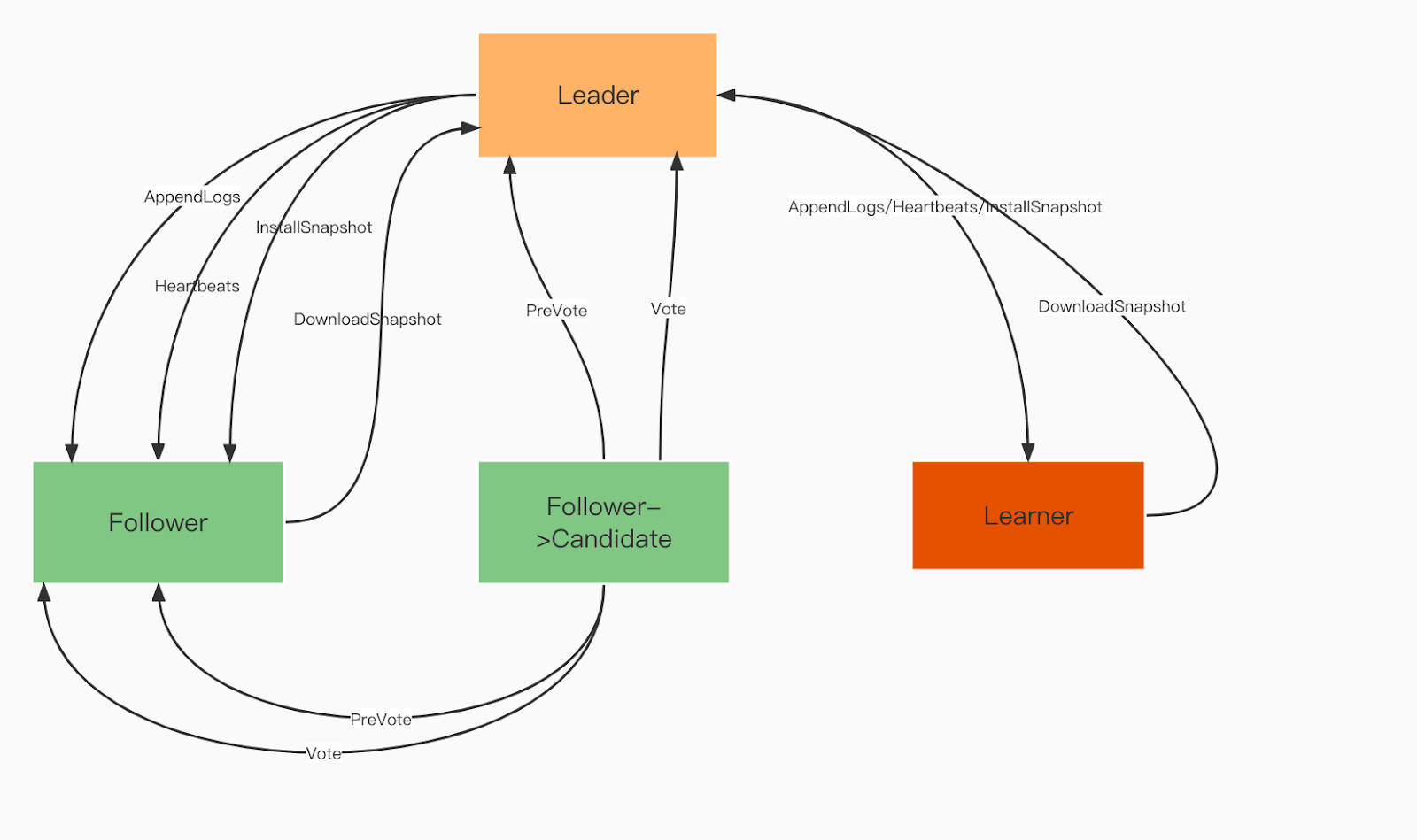
Role domeny Raft
CQRS (Segregacja odpowiedzialności za zapytania poleceń)
Innym kluczowym kryterium, które chcemy zapewnić, jest wyższa wydajność zapisu i zdolność Ledgera do bardziej zróżnicowanych warunków zapytań. W tym celu musimy utworzyć różne domeny. Domena raft zapewnia bardziej wydajny zapis w oparciu o rocksdb+raft, a domena widoku nasłuchuje wiadomości domeny raft i zapisuje je w relacyjnej bazie danych w celu wykonywania zapytań zewnętrznych. Możemy również zaimplementować segregację odpowiedzialności za zapytania poleceń na poziomie architektonicznym.
Architektura księgi głównej
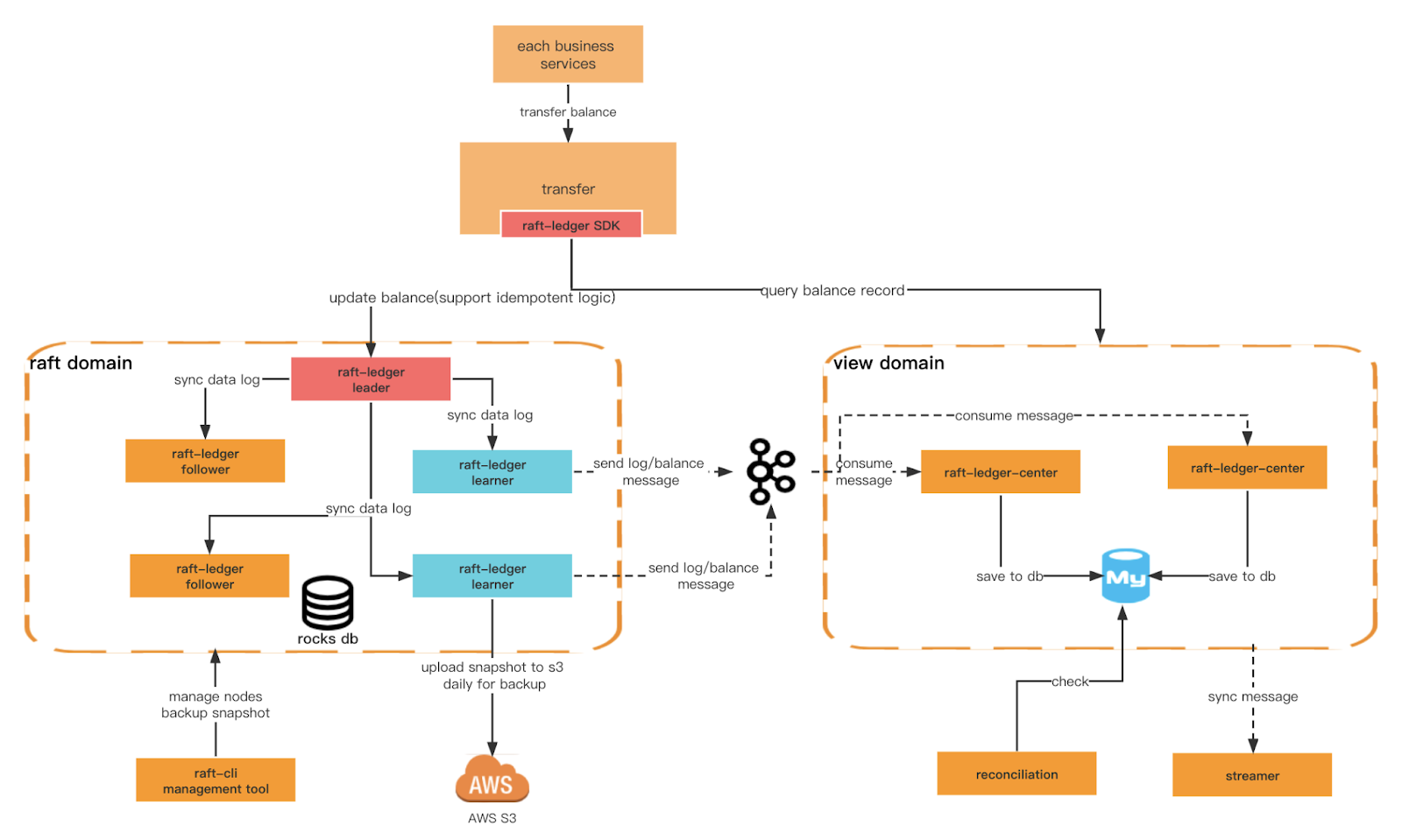
Ogólna architektura
Warunki pomiędzy Raft i Ledger:
tabela-6
Wyświetl role domeny
Centrum księgi tratwy
Przetwarza wiadomość wygenerowaną przez ucznia i zapisuje dane dotyczące transakcji i salda w bazie danych MySQL w celu wykonania zapytania.
Przetwarzanie żądania
Żądanie transakcji najpierw przejdzie przez warstwę sieciową, warstwę księgi głównej (obsługę żądania) i warstwę tratwy (synchronizację dziennika tratwy). Następnie powróci do warstwy księgi głównej (maszyny stanowej), warstwy sieciowej (obsługi odpowiedzi) i na końcu zwróci odpowiedź klientowi.
Dane przesyłane są za pośrednictwem kolejki pomiędzy dwiema warstwami.
Warstwa sieciowa – deserializuj żądanie rpc i umieść je w kolejce żądań.
Warstwa księgi głównej – pobierz żądanie z kolejki i przygotuj kontekst. Następnie umieści metadane żądania w kolejce tratwy.
Warstwa Raft – Pobierz metadane żądania z kolejki Raft i zsynchronizuj je ze wszystkimi obserwującymi. Następnie umieści wynik w kolejce Apply.
Warstwa Ledger – Pobierz dane z kolejki apply i zaktualizuj maszynę stanową. Następnie umieści wynik w kolejce odpowiedzi.
Warstwa sieciowa – pobierz wynik z kolejki odpowiedzi, a następnie skonstruuj i zserializuj dane odpowiedzi przed zwróceniem ich do klienta.
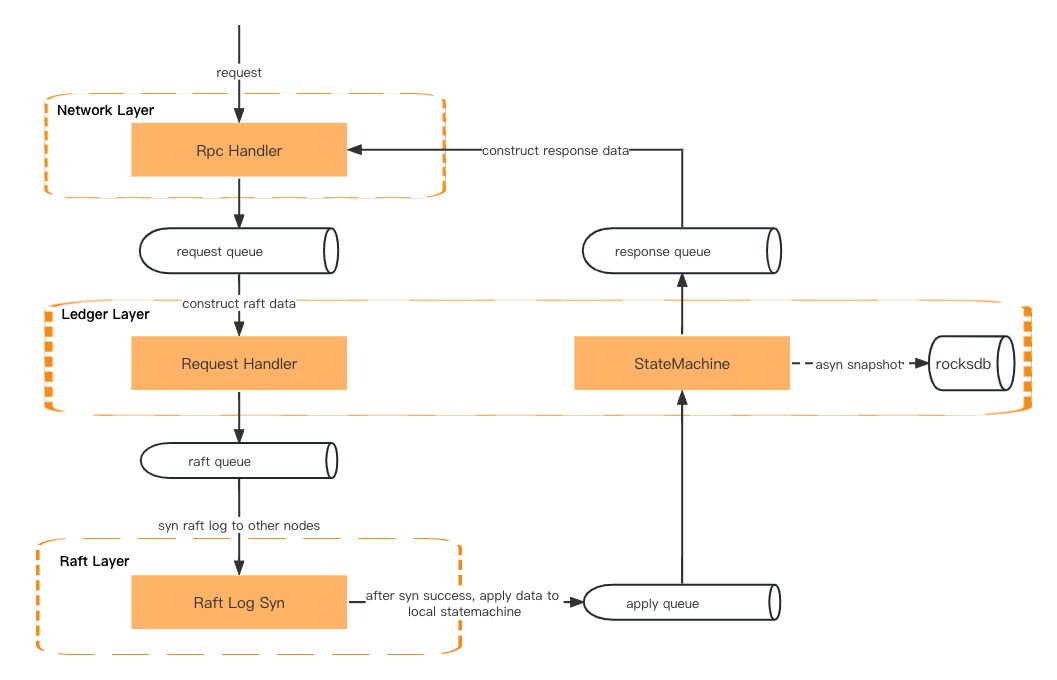
Przetwarzanie żądania
Odzyskiwanie danych
Każdy węzeł Ledger uruchomi ogólną migawkę na podstawie okresu czasu. Ponadto implementujemy również spójną migawkę. Każdy węzeł jest uruchamiany przy tym samym indeksie dziennika tratwy, aby zapewnić, że maszyna stanowa jest dokładnie taka sama, gdy każdy węzeł uruchamia migawkę. Migawka zostanie następnie przesłana do S3 w celu weryfikacji przez Checker i jako zimna kopia zapasowa.
Gdy Ledger się restartuje, odczytuje lokalną migawkę i odbudowuje maszynę stanową. Następnie odtwarza lokalny dziennik tratwy i synchronizuje najnowszy dziennik od lidera, aż dogoni najnowszy indeks. Jeśli lokalna migawka lub dziennik tratwy nie istnieje, zostanie pobrany od lidera.
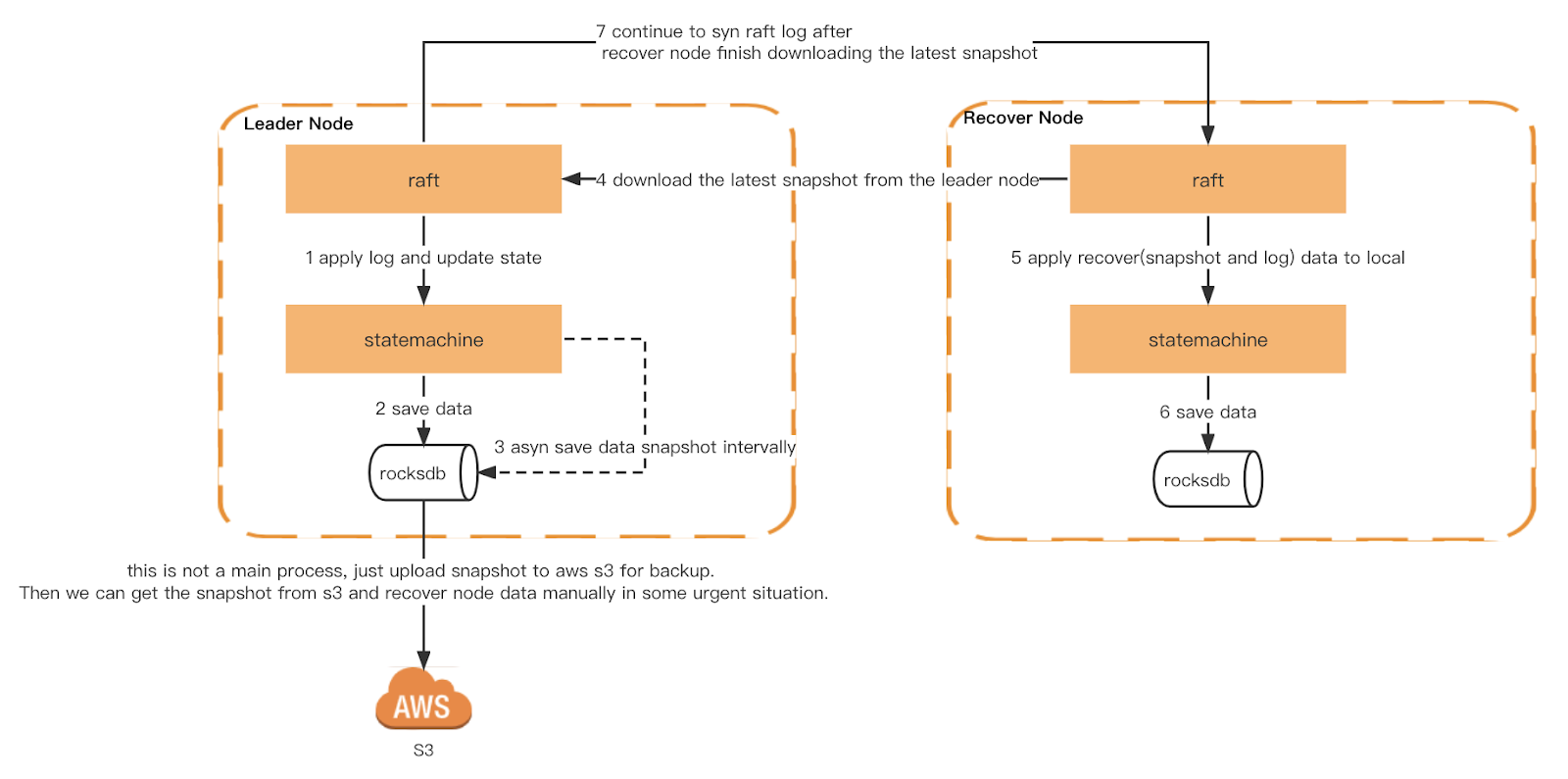
Migawka i odzyskiwanie
Tolerancja na katastrofy
Aby zwiększyć dostępność i odporność na błędy, węzły Ledger są wdrażane w różnych strefach. Jeśli ponad połowa węzłów jest sprawna, dane nie zostaną utracone, a przełączenie awaryjne zostanie ukończone w ciągu jednej sekundy.
Nawet jeśli cały klaster ulegnie awarii, co jest bardzo mało prawdopodobne, nadal możemy odtworzyć klaster za pomocą spójnej migawki zapisanej w usłudze Amazon S3 i odzyskać najnowsze utracone dane za pośrednictwem systemu podrzędnego.
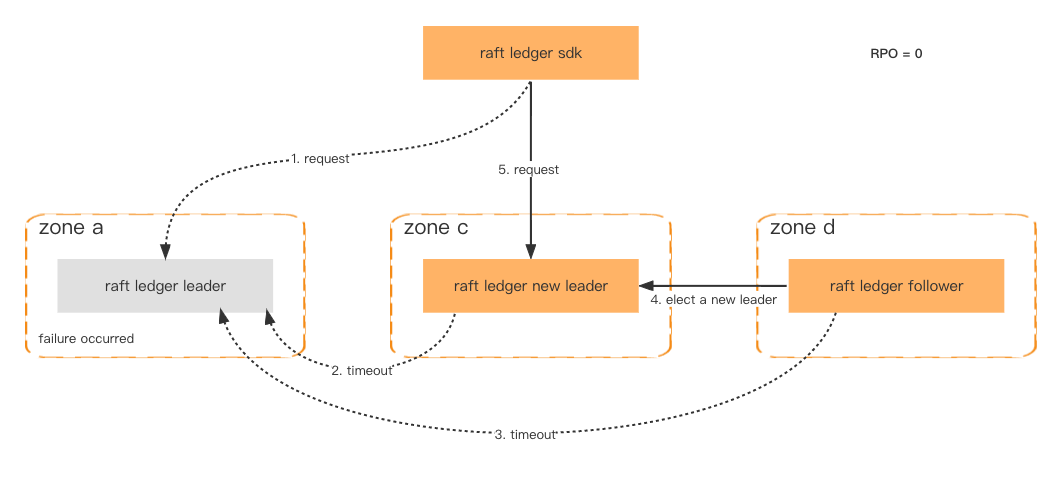
Tolerancja błędów
Wydajność
Poniższa tabela przedstawia specyfikację sprzętu potrzebną do przeprowadzenia testu wydajności
Wewnętrzne testy dowodzą, że klaster 4-węzłowy (jeden lider, dwóch naśladowców i jeden uczący się) może przetworzyć ponad 10 000 TPS. Zgodnie z projektem klaster przetwarza wszystkie transakcje pojedynczo. Nie ma żadnego stanu blokady ani wyścigu. Tak więc w scenariuszu gorącego konta TPS jest tak samo wysoki, jak w normalnych scenariuszach.
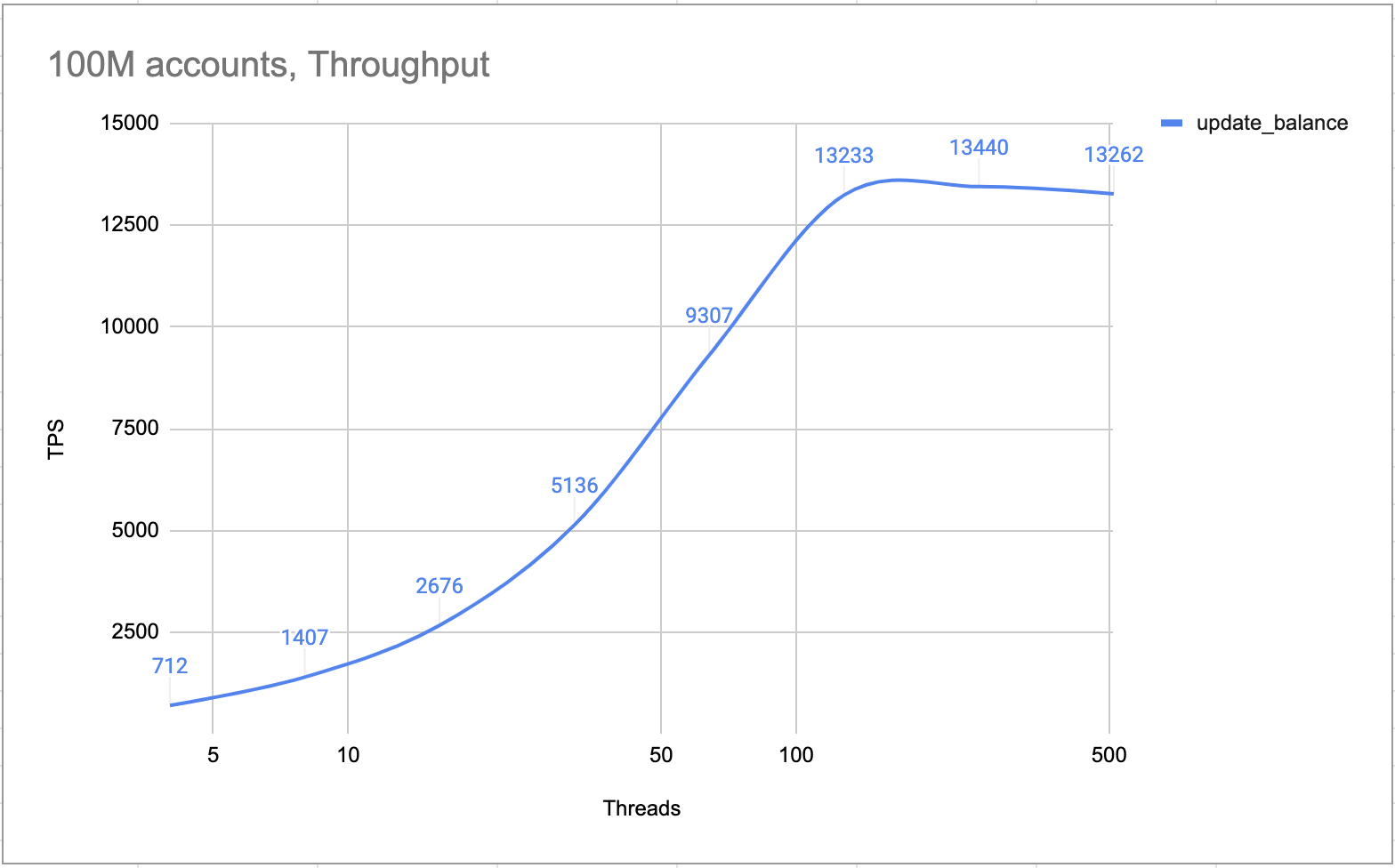
Konto gorące TPS
Poniższy rysunek pokazuje opóźnienie każdej transakcji. Większość transakcji można zakończyć w ciągu 10 ms. Wolniejsze transakcje można zakończyć w ciągu 25 ms.
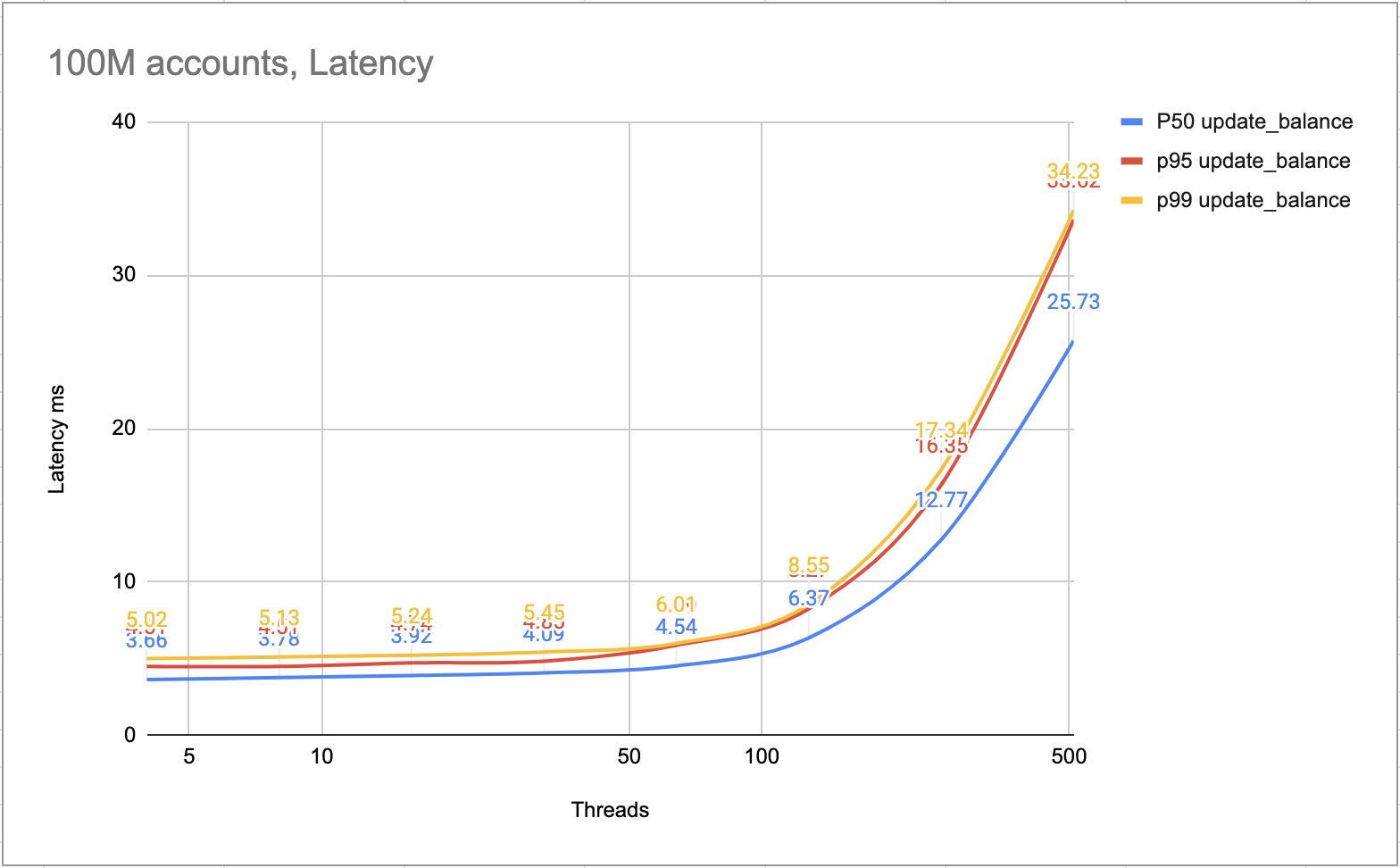
Opóźnienie ms
Zasilanie naszych usług za pomocą Binance Ledger
Jak widać, tradycyjna odpowiedź branży na problem gorących kont nie zaspokaja potrzeb Binance i jej klientów. Dzięki zastosowaniu podejścia zaprojektowanego specjalnie dla infrastruktury Binance, uzyskaliśmy jedno z najpłynniejszych doświadczeń wymiany i produktu. Z przyjemnością dzielimy się teraz z Tobą naszym doświadczeniem i mamy nadzieję, że lepiej zrozumiesz, co składa się na działanie usługi takiej jak Binance.
Aby uzyskać więcej informacji na temat naszej infrastruktury technologicznej, przeczytaj poniższy artykuł:
(Blog Binance) Wykorzystanie MLOps do zbudowania kompleksowego procesu uczenia maszynowego w czasie rzeczywistym
(Binance Blog) Poznaj CTO: Rohit opowiada o kryptowalutach, blockchainie, Web3 i swoim pierwszym miesiącu w Binance
Odniesienia
[1] Zakłócacz LMAX
[2] Baza danych RocksDB
[3] Algorytm konsensusu tratwy