
Obecnie różne projekty web3 opierają się na popularności sztucznej inteligencji.
Szczerze mówiąc, rozwój technologii AI i technologii szyfrowania idzie właściwie w dwóch kierunkach. Być może sztuczna inteligencja rozwiąże problem produktywności, podczas gdy technologia szyfrowania rozwiąże problem dystrybucji.
Były dyrektor techniczny Coinbase i partner A16Z, Balaji, ma klasyczny opis: sztuczna inteligencja służy do tworzenia, szyfrowanie służy do tokenizacji, a społecznościowe służą do dystrybucji.
Jednak dzisiaj, gdy większość projektów AI ma trudności z zarabianiem pieniędzy, przychody z projektów Web3 mogą być nadal odległe, ale tokenizacja zasobów AI może być bardziej odpowiednia.
Obecnie sztuczna inteligencja zużywa głównie trzy zasoby: moc obliczeniową, energię elektryczną i dane.
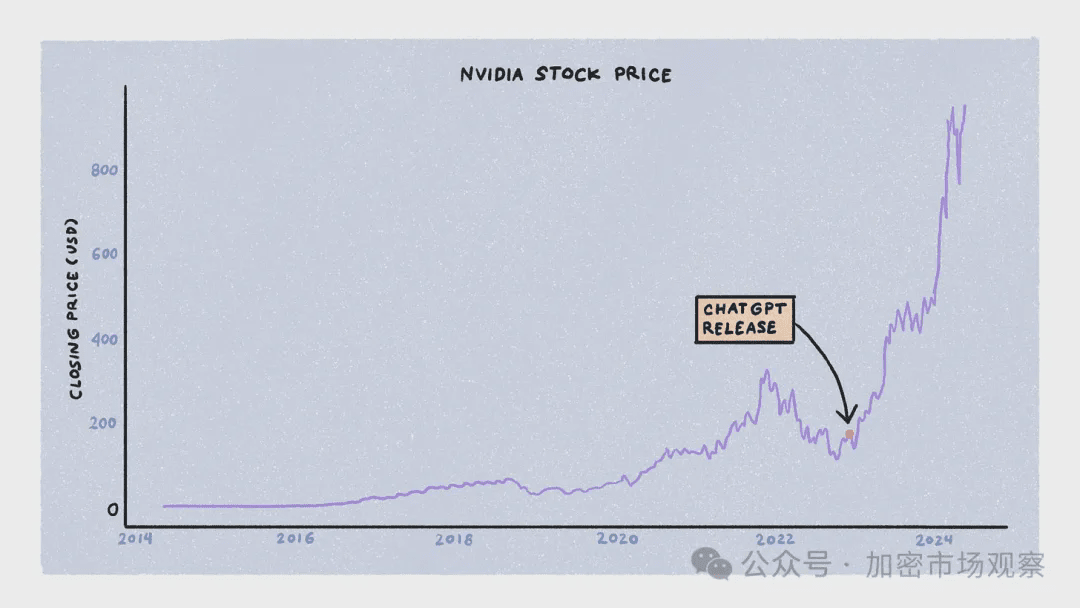
Cena akcji Nvidii rośnie od czasu wydania ChatGPT.
Rozproszona moc obliczeniowa również przyciągnęła wiele uwagi na tegorocznym rynku. Nie tylko stary gigant Render wszedł do łańcucha dostaw Apple, ale w tej rundzie pojawiła się także para wschodzących sił, takich jak IO i Aethir.
Być może udało się wstępnie ustalić schemat gigantów w dziedzinie mocy obliczeniowej.
Dystrybucja zasobów energii może nie mieć nic wspólnego z web3. Sami górnicy Bitcoina szukają na całym świecie taniej energii elektrycznej do budowy kopalń.
Jednak w dziedzinie danych giganci AI od dawna walczą o zasoby danych. Na przykład Google wykupił zasoby danych Raddit za 60 mln dolarów rocznie, a po ogłoszeniu XAI przez Twittera również zaczął ograniczać wywołania API i podnosić ceny.

W dłuższej perspektywie zasoby danych są podstawowym zasobem sztucznej inteligencji, ponieważ moc obliczeniową i energię elektryczną można rozwiązać, wydając pieniądze.
Kiedy tradycyjni giganci technologiczni konkurują o zasoby danych, mogą dać projektom web3 pewne możliwości, ponieważ być może uda im się przełamać te bariery poprzez decentralizację.
Na przykład Grass jest liderem w ścieżce rozproszonych zasobów danych. Rundę zalążkową prowadził Polychain i większość projektów obecnie notowanych na Binance ma ten fundusz.
Zespół Damei miał również szczęście skontaktować się z Andrejem, dyrektorem generalnym Wynd Labs, spółki-matki Grass, obecnie wiodącego projektu rozwiązań danych Web3, w celu przeprowadzenia szczegółowej dyskusji na temat projektu Grass.
Oryginalny tekst wywiadu jest w języku angielskim, a poniżej znajduje się chińskie tłumaczenie:
Duże i piękne:
Witam, czy mógłbyś pokrótce przedstawić siebie i Grass?
Andrzej:
Cześć, nazywam się Andre i jestem dyrektorem generalnym Wynd Labs i głównym współpracownikiem Grassa.
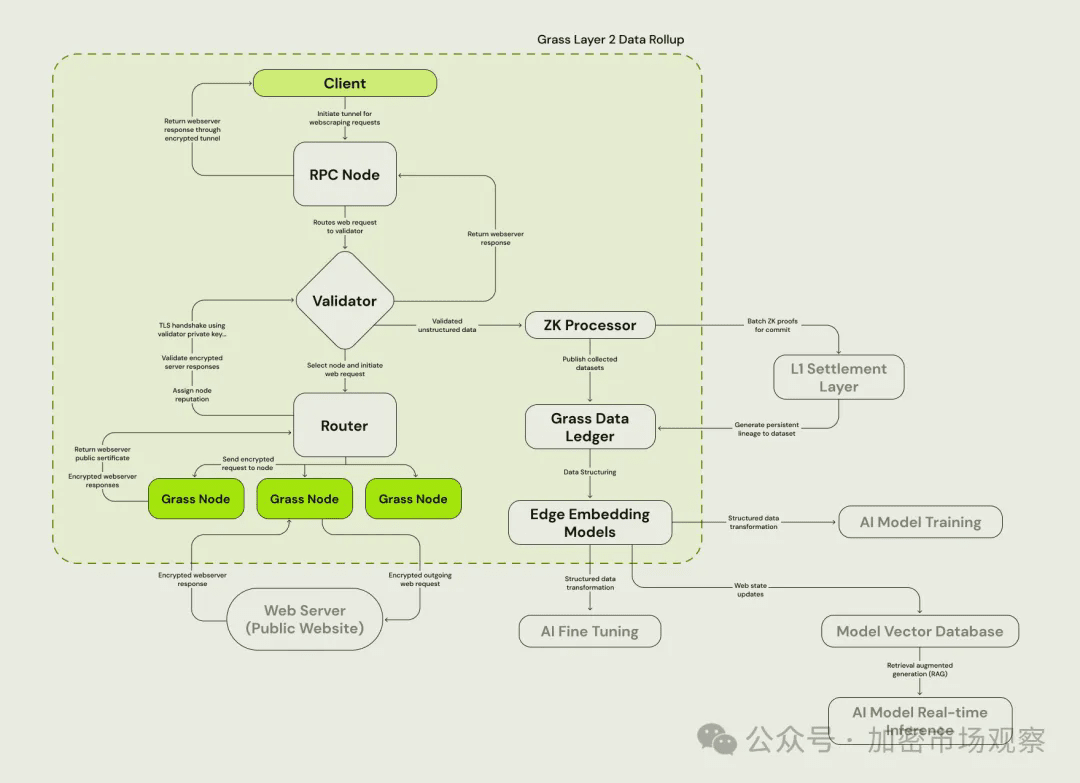
Grass to sieć zrzeszająca ponad 2 miliony osób, które są nagradzane za dzielenie się niewykorzystaną przepustowością Internetu z programistami i modelami AI, które następnie są wykorzystywane do pobierania danych z sieci publicznych z Internetu.
Duże i piękne:
Co się dzieje, gdy ludzie kopią trawę?
Czy możesz wyjaśnić, jaka jest rzeczywista wartość tego zachowania?
Andrzej:
Instalując węzeł Grass, udostępniasz wolne pasmo Internetu, które jest wykorzystywane do zajmowania sieci publicznej.
Należy pamiętać, że Node nigdy nie ma dostępu do Twoich danych osobowych i historii przeglądania.
Dzięki skoordynowanej sieci milionów węzłów Grass jest w stanie pobrać dowolne dane z publicznej sieci i wprowadzić je do modelu sztucznej inteligencji.
Duże i piękne:
Niektórzy członkowie naszej społeczności będą zaniepokojeni bezpieczeństwem swoich danych. Co robi Grass, aby chronić swoje dane?
Andrzej:
Na szczęście nie stanowi to problemu.
Trawa tak naprawdę nie ma nic wspólnego z danymi użytkownika. Sieć ta wykorzystuje niewielką przepustowość, aby uzyskać dostęp do danych sieci publicznej z Internetu.
Oznacza to, że Twoje dane osobowe w ogóle nie będą miały znaczenia.
Aplikacja nie widzi niczego na Twoim komputerze i nie ma wglądu w Twoją aktywność ani zachowanie przeglądarki.
Duże i piękne:
Kto korzysta z usług Cao?
Andrzej:
Ponieważ produkt jest jeszcze w fazie beta, korzysta z niego wyłącznie sam Grass.
Grass wykorzystuje sieć do zbierania danych z sieci publicznej, a następnie przetwarza je w zbiory danych na potrzeby rozwoju sztucznej inteligencji.
Pamiętaj, że każdy model sztucznej inteligencji opiera się na pewnym zbiorze danych szkoleniowych, więc bez niego sztuczna inteligencja po prostu by nie istniała.
Zatem następnym razem, gdy zadasz chatbotowi pytanie, wiedz, że odpowiedź musi skądś pochodzić — w każdym przypadku chatbot pierwotnie czytał informacje ze zbioru danych, na którym został przeszkolony.
Ten zestaw danych pochodzi najprawdopodobniej z Grass.
Duże i piękne:
Członkowie naszej społeczności są ciekawi przyszłego planu działania dla Grass. Jakie informacje możesz nam przekazać?
Na przykład przyszłe plany dotyczące produktów?
Andrzej:
Niedawno Fundacja Grass otworzyła największy zbiór danych Reddit – UpvoteWeb – który zawiera 600 milionów najpopularniejszych postów i komentarzy z Reddita w 2024 r., a także linki do mediów i odpowiedzi.
Teraz dostępny dla wszystkich w Hugging Face, ludzie mogą wykorzystywać ten ogromny i cenny zbiór danych do tworzenia i trenowania modeli sztucznej inteligencji.
Od strony produktowej kończymy aplikację desktopową Grass, która zapewni użytkownikom wyższy wynik sieci w zamian za uruchomienie węzła z silniejszymi połączeniami.
Rozważamy również wprowadzenie funkcji, dzięki której użytkownicy będą mogli uczestniczyć w oznaczaniu danych w celu uzyskania dodatkowych nagród.
Jedną z bardziej ekscytujących będzie aplikacja Grass na Androida, która pojawi się pod koniec trzeciego i czwartego kwartału, co powinno sprawić, że Grass będzie bardziej dostępny dla mas i poprawi czas pracy sieci.
Duże i piękne:
Czy możesz nam powiedzieć więcej o głównym zespole Grass? Skąd wziął się pomysł na Grass?
Andrzej:
W latach 2019–2022 prowadziłem agencję zajmującą się centrami danych web2, gdzie sprzedawaliśmy narzędzia web scraperom.
Częstym problemem związanym z serwerami proxy w centrach danych jest to, że często są one blokowane na stronach internetowych, ponieważ oczywiste jest, że nie są ludźmi.
Wielu klientów zaczęło pytać o lokalne serwery proxy – co jest tym samym produktem, tyle że hostowanym w sieci wielu urządzeń rzeczywistych użytkowników.
Spędziłem dużo czasu, próbując zrozumieć, jak powstają te sieci, a była to wówczas dość niszowa branża, o której niewiele osób wiedziało.
Szokuje mnie, że duże firmy na całym świecie faktycznie nabywają te sieci, przemycając pakiety SDK do bezpłatnych aplikacji użytkowników (w tym telewizorów Smart TV, sieci VPN itp.) i sprzedając ludziom niewykorzystaną przepustowość bez wynagrodzenia.

To jest rozwiązanie dla kryptowalut – umożliwiające użytkownikom wybór wejścia do sieci i nagradzające ich posiadaniem sieci.
Wkrótce po tym, jak wpadłem na ten pomysł, spotkałem moich dwóch współzałożycieli – obaj byli niezwykle bystrzy i byli idealnymi partnerami.
Ich doświadczenie obejmuje handel o wysokiej częstotliwości i sztuczną inteligencję czasu rzeczywistego, a odkąd rozpoczęliśmy współpracę, zakres projektu Grass rozszerzył się dziesięć tysięcy razy.
To, co zaczęło się jako narzędzie programistyczne, stało się warstwą danych.
Szybko zdaliśmy sobie sprawę, że jeśli sieć osiągnie wystarczająco dużą liczbę węzłów, będzie w stanie przeszukać cały Internet w sposób maksymalizujący skumulowaną wartość dla użytkowników.
Duże i piękne:
Co Twoim zdaniem wyróżnia Grass od innych projektów? Czy uważasz, że trawa jest wyjątkowa?
Andrzej:
Dziś na świecie są tylko dwie firmy, które potrafią indeksować dane w skali całego Internetu i w zasadzie są one właścicielami Internetu.
Są to scentralizowane organizacje, które zbudowały fosę w branży, gromadząc zasoby, które powinny należeć do społeczeństwa.
Trawa nie tylko stara się zakłócić to zachowanie, ale także je zastąpić.
Dane internetowe są niezwykle potężnym zasobem i należą do świata.
Niektóre z największych problemów związanych ze sztuczną inteligencją obecnie polegają na tym, że programiści nie mają równego dostępu do danych szkoleniowych, nikt nie może zweryfikować danych do szkolenia AI ze 100% pewnością, a użytkownicy pomagający programistom pobierać zestawy danych z Internetu są niesprawiedliwie wynagradzani ich udział.
Trawa jest obecnie jedyną siecią, która może rozwiązać wszystkie te problemy.
Jest to rozwiązanie całkowicie wyjątkowe i wierzymy, że odegra kluczową rolę w zapewnieniu, że Internet nowej generacji będzie otwarty i uczciwy dla wszystkich stron.

Duże i piękne:
Jest wiele innych powiązanych projektów na tej ścieżce, czy masz jakieś uwagi na ich temat?
Andrzej:
Niektóre z tych projektów mają na celu rozwiązanie bardzo ważnych problemów, takich jak wąskie gardło obliczeniowe w branży sztucznej inteligencji.
Chcemy, aby odnieśli sukces i potencjalnie mogli współpracować z niektórymi z nich.
Dane i obliczenia to dwa niezbędne składniki każdego modelu sztucznej inteligencji, dlatego wiele z tych projektów uzupełnia Grass.
Jeśli jakieś projekty są zainteresowane współpracą z Grassem, zapraszamy do skorzystania z niedawno opublikowanego zbioru danych.
Duże i piękne:
Czas na dzisiejszy wywiad naprawdę mija szybko. Czy jest coś jeszcze, co chciałbyś powiedzieć naszym fanom?
Andrzej:
W najbliższej przyszłości ogłosimy kilka dużych aktualizacji produktów, więc wypatrujcie ich!
Wersja 7.0 będzie dla Grassa bardzo ważna.