

Tytuł oryginalny: „Od GPT-1 do GPT-4, spójrz na rozwój ChatGPT”
Autor oryginalny: Alpha Rabbit Research Notes
Co to jest ChatGPT?

Co to jest ChatGPT?
Niedawno OpenAI wypuściło ChatGPT, model, który może wchodzić w interakcję w sposób konwersacyjny. Ze względu na swoją inteligencję został on pozytywnie przyjęty przez wielu użytkowników. ChatGPT jest także krewnym InstructGPT wydanego wcześniej przez OpenAI. Model ChatGPT jest szkolony przy użyciu RLHF (uczenie się ze wzmocnieniem przy użyciu informacji zwrotnej od ludzi). Być może pojawienie się ChatGPT jest także wstępem przed oficjalnym wprowadzeniem na rynek GPT-4 OpenAI.
Co to jest GPT? Od GPT-1 do GPT-3
Generative Pre-trained Transformer (GPT) to model głębokiego uczenia się generujący tekst, trenowany na danych dostępnych w Internecie. Służy do odpowiadania na pytania, podsumowywania tekstu, tłumaczenia maszynowego, klasyfikacji, generowania kodu i konwersacyjnej sztucznej inteligencji.
W 2018 roku narodził się GPT-1, który był jednocześnie pierwszym rokiem modeli przedtreningowych dla NLP (przetwarzania języka naturalnego). Pod względem wydajności GPT-1 ma pewną zdolność uogólniania i może być stosowany w zadaniach NLP, które nie mają nic wspólnego z zadaniami nadzoru. Typowe zadania obejmują:
Rozumowanie w języku naturalnym: określenie związku pomiędzy dwoma zdaniami (zawarcie, sprzeczność, neutralność)
Pytania i odpowiedzi oraz zdrowy rozsądek: wprowadź artykuł i kilka odpowiedzi i podaj dokładność odpowiedzi
Rozpoznawanie podobieństwa semantycznego: Określ, czy dwa zdania są semantycznie powiązane
Kategoria: Określ, do której kategorii należy tekst wejściowy
Chociaż GPT-1 ma pewien wpływ na niedostrojone zadania, jego zdolność do uogólniania jest znacznie niższa niż w przypadku precyzyjnie dostrojonych zadań nadzorowanych, dlatego GPT-1 można uważać jedynie za całkiem dobre narzędzie do rozumienia języka, a nie za sztuczną inteligencję do konwersacji.
GPT-2 również przybył zgodnie z planem w 2019 r. Jednak GPT-2 nie wprowadził zbyt wielu innowacji strukturalnych i projektów w oryginalnej sieci, wykorzystał jedynie więcej parametrów sieci i większy zbiór danych: maksymalny całkowity model Ma 48 warstw i 1,5 miliarda parametrów Cel uczenia się wykorzystuje model przedszkoleniowy bez nadzoru do wykonywania nadzorowanych zadań. Pod względem wydajności, oprócz zrozumienia możliwości, GPT-2 po raz pierwszy wykazał się dużym talentem generacyjnym: czytanie podsumowań, czatowanie, kontynuowanie pisania, wymyślanie historii, a nawet generowanie fałszywych wiadomości, e-maili phishingowych lub odgrywania ról w Internecie. Nie ma problemu. Po „zwiększeniu się” GPT-2 zademonstrował swoje uniwersalne i potężne możliwości oraz osiągnął najlepszą w tamtym czasie wydajność w wielu specyficznych zadaniach modelowania językowego.
Następnie pojawił się GPT-3 jako model bez nadzoru (obecnie często nazywany modelem samonadzorowanym) może prawie wykonać większość zadań przetwarzania języka naturalnego, takich jak wyszukiwanie zorientowane na problem, czytanie ze zrozumieniem, wnioskowanie semantyczne i tłumaczenie maszynowe. ., generowanie artykułów oraz automatyczne pytania i odpowiedzi itp. Co więcej, model dobrze radzi sobie z wieloma zadaniami, takimi jak osiągnięcie obecnego najnowocześniejszego poziomu w zadaniach tłumaczenia maszynowego francusko-angielskiego i niemiecko-angielskiego. Automatycznie generowane artykuły są prawie niemożliwe do odróżnienia od ludzi i maszyn (tylko 52% dokładności), porównywalne do losowego zgadywania), a jeszcze bardziej zaskakujące jest to, że osiąga prawie 100% dokładności w zadaniach dodawania i odejmowania dwucyfrowego, a nawet może automatycznie generować kod na podstawie opisu zadania. Model bez nadzoru ma wiele funkcji i dobrych efektów i wydaje się, że ludzie widzą nadzieję w ogólnej sztucznej inteligencji. Może to być główny powód, dla którego GPT-3 ma tak duży wpływ.
Czym dokładnie jest model GPT-3?
W rzeczywistości GPT-3 jest prostym modelem języka statystycznego. Z punktu widzenia uczenia maszynowego modele językowe modelują rozkład prawdopodobieństwa sekwencji słów, to znaczy wykorzystują wypowiedziane fragmenty jako warunki do przewidywania rozkładu prawdopodobieństwa różnych słów pojawiających się w następnym momencie. Z jednej strony model językowy może mierzyć stopień zgodności zdania z gramatyką języka (na przykład mierzyć, czy odpowiedź generowana automatycznie przez system dialogu człowiek-komputer jest naturalna i płynna), ale może być również stosowany przewidywać i generować nowe zdania. Na przykład w przypadku klipu „Jest godzina 12:00, chodźmy razem do restauracji” model językowy może przewidzieć słowa, które mogą pojawić się po słowie „restauracja”. Ogólny model języka będzie przewidywał, że następnym słowem będzie „jeść”. Potężny model języka może przechwytywać informacje o czasie i przewidywać słowo „jeść lunch”, które pasuje do kontekstu.
Zwykle to, czy model językowy jest skuteczny, zależy głównie od dwóch punktów: po pierwsze, czy model może wykorzystać wszystkie informacje o kontekście historycznym. W powyższym przykładzie, jeśli nie jest w stanie uchwycić dalekosiężnej informacji semantycznej dotyczącej „godziny 12:00”, to: model językowy prawie nie będzie w stanie przewidzieć następnego razu. Jedno słowo „zjedz lunch”. Po drugie, zależy to również od tego, czy istnieje wystarczająco bogaty kontekst historyczny, aby model mógł się uczyć, czyli czy korpus szkoleniowy jest wystarczająco bogaty. Ponieważ model językowy opiera się na uczeniu się samonadzorowanym, celem optymalizacji jest maksymalizacja prawdopodobieństwa zobaczenia tekstu w modelu językowym, tak aby każdy tekst mógł zostać użyty jako dane szkoleniowe bez etykietowania.
Ze względu na lepszą wydajność GPT-3 i znacznie więcej parametrów, zawiera więcej tekstu tematycznego, co jest oczywiście lepsze niż GPT-2 poprzedniej generacji. Jako największa obecnie dostępna gęsta sieć neuronowa, GPT-3 może konwertować opisy stron internetowych na odpowiednie kody, naśladować ludzkie narracje, tworzyć niestandardowe wiersze, generować skrypty gier, a nawet naśladować zmarłych filozofów - przepowiadających prawdziwy sens życia. A GPT-3 nie wymaga dostrajania, wymaga jedynie kilku próbek typu wyjściowego (niewielka ilość nauki), aby poradzić sobie z trudnymi problemami gramatycznymi. Można powiedzieć, że GPT-3 zdaje się spełniać wszystkie nasze wyobrażenia znawców języków.
Uwaga: Powyższe odnosi się głównie do następujących artykułów:
1. Wkrótce zostanie wydany GPT 4, który jest porównywalny z ludzkim mózgiem. Wielu dużych graczy w branży nie może usiedzieć w miejscu! -Xu Jiecheng, Yun Zhao -Konto publiczne 51 CTO Technology Stack- 2022-11-24 18: 08
2. Odpowiedz na swoją ciekawość dotyczącą GPT-3 w jednym artykule! Co to jest GPT-3? Dlaczego jest taki doskonały? -Zhang Jiajun Institute of Automation, Chinese Academy of Sciences Opublikowano w Pekinie, 11.11.2020, 17:25
3. Partia: 329 |. InstructGPT, bardziej przyjazny i łagodniejszy model językowy - konto publiczne DeeplearningAI-2022-02-07 12: 30
Jakie są problemy z GPT-3?
Jednak GTP-3 nie jest doskonały. Jednym z głównych problemów, których ludzie najbardziej obawiają się w przypadku sztucznej inteligencji, jest to, że chatboty i narzędzia do generowania tekstu prawdopodobnie uczą się wszystkich tekstów w Internecie w sposób masowy i jakościowy. lub nawet generowany jest obraźliwy język, co w pełni wpłynie na ich kolejne zastosowanie.
OpenAI zaproponowało również wydanie w najbliższej przyszłości mocniejszego GPT-4:
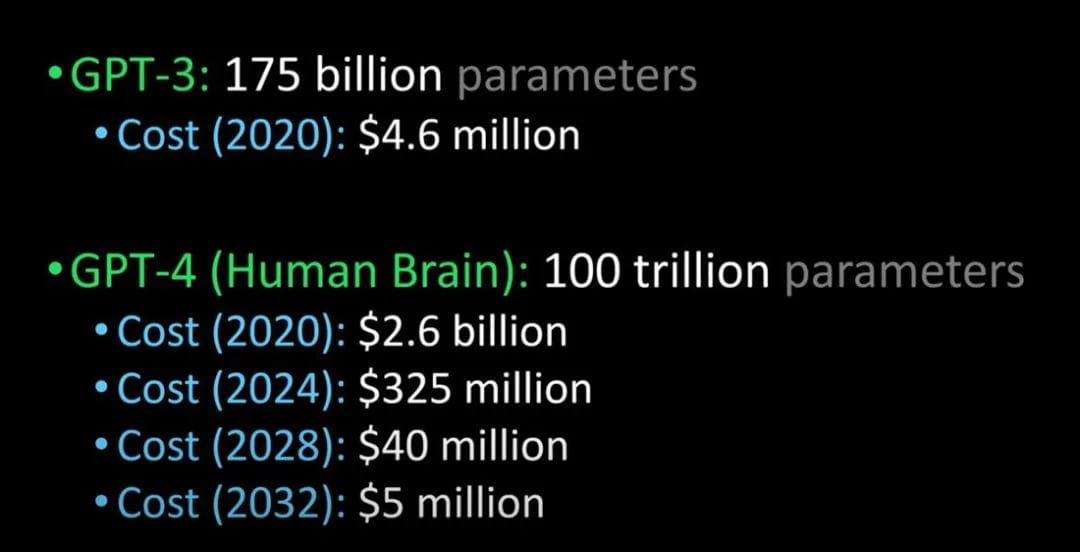
Porównanie GPT-3 z GPT-4 i ludzkim mózgiem (Zdjęcie: Lex Fridman @youtube)
Mówi się, że GPT-4 zostanie wypuszczony na rynek w przyszłym roku. Może przejść test Turinga i być tak zaawansowany, że będzie nie do odróżnienia od człowieka. Ponadto koszty wprowadzenia GPT-4 dla przedsiębiorstw również zostaną znacznie obniżone.
ChatGP i InstructGPT
ChatGPT i InstructGPT
Mówiąc o Chatgpt, musimy porozmawiać o jego „poprzedniku” InstructGPT.
Na początku 2022 roku OpenAI wypuściło InstructGPT; w tym badaniu, w porównaniu z GPT-3, OpenAI wykorzystało badania dotyczące dopasowania do wyszkolenia modelu językowego, który jest bardziej realistyczny, bardziej nieszkodliwy i lepiej zgodny z intencjami użytkownika. InstructGPT jest nowym, dopracowanym rozwiązaniem wersja GPT-3, która minimalizuje szkodliwe, nierealistyczne i stronnicze wyniki.
Jak działa InstructGPT?
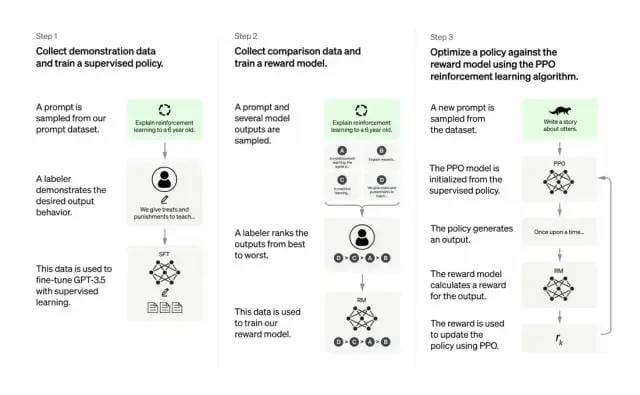
Programiści robią to, łącząc uczenie się nadzorowane z uczeniem się przez wzmacnianie na podstawie informacji zwrotnych od ludzi. Aby poprawić jakość wyjściową GPT-3. W tego typu uczeniu się ludzie oceniają potencjalne wyniki modelu; algorytmy uczenia się przez wzmacnianie nagradzają modele, które wytwarzają materiał podobny do wyników na wysokim poziomie.
Zestaw danych szkoleniowych rozpoczyna się od utworzenia podpowiedzi, z których część opiera się na informacjach od użytkowników GPT-3, takich jak „Opowiedz mi historię o żabie” lub „Wyjaśnij 6-latkowi w kilku zdaniach lądowanie na Księżycu. ”
Twórcy podzielili monit na trzy części i stworzyli odpowiedzi dla każdej części inaczej:
Pisarze-ludzie odpowiadają na pierwszy zestaw podpowiedzi. Twórcy dopracowali wytrenowany GPT-3 i przekształcili go w InstructGPT, aby generować istniejące odpowiedzi na każdy monit.
Następnym krokiem jest wytrenowanie modelu, aby nagradzał lepsze reakcje wyższymi nagrodami. W przypadku drugiego zestawu podpowiedzi zoptymalizowany model generuje wiele odpowiedzi. Osoby oceniające oceniają każdą odpowiedź. Po otrzymaniu podpowiedzi i dwóch odpowiedzi model nagrody (inny wstępnie wytrenowany GPT-3) nauczył się obliczać wyższą nagrodę za wysoko ocenioną odpowiedź i niższą nagrodę za nisko ocenioną odpowiedź.
Twórcy udoskonalili model językowy, korzystając z trzeciego zestawu podpowiedzi i metody uczenia się przez wzmacnianie Proximal Policy Optimization (PPO). Kiedy pojawia się podpowiedź, model językowy generuje odpowiedź, a model nagrody odpowiednio ją nagradza. PPO wykorzystuje nagrody do aktualizacji modelu językowego.
Odniesienie do tego akapitu: The Batch: 329 |. InstructGPT, bardziej przyjazny i łagodniejszy model językowy – konto publiczne DeeplearningAI- 2022-02-07 12: 30
Co jest ważne? Najważniejsze jest to, że sztuczna inteligencja musi być odpowiedzialną sztuczną inteligencją
Model językowy OpenAI może być pomocny w obszarach edukacji, wirtualnych terapeutów, pomocy pisarskich, gier RPG itp. W tych obszarach istnienie uprzedzeń społecznych, dezinformacji i toksycznych informacji jest bardziej kłopotliwe, a systemy, które mogą uniknąć tych wad, mogą być bardziej zdolnym.
Jakie są różnice pomiędzy procesami szkoleniowymi Chatgpt i InstructGPT?
Ogólnie rzecz biorąc, Chatgpt, podobnie jak powyższy InstructGPT, jest szkolony przy użyciu RLHF (uczenie się ze wzmocnieniem na podstawie informacji zwrotnej od ludzi). Różnica polega na tym, jak dane są konfigurowane na potrzeby uczenia (i zbierane). (Wyjaśnienie tutaj: poprzedni model InstructGPT dał dane wyjściowe dla danych wejściowych, a następnie porównał je z danymi szkoleniowymi. Tak, były nagrody, a nie kary; bieżący Chatgpt jest wejściem, a model daje wiele wyników, a następnie ludzie Give To sortowanie wyników wyjściowych pozwala modelowi uszeregować te wyniki od „bardziej ludzkich” do „nonsensownych”, umożliwiając modelowi poznanie sposobu, w jaki sortują ludzie. Strategia ta nazywa się uczeniem nadzorowanym. Dziękuję dr Zhangowi Zijie ten akapit)
Jakie są ograniczenia ChatGPT?
następująco:
a) Podczas fazy uczenia się przez wzmacnianie (RL) nie ma konkretnego źródła prawdy i standardowych odpowiedzi na Twoje pytania.
b) Model jest szkolony, aby był bardziej ostrożny i może odrzucać odpowiedzi (aby uniknąć fałszywie pozytywnych odpowiedzi).
c) Nadzorowane szkolenie może wprowadzić w błąd/wypaczyć model w stronę poznania idealnej odpowiedzi, zamiast generować model losowy zestaw odpowiedzi i tylko osoby oceniające wybierają dobre/najwyżej ocenione odpowiedzi
Uwaga: ChatGPT jest wrażliwy na sformułowania. , czasami model nie odpowiada na frazę, ale po niewielkiej zmianie pytania/wyrażenia udaje mu się odpowiedzieć poprawnie. Trenerzy wolą dłuższe odpowiedzi, ponieważ mogą wydawać się bardziej wyczerpujące, co prowadzi do tendencji do dłuższych odpowiedzi i nadużywania niektórych wyrażeń w modelu. Jeśli początkowa zachęta lub pytanie jest niejednoznaczne, model nie poprosi o odpowiednie wyjaśnienia.
Samodzielnie zidentyfikowane ograniczenia ChatGPT są następujące.
Odpowiedzi brzmiące wiarygodnie, ale niepoprawne:
a) Nie ma prawdziwego źródła prawdy, które pozwoliłoby rozwiązać ten problem podczas fazy szkolenia ze wzmocnieniem (RL).
b) Model uczący większej ostrożności może błędnie odmówić odpowiedzi (fałszywie pozytywny wynik w przypadku kłopotliwych podpowiedzi).
c) Nadzorowane szkolenie może wprowadzać w błąd/stronniczość. Model zwykle zna idealną odpowiedź, a nie model generujący losowy zestaw odpowiedzi i tylko weryfikatorzy wybierają dobrą/wysoko ocenianą odpowiedź.ChatGPT jest wrażliwy na sformułowania. Czasami model kończy się brakiem odpowiedzi na frazę, ale po niewielkiej zmianie pytania/wyrażenia kończy się to tym, że odpowiada na nie poprawnie.
Trenerzy wolą dłuższe odpowiedzi, które mogą wyglądać na bardziej wyczerpujące, co prowadzi do preferowania pełnych odpowiedzi i nadużywania niektórych wyrażeń. Model nie prosi o wyjaśnienia, jeśli początkowa zachęta lub pytanie jest niejednoznaczne. Warstwa bezpieczeństwa umożliwiająca odrzucanie nieodpowiednich próśb za pośrednictwem interfejsu API moderacji Został wdrożony. Jednak nadal możemy spodziewać się odpowiedzi fałszywie negatywnych i pozytywnych.
Bibliografia:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. Wkrótce zostanie wydany GPT 4, który jest porównywalny z ludzkim mózgiem. Wielu dużych graczy w branży nie może usiedzieć w miejscu! -Xu Jiecheng, Yun Zhao -Konto publiczne 51 CTO Technology Stack- 2022-11-24 18: 08
5. Odpowiedz na swoją ciekawość dotyczącą GPT-3 w jednym artykule! Co to jest GPT-3? Dlaczego jest taki doskonały? -Zhang Jiajun Institute of Automation, Chinese Academy of Sciences Opublikowano w Pekinie, 11.11.2020, 17:25
6. Partia: 329 |. InstructGPT, bardziej przyjazny i łagodniejszy model językowy - konto publiczne DeeplearningAI-2022-02-07 12: 30