


Jedną z najpopularniejszych ścieżek w tym roku powinna być ścieżka L2, która zwiększa skalowalność blockchainu. Po pomyślnym wdrożeniu większe prędkości i niższe koszty doprowadzą do stopniowego rozkwitu aplikacji Web3 w przyszłości będzie Magazynowanie oznacza eksplozję popytu. W tym artykule skupimy się na EthStorage, pierwszym miejscu w tegorocznej edycji EDCON Spuer Demo, i omówimy ścieżkę zdecentralizowanej pamięci masowej, która ostatnio cieszy się małą popularnością na rynku, ale ma ogromny potencjał.
1. Proces rozwoju pamięci sieciowych
Konsensus, przetwarzanie danych i przechowywanie są wspólnie określane jako trzy filary i podstawowa infrastruktura web3. Podczas generowania danych i informacji wymagane jest przechowywanie. Od narodzin komputerów technologia przechowywania danych rozwija się poprzez badania i przełomy cztery etapy.
1. Scentralizowane przechowywanie: scentralizowane przechowywanie + scentralizowane zarządzanie
W komputerach po raz pierwszy zapisano dane na taśmie papierowej. Później w 1956 roku IBM wyprodukował pierwszy dysk twardy jako nośnik danych i wprowadził metodę komputerowego przechowywania danych, którą znamy dzisiaj.
Scentralizowane urządzenia pamięci masowej, w tym dyski twarde, taśmy, karty pamięci, dyski SSD itp., podlegają iteracji, ale architektura pamięci masowej jest stała. Urządzenia końcowe mogą uzyskiwać dostęp do zasobów pamięci masowej i żądać danych z nich za pośrednictwem sieci, ale wszystkie zasoby pamięci masowej są skoncentrowane one Ujednolicona kontrola i zarządzanie z centralnej lokalizacji lub serwera.
2. Przechowywanie w chmurze: przechowywanie rozproszone + scentralizowane zarządzanie
W 2006 roku Amazon AWS wszedł w tryb online i uruchomił usługi przechowywania danych w chmurze EC2 i S3. Przechowywanie danych wkroczyło w nową erę. Microsoft, Google, Alibaba itp. również poszły w ich ślady, stając się obecnie najpowszechniej stosowaną metodą przechowywania.
Magazyn w chmurze wykorzystuje rozproszoną architekturę przechowywania, wykorzystuje wiele serwerów do przechowywania danych w sposób zdecentralizowany, dzieli dane na wiele serwerów w celu tworzenia kopii zapasowych, ogranicza pojedyncze punkty awarii i charakteryzuje się zmniejszoną redundancją danych i elastyczną rozbudową. Jednak serwery przechowywania w chmurze są zarządzane centralnie przez dostawców usług w chmurze, a faktyczna kontrola nad danymi nie należy do użytkowników.
3. Tradycyjna pamięć masowa typu blockchain: rozproszona pamięć masowa z pełnym węzłem + zdecentralizowane zarządzanie
Od narodzin Bitcoina, magazynowanie w sieci blockchain stało się rozwiązaniem przeciwnym do scentralizowanego przechowywania i zarządzania. Blockchain zapewnia bezpieczeństwo danych i brak ich fałszowania poprzez rozproszone przechowywanie, mechanizm konsensusu i mechanizm weryfikacji transakcji, spełniając jednocześnie wymagania. Posiada cechy charakterystyczne. zdecentralizowanego przechowywania i zdecentralizowanego zarządzania.
Jednak sieci blockchain, takie jak Bitcoin i Ethereum, charakteryzują się wysokimi kosztami przechowywania i niską wydajnością. Głównym powodem jest to, że architektura sieci tych łańcuchów bloków nie jest zaprojektowana z punktu widzenia przechowywania. Każdy węzeł musi przechowywać kopię danych, a przestrzeń blokowa jest taka ograniczony. Biorąc za przykład Boring Ape NFT, przechowywanie takiego w sieci Bitcoin lub Ethereum kosztuje co najmniej kilkaset dolarów.

4. Zdecentralizowana pamięć masowa Web3: rozproszona pamięć masowa z wieloma węzłami + zdecentralizowane zarządzanie
Ponieważ przechowywanie danych bezpośrednio na blockchainie jest bardzo drogie, pojawiło się wiele rozwiązań i projektów zdecentralizowanego przechowywania danych web3, takich jak IFPS, Filecoin, Storj, Arweave, Swarm, EthStorage itp. Celem tych projektów jest utrzymanie decentralizacji Na rynku w oparciu o scentralizowaną pamięć masową i zarządzanie, zwiększenie przestrzeni dyskowej i zmniejszenie kosztów osiąga się dzięki połączeniu technologii, takich jak segmentacja danych, wielowęzłowe przechowywanie danych i certyfikacja w łańcuchu.
2. Modułowość ETH i komputer świata
1. Modularyzacja ETH
Ponieważ ETH zaplanowała plan działania skupiony na Rollupie w 2021 r., rozpoczęto tworzenie modularyzacji Ethereum, dzieląc każdą warstwę pojedynczego wszechmocnego łańcucha (*monolityczny łańcuch bloków), a funkcjami różnych warstw można zarządzać przez różne. Ekspansja jest przeprowadzana w oparciu o odpowiedzialność modułów lub łańcuchów Kierunek ten nazywany jest także grą końcową przez Vitalika.
Blockchain reprezentowany przez Ethereum dzieli łańcuch na cztery kluczowe poziomy:
(1) Warstwa wykonawcza (*Warstwa wykonawcza): przetwarzanie transakcji, realizacja i obliczanie inteligentnych kontraktów itp.
(2) Warstwa rozliczeniowa (*Warstwa rozliczeniowa): Weryfikacja wyników realizacji, rozstrzyganie sporów i rozliczanie zobowiązań dotyczących statusu rozliczenia.
(3) Warstwa konsensusu (*Warstwa konsensusu): określa kolejność i ważność transakcji oraz spójność pomiędzy węzłami
(4) Warstwa dostępności danych (*warstwa dostępności danych): zapewnia możliwość wykorzystania, przechowywania i weryfikacji danych
Podczas łączenia monolitycznego łańcucha bloków łańcuch bloków jest łańcuchem, który obsługuje wszystkie cztery funkcje i zmierzy się z „trilematem” łańcucha bloków. Modułowość Blockchain może podzielić cztery funkcje na wiele wyspecjalizowanych warstw w celu rozwiązania różnych problemów.
Po modułyzacji ETH główny łańcuch ETH stał się L1, na którym narodziło się wiele L2, służących głównie jako warstwa wykonawcza ETH. Na przykład technologia L2 OP Stack opracowała również architekturę modułową, aby zwiększyć przyszłą niezawodność. Kierując się kierunkiem modularyzacji + Rollup, ETH będzie w przyszłości głównie utrzymywać warstwę dostępności danych (*DA) i warstwę konsensusu, stając się główną i najbezpieczniejszą warstwą podstawową. Funkcje innych warstw zostaną zmodernizowane za pośrednictwem innych łańcuchów i rozwiązań przeprowadzić całą ekologiczną rozbudowę ETH i poprawić skalowalność.
2. Komputer Świata
Celem Ethereum jest zbudowanie światowego superkomputera. Obecnie Ethereum radzi sobie bardzo dobrze pod względem bezpieczeństwa, jednak wciąż dokonuje przełomów w zakresie skalowalności. Rollup jest ważnym kierunkiem rozwiązania problemu skalowalności, a podejście modułowe może to rozwiązać w pewnym stopniu trzy problemy związane z blockchainem, ale bycie superkomputerem musi także stawić czoła trzem problemom, a mianowicie konsensusowi, obliczeniom i przechowywaniu. Te trzy problemy również ograniczają się nawzajem.

Różne priorytety tego trylematu spowodują różne kompromisy:
Silna księga konsensusu: zasadniczo wymaga wielokrotnego przechowywania i obliczeń, więc nie nadaje się do rozszerzania pamięci i obliczeń.
Duża moc obliczeniowa: Konsensus musi zostać ponownie wykorzystany podczas wykonywania dużej liczby obliczeń i zadań dowodowych, dlatego nie nadaje się do przechowywania na dużą skalę.
Duże możliwości przechowywania: konsensus musi zostać ponownie wykorzystany podczas wykonywania częstych prób losowych w przestrzeni próbnej, dlatego nie nadaje się do obliczeń.
Obecnie tradycyjne rozwiązania L2 w dalszym ciągu borykają się z problemem zrównoważenia scentralizowanych sortowników i wydajności obliczeniowej i nie są w stanie zapewnić dużych możliwości przechowywania. Autorzy artykułu „W stronę superkomputera światowego” zaproponowali sposób rozwiązania trzech dylematów stania się komputerem światowym poprzez podzielenie komputera światowego według funkcji jako podstawowej architektury i oddzielne ich rozbudowę.
Oznacza to, że ostateczny superkomputer światowy będzie składał się z trzech topologicznie heterogenicznych sieci P2P. Podobnie jak w przypadku budowy komputera fizycznego, księga konsensusu, sieć obliczeniowa i sieć pamięci masowej zostaną połączone za pośrednictwem magistral (*złączy) typu „trustless”, takich jak technologia oparta na wiedzy zerowej. i zmontowane w światowy superkomputer. Inne komponenty można dodać w zależności od potrzeb konkretnych aplikacji. Odpowiedni dobór i połączenie każdego komponentu pozwoli osiągnąć równowagę trylematu księgi konsensusu, mocy obliczeniowej i pojemności pamięci, ostatecznie zapewniając decentralizację, wysoką wydajność i bezpieczeństwo superkomputerów na świecie. . Wśród nich EthStorage służy jako rozwiązanie dla sektora przechowywania danych w superkomputerach w architekturze.
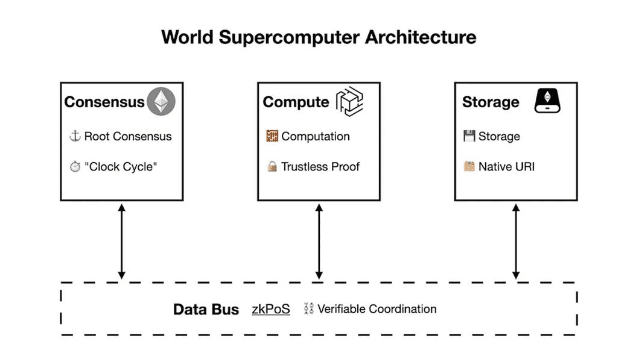
Jeśli zostanie oparty na tym frameworku, proces transakcyjny światowego superkomputera Ethereum zostanie podzielony na następujące kroki:
(1) Konsensus: użyj Ethereum do przetwarzania i osiągania konsensusu transakcyjnego.
(2) Obliczenia: Sieć zkOracle wykonuje odpowiednie obliczenia poza łańcuchem, szybko weryfikując dane dowodowe i konsensusowe dostarczone przez zkPoS jako magistralę.
(3) Konsensus: W niektórych przypadkach, takich jak automatyzacja i uczenie maszynowe, sieć komputerowa będzie przekazywać dane i transakcje z powrotem do Ethereum lub EthStorage w formie dowodów.
(4) Przechowywanie: Do przechowywania dużych ilości danych z Ethereum (*takich jak metadane NFT) zkPoS działa jako komunikator między inteligentnymi kontraktami Ethereum a EthStorage.

3. Przechowywanie ETH
1. Wstęp
EthStorage to pierwsze dwuwarstwowe rozwiązanie zapewniające programowalną dynamiczną pamięć masową w oparciu o dostępność danych Ethereum (*dostępność danych). Może rozszerzyć programowalną pamięć kosztem od 1/100 do 1/1000 razy do setek terabajtów, a nawet petabajtów.
Zespół dwukrotnie zdobył wsparcie finansowe od Fundacji Ethereum (*Grant), aby pomóc Ethereum w przeprowadzeniu badań nad dostępnością danych (*Data Availability) i dowodem przechowywania dynamicznego zbioru danych L2 przy użyciu kontraktów Ethereum L1. I zdobył pierwsze miejsce w demonstracji EDCON Spuer 2023.
2. Charakterystyka techniczna
(1) Wysoce zintegrowany ETH
Klient EthStorage jest nadzbiórem klienta Ethereum Geth, co oznacza, że po uruchomieniu węzła EthStorage może on nadal normalnie uczestniczyć w dowolnym procesie Ethereum. Węzeł może być węzłem walidacyjnym Ethereum, a także węzłem danych EthStorage . Moduł dostawcy danych każdego węzła EthStorage zainicjuje żądanie połączenia z dostawcą danych innego węzła EthStorage. Kiedy są one ze sobą połączone, w rzeczywistości tworzą zdecentralizowaną sieć pamięci masowej.

Użytkownicy korzystający z EthStorage mogą bezpośrednio używać istniejących portfeli do interakcji ze wszystkimi aplikacjami opartymi na pamięci masowej, niezależnie od tego, czy są to NFT, zdecentralizowane sieci społecznościowe czy zdecentralizowane gry, co może zminimalizować czas potrzebny użytkownikowi na osiągnięcie progu EthStorage. Jednocześnie EthStorage kompatybilny z EVM może zapewnić doskonałą interoperacyjność dla inteligentnych kontraktów. Na przykład użytkownik A chce ustawić obraz dla swojego miętowego NFT. Za pośrednictwem Ethstorage A musi jedynie wykonać transakcję Ethereum. Korzystając z Arweave, A One Arweave należy przesłać transakcję i dwie transakcje Ethereum i nie ma możliwości wykonania ich synchronicznie, jak w przypadku EthStorage.

(2) Zdecentralizowane rozwiązanie L2 oparte na warstwie DA
EthStorage w rzeczywistości wykorzystuje architekturę podobną do L2. Umowa dotycząca przechowywania zostanie wdrożona w Ethereum jako wejście do operacji na danych EthStorage. Jednocześnie potrzebny jest również dowód przechowywania danych poza łańcuchem węzła danych (*dane przechowywania poza łańcuchem). zostać zweryfikowane w ramach niniejszej umowy.
Porównanie z obecnym L2:
Rollup (L2) przechowuje drzewo stanów poza łańcuchem, a zobowiązanie (*zaangażowanie) w łańcuchu jest korzeniem drzewa stanów. Jednocześnie po otrzymaniu nowych danych Rollup musi wykonać transakcje poza łańcuchem, aby zakończyć stan proces transformacji i ustanowienie nowego drzewa stanów;
EthStorage przechowuje dane poza łańcuchem, a zobowiązanie (*zaangażowanie) w łańcuchu jest dowodem przechowywania danych. Jednocześnie po otrzymaniu przez EthStorage żądania aktualizacji przechowywanych danych, ponownie wygeneruje nowy dowód przechowywania danych. .
Jak widać z powyższego, kierunkiem rozwoju obecnego pakietu Optimism Rollup lub ZK-Rollup jest zwiększenie mocy obliczeniowej Ethereum, natomiast kierunkiem rozwoju EthStorage Rollup jest zwiększenie pojemności przechowywania danych Ethereum.
Jednocześnie EthStorage jest modułową warstwą pamięci masowej, o ile istnieje EVM i DA w celu zmniejszenia kosztów przechowywania, można ją uruchomić na dowolnym łańcuchu bloków (*ale obecnie wiele warstw 1 nie ma warstwy DA), nawet na warstwie 2. . Na przykład firma EthStorage rozważa obecnie wykorzystanie swojej technologii do wdrożenia zabezpieczenia przed oszustwami w witrynie Optimism. Odpowiednia warstwa DA jest również włączona w Optymizmie.
(3) Można osiągnąć przechowywanie dynamiczne
Z punktu widzenia architektury systemu Filecoin i Arweave są częściej wykorzystywane do celów statycznych. Duże ilości danych można przesyłać do zdecentralizowanej pamięci masowej, ale nie można ich modyfikować ani usuwać, a nowe dane można jedynie ponownie przesłać. Dzięki paradygmatowi przechowywania klucz-wartość EthStorage może obsługiwać CRUD, czyli tworzyć nowe dane magazynu, aktualizować dane magazynu, odczytywać dane magazynu i usuwać dane magazynu. Jest to łatwe do osiągnięcia w dziedzinie scentralizowanego przechowywania, ale w dziedzinie zdecentralizowanego przechowywania obecnie może to zrobić tylko EthStorage.

(4) Utwórz protokół dostępu do sieci Ethereum
Szereg zachowań, takich jak przeglądanie stron internetowych, wysyłanie e-maili, pobieranie plików itp. w Internecie Web2, jest nierozerwalnie związanych z protokołem HTTP. Jest to jeden z najpopularniejszych protokołów w Internecie. Protokół HTTP definiuje sposób przesyłania i wymiany zasobów pomiędzy klientami i serwerami, a adresy URL to identyfikatory określające lokalizację tych zasobów w Internecie. Po wprowadzeniu adresu URL do przeglądarki internetowej lub kliknięciu łącza uruchamiane jest żądanie HTTP, które na podstawie adresu URL określa żądany zasób. Przeglądarka internetowa analizuje adres URL, następnie komunikuje się z serwerem za pomocą protokołu HTTP, żąda określonego zasobu i wyświetla zasób użytkownikowi po odpowiedzi serwera. Protokół HTTP i adresy URL ściśle ze sobą współpracują, tworząc podstawę przeglądania, interakcji i przesyłania zasobów w Internecie. Jednakże dane stron internetowych Web2 lub usług internetowych są hostowane na scentralizowanych serwerach. Jeśli przestaniesz odnawiać serwer, usługa w chmurze używana przez aplikację zostanie zatrzymana, a dane aplikacji zostaną usunięte przez scentralizowanego dostawcę usług.
Założyciel EthStorage, Zhou Zhou, zaproponował protokół dostępu do sieci oparty na Web3 — ERC-4804, który przeszedł ostateczny przegląd i zatwierdzenie EIP. ERC-4804, pełna nazwa to Adres URL Web3 do interpretacji informacji o wywołaniach EVM. Jest to adres URL Web3 (*web3://) w stylu HTTP służący do wywoływania informacji EVM. Jest to pierwszy protokół dostępu do sieci w Ethereum. W odróżnieniu od sposobu, w jaki web2 uzyskuje dostęp do zasobów serwera, protokół web3:// Access bezpośrednio renderuje zasoby hostowane w inteligentnej umowie Ethereum za pośrednictwem adresu URL Web3, w tym plików takich jak HTML, CSS, PDF itp.
Mówiąc najprościej, web3:// (*http://web3url.io) to zdecentralizowany http://. Dodaje zdecentralizowaną warstwę prezentacji do Ethereum, umożliwiając użytkownikom bezpośrednie przeglądanie treści internetowych na EVM, takich jak strony internetowe, zdjęcia, piosenki itp., A EVM służy jako zdecentralizowany backend.

3. Obecna sytuacja i plan
(1) Zastosowanie produktu
Dzięki EthStorage możliwe będzie ponowne włączenie aplikacji internetowych ze zdecentralizowaną pamięcią masową jako dolną warstwą (*Wiele Dappów nadal używa scentralizowanych metod do przechowywania danych), takich jak dynamiczne NFT, muzyczne NFT w łańcuchu, osobiste strony internetowe, portfele bez hosta, i Dapps i in.

Weźmy na przykład DeWeb:
Wiemy, że Ethereum jest siecią zdecentralizowaną. Wiele zdecentralizowanych dappów narodziło się w Ethereum. Jednakże frontony wielu aplikacji nadal są hostowane za pośrednictwem scentralizowanych usług w chmurze, takich jak strona internetowa Uniswap przestoje, usunięcie par handlowych i dezaktywacja usług front-end Tornado.Cash z powodu podejrzeń o nadzór nad praniem pieniędzy itp. wynikają z tego, że front-end jest hostowany na scentralizowanym serwerze i nie może skutecznie oprzeć się cenzurze. Jednak dzięki rozwiązaniu EthStorage pliki i dane stron internetowych są hostowane w inteligentnych kontraktach oraz wspólnie zarządzane i utrzymywane przez zdecentralizowaną sieć, co znacznie zwiększa odporność na cenzurę. Wdrożenie DeWeb poprzez programowalność inteligentnych kontraktów może umożliwić powstanie wielu interesujących aplikacji, takich jak De-github, De-blog i interfejsy różnych dappów.
Obecnie EthStorage nie ogłosił planu tokenów, ale sieć testowa może korzystać z sieci testowej i wchodzić z nią w interakcję za pośrednictwem tokena testowego W3Q.
(2) Plan działania
Zgodnie z planem działania ogłoszonym przez EDCON, w 2023 roku EthStorage będzie głównie na etapie sieci testowej i dostosuje się do aktualizacji Ethereum Cancun w celu rozwoju i testów. Sieć główna może zostać uruchomiona w 2024 r., a dostęp do Danksharding, klienta CL+EL i przeglądarki Web3 zostanie w pełni zintegrowany.

4. Szybki przegląd innych projektów magazynowych
(1) Filecoin: Filecoin to zdecentralizowana sieć pamięci masowej z systemem motywacyjnym opartym na IPFS. IPFS wykorzystuje rozproszoną tablicę skrótów (*DHT), która jest protokołem do przechowywania, adresowania i przesyłania danych (*analogicznie do protokołu http). Filecoin działa jako warstwa motywacyjna dla IPFS, a także działa jako otwarty rynek pamięci masowej. Filecoin wykorzystuje model oparty na umowie, aby zapewnić trwałość danych i zawiera dowody o wiedzy zerowej, w szczególności dowody czasoprzestrzenne i dowody replikacji. 14 marca tego roku Filecoin ogłosił oficjalne uruchomienie maszyny wirtualnej (*FVM) obsługującej inteligentne kontrakty i programowalność użytkownika.
Charakterystyka Filecoina to: ma oddzielny łańcuch i system motywacyjny; ma dużą statyczną przestrzeń dyskową i niski koszt; obsługuje maszynę wirtualną FVM po aktualizacji;
(2) Arweave: Arweave przyjmuje model „zapłać raz, przechowuj na zawsze”, w którym jednorazowa płatność pokrywa koszt trwałego przechowywania danych i nie są pobierane żadne dodatkowe opłaty za odzyskanie danych. Arweave wykorzystuje zwięzły dowód losowego dostępu, aby utworzyć natywną strukturę danych *Blockweave, to znaczy każdy blok jest powiązany z poprzednim blokiem i historycznym blokiem przywołania. W przypadku węzłów warunkiem wstępnym rzutowania nowego bloku jest zsynchronizowanie bloku Recall-Block i ostatnio wygenerowanych danych bloku.
Cechy charakterystyczne Arweave to: oddzielny łańcuch i system motywacyjny; przechowywanie w łańcuchu i trwałe przechowywanie oraz słaba interoperacyjność z innymi sieciami;
(3) BNB Greenfield: Greenfield koncentruje się na promowaniu zdecentralizowanego zarządzania danymi i dostępu do nich, mając na celu uproszczenie przechowywania danych i zarządzania nimi oraz połączenie własności danych ze środowiskiem DeFi BNB Smart Chain (*BSC). Kompletny system BNB Greenfield może współpracować z dojrzałą siecią publiczną BSC i użytkownikami społeczności BN. Gdy użytkownicy chcą tworzyć i wykorzystywać dane w Greenfield, mogą komunikować się z rdzeniem BNB Greenfield za pośrednictwem infrastruktury BNB Greenfield dApps (*aplikacje zdecentralizowane) w celu interakcji.
Cechy charakterystyczne BNB Greenfield to: ostatnia zagadka sieci ekologicznej „Trinity” Binance, silna funkcjonalność w ekosystemie oraz przenoszenie i wykorzystywanie BNB w różnych łańcuchach przy wykorzystaniu koncepcji strukturalnej „wiadra” Amazon S3; weryfikacja na łańcuchu.
5. Podsumowanie
Pamięć masowa jest jednym z trzech filarów sieci Web3 tylko wtedy, gdy możliwe jest wdrożenie zdecentralizowanego przechowywania, możliwe jest rzeczywiste potwierdzenie danych i suwerenna sieć. W przeciwnym razie rozwijanie sieci blockchain kosztem wydajności centralizacji nie ma większego sensu. Utwór ten należy do podstawowego założenia, ma potencjał i ma ogromne znaczenie.
Obecnie w porównaniu z innymi torami magazyn zdecentralizowany jest mniej popularny na rynku. Wynika to głównie z faktu, że nie osiągnął jeszcze etapu rozwoju i brakuje na niego popytu. Kiedy rozwój L2 sprawi, że zastosowanie Dapp będzie tanie i szybkie, nagromadzenie dużych ilości danych i wymagań co do wartości spowoduje zainteresowanie rynku zdecentralizowaną ścieżką przechowywania.
Jako powstający projekt EthStorage ma dobre podstawy ekologiczne w Ethereum i ma silną interoperacyjność. Można go łączyć z innymi warstwami L1 i L2 z DA, aby zapewnić nowe kierunki rozwoju i rozwiązania. Obecnie każdy projekt zdecentralizowanego magazynowania ma swój główny cel i stale się rozwija. Z niecierpliwością czekamy na epokę, w której rynek przesunie się na ścieżkę magazynowania.
Bibliografia
1. Oficjalny EthStorage
2. „W stronę światowego superkomputera”, Xiaohang Yu, Kartin, msfew — Hyper Oracle, Qi Zhou — ETHStorage
3. „EthStorage — pierwszy magazyn Ethereum L2”, 0xhhh, 0xCryptolee
4, „Zdecentralizowana pamięć masowa: filar sieci Web 3”, „Fundamental Labs”
5. „Modularny łańcuch bloków: rozwiązanie inżynieryjne dla Ethereum, aby stać się „komputerem światowym””, IOBC Capital
6. „EthStorage: Zwiększanie wydajności pamięci masowej ekosystemu Ethereum”, Mint Ventures
strona internetowa: ldcap.com
medium: ld-capital.medium.com