
Stability AI savā emuārā ir izlaidusi jaunu rakstu par Stable Diffusion 2. Tajā Stability AI piedāvā jaunu algoritmu, kas ir efektīvāks un izturīgāks nekā iepriekšējais, vienlaikus salīdzinot to ar citām modernākajām metodēm.

CompVis sākotnējais Stable Diffusion V1 modelis radīja revolūciju atvērtā pirmkoda AI modeļu būtībā un ražoja simtiem dažādu modeļu un sasniegumu visā pasaulē. Tas piedzīvoja vienu no ātrākajiem kāpumiem līdz 10 000 Github zvaigznēm, mazāk nekā divu mēnešu laikā sasniedzot 33 000 — ātrāk nekā citas programmas Github.
Sākotnējo Stable Diffusion V1 izlaidumu vadīja dinamiskā Robina Rombaha (Stability AI) un Patrick Esser (Runway ML) komanda no LMU Minhenes CompVis grupas, kuru vadīja prof. Dr. Bjerns Ommers. Viņi balstījās uz laboratorijas iepriekšējo darbu ar latentās difūzijas modeļiem un saņēma kritisku atbalstu no LAION un Eleuther AI.

 Ar ko Stable Diffusion v1 atšķiras no Stable Diffusion v2?
Ar ko Stable Diffusion v1 atšķiras no Stable Diffusion v2?
Stable Diffusion 2.0 ietver vairākus nozīmīgus uzlabojumus un līdzekļus salīdzinājumā ar iepriekšējo versiju, tāpēc apskatīsim tos.
Stable Diffusion 2.0 laidienā ir izturīgi teksta pārveides modeļi, kas apmācīti ar jaunu teksta kodētāju (OpenCLIP), ko izstrādājis LAION ar Stabilitātes AI palīdzību, kas ievērojami uzlabo ģenerēto attēlu kvalitāti salīdzinājumā ar iepriekšējām V1 laidieniem. Šī laidiena modeļi teksta pārveidošanai attēlā var izvadīt attēlus ar noklusējuma izšķirtspēju 512 × 512 pikseļi un 768 × 768 pikseļi.
Šie modeļi tiek apmācīti, izmantojot LAION-5B datu kopas estētisku apakškopu, ko ģenerējusi Stability AI DeepFloyd komanda, kas pēc tam tiek filtrēta, lai izslēgtu pieaugušajiem paredzētu saturu, izmantojot LAION NSFW filtru.
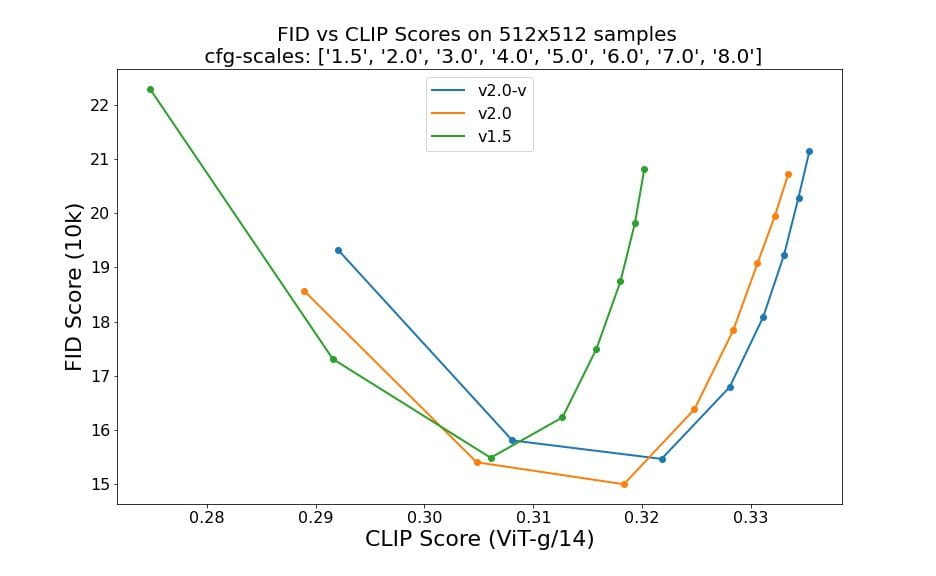
Novērtējumi, izmantojot 50 DDIM parauga soļus, 50 vadošās skalas bez klasifikatoriem un 1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0 un 8,0, norāda uz relatīviem kontrolpunktu uzlabojumiem:
Stable Diffusion 2.0 tagad ietver Upscaler Diffusion modeli, kas palielina attēla izšķirtspēju četras reizes. Piemērs mūsu modelim, kurā zemas kvalitātes ģenerēts attēls (128 × 128) tiek palielināts par augstākas izšķirtspējas attēlu (512 × 512). Stable Diffusion 2.0, ja to apvieno ar mūsu teksta pārveides modeļiem, tagad var ģenerēt attēlus ar izšķirtspēju 2048 × 2048 vai augstāku.

Jaunais ar dziļumu vadāms stabilas difūzijas modelis deep2img paplašina iepriekšējo V1 funkciju no attēla uz attēlu ar pilnīgi jaunām radošām iespējām. Depth2img nosaka ievades attēla dziļumu (izmantojot esošu modeli) un pēc tam ģenerē jaunus attēlus, pamatojoties gan uz tekstu, gan uz dziļuma informāciju. Depth-to-Image var nodrošināt jaunu radošu lietojumprogrammu pārpilnību, piedāvājot izmaiņas, kas šķiet būtiski atšķirīgas no oriģināla, vienlaikus saglabājot attēla saskaņotību un dziļumu.
Kas jauns Stable Diffusion 2?
Jaunais stabilās difūzijas modelis piedāvā 768×768 izšķirtspēju.
U-Net ir tāds pats parametru skaits kā versijai 1.5, taču tas ir apmācīts no nulles un kā teksta kodētājs izmanto OpenCLIP-ViT/H. Tā sauktais v-prognozes modelis ir SD 2.0-v.
Iepriekš minētais modelis tika pielāgots no SD 2.0 bāzes, kas arī ir pieejams un tika apmācīts kā tipisks trokšņu prognozēšanas modelis 512 × 512 attēliem.
Ir pievienots latentais teksta vadīts difūzijas modelis ar x4 mērogošanu.
Rafinēts SD 2.0 bāzes dziļuma vadīts stabilas difūzijas modelis. Modeli var izmantot struktūras saglabāšanai img2img un formas nosacītajai sintēzei, un tas ir atkarīgs no monokulārā dziļuma aprēķiniem, ko secina MiDaS.
Uzlabots ar tekstu vadāms gleznošanas modelis, kas izveidots uz SD 2.0 pamata.
Izstrādātāji smagi strādāja, tāpat kā sākotnējā Stable Diffusion iterācija, lai optimizētu modeli tā, lai tas darbotos ar vienu GPU — viņi jau no paša sākuma vēlējās padarīt to pieejamu pēc iespējas lielākam cilvēku skaitam. Viņi jau ir redzējuši, kas notiek, kad miljoniem cilvēku pieķeras pie šiem modeļiem un sadarbojas, lai izveidotu absolūti ievērojamas lietas. Tas ir atvērtā koda spēks: miljoniem talantīgu cilvēku plašā potenciāla izmantošana, kuriem, iespējams, nav resursu, lai apmācītu visprogresīvāko modeli, bet kuriem ir iespēja ar to paveikt neticamas lietas.

Šis jaunais atjauninājums apvienojumā ar jaudīgām jaunām funkcijām, piemēram, deep2img un labākām izšķirtspējas palielināšanas iespējām, kalpos par pamatu daudzām jaunām lietojumprogrammām un ļaus izvērst jaunu radošo potenciālu.
Lasiet vairāk par stabilu difūziju:
Stabilas difūzijas AI rada sapņu pasaules VR un Metaverse
Mākslinieks izmanto Stable Diffusion, lai izveidotu pirmo pilno AI animācijas filmu
Iepazīstieties ar video gleznošanu: teksta vadīta rediģēšana ar stabilas difūzijas un neironu atlantiem
Ziņa Stabilitātes AI stabilās difūzijas 2 algoritms beidzot ir publisks: jauns deep2img modelis, īpaši augstas izšķirtspējas mērogošana, pieaugušajiem paredzēts saturs, kas pirmo reizi parādījās vietnē Metaverse Post.