

Galvenās līdzņemamās vietas
Binance izmanto jaudas pārvaldību neplānotiem trafika palielinājumiem, ko izraisa liela nepastāvība, nodrošinot atbilstošu, savlaicīgu infrastruktūru un skaitļošanas resursus biznesa prasībām.
Binance slodzes testi ražošanas vidē (nevis iestudēšanas vidē), lai iegūtu precīzus pakalpojumu etalonus. Šī metode palīdz pārbaudīt, vai mūsu resursu piešķiršana ir piemērota noteiktas slodzes apkalpošanai.
Binance infrastruktūra nodarbojas ar lielu trafika apjomu, un, lai uzturētu pakalpojumu, no kura lietotāji var paļauties, ir nepieciešama pareiza jaudas pārvaldība un automātiska slodzes pārbaude.

Kāpēc Binance ir nepieciešams specializēts jaudas pārvaldības process?
Jaudas pārvaldība ir sistēmas stabilitātes pamats. Tas ietver pareiza izmēra lietojumprogrammu un infrastruktūras resursus atbilstoši pašreizējām un nākotnes biznesa prasībām par pareizu cenu. Lai palīdzētu sasniegt šo mērķi, mēs veidojam jaudas pārvaldības rīkus un cauruļvadus, lai izvairītos no pārslodzes un palīdzētu uzņēmumiem nodrošināt vienmērīgu lietošanas pieredzi.
Kriptovalūtu tirgi bieži vien saskaras ar regulārākiem nestabilitātes periodiem nekā tradicionālie finanšu tirgi. Tas nozīmē, ka Binance sistēmai laiku pa laikam ir jāiztur šis trafika pieaugums, jo lietotāji reaģē uz tirgus izmaiņām. Izmantojot pareizu jaudas pārvaldību, mēs saglabājam jaudu, kas ir piemērota vispārējam biznesa pieprasījumam un šiem trafika pieauguma scenārijiem. Tieši šis galvenais punkts padara Binance jaudas pārvaldības procesus unikālus un izaicinošus.
Apskatīsim faktorus, kas bieži kavē procesu un noved pie lēna vai nepieejama pakalpojuma. Pirmkārt, mums ir pārslodze, ko parasti izraisa pēkšņs satiksmes pieaugums. Piemēram, tas var rasties mārketinga notikuma, pašpiegādes paziņojuma vai pat DDoS (izplatītā pakalpojuma atteikuma) uzbrukuma rezultātā.
Pārsprieguma trafika un nepietiekama jauda ietekmē sistēmas funkcionalitāti šādi:
Pakalpojums uzņemas arvien vairāk darba.
Atbildes laiks palielinās tiktāl, ka klienta taimauta laikā uz pieprasījumu nevar atbildēt. Šī degradācija parasti notiek resursu piesātinājuma (CPU, atmiņas, IO, tīkla utt.) vai ilgstošu GC paužu dēļ pašā pakalpojumā vai tā atkarībā.
Rezultāts ir tāds, ka pakalpojums nevarēs nekavējoties apstrādāt pieprasījumus.
Procesa sadalīšana
Tagad, kad esam apsprieduši vispārējo kapacitātes pārvaldības principu, apskatīsim, kā Binance to piemēro savā biznesā. Šeit ir sniegts ieskats mūsu jaudas pārvaldības sistēmas arhitektūrā ar dažām galvenajām darbplūsmām.
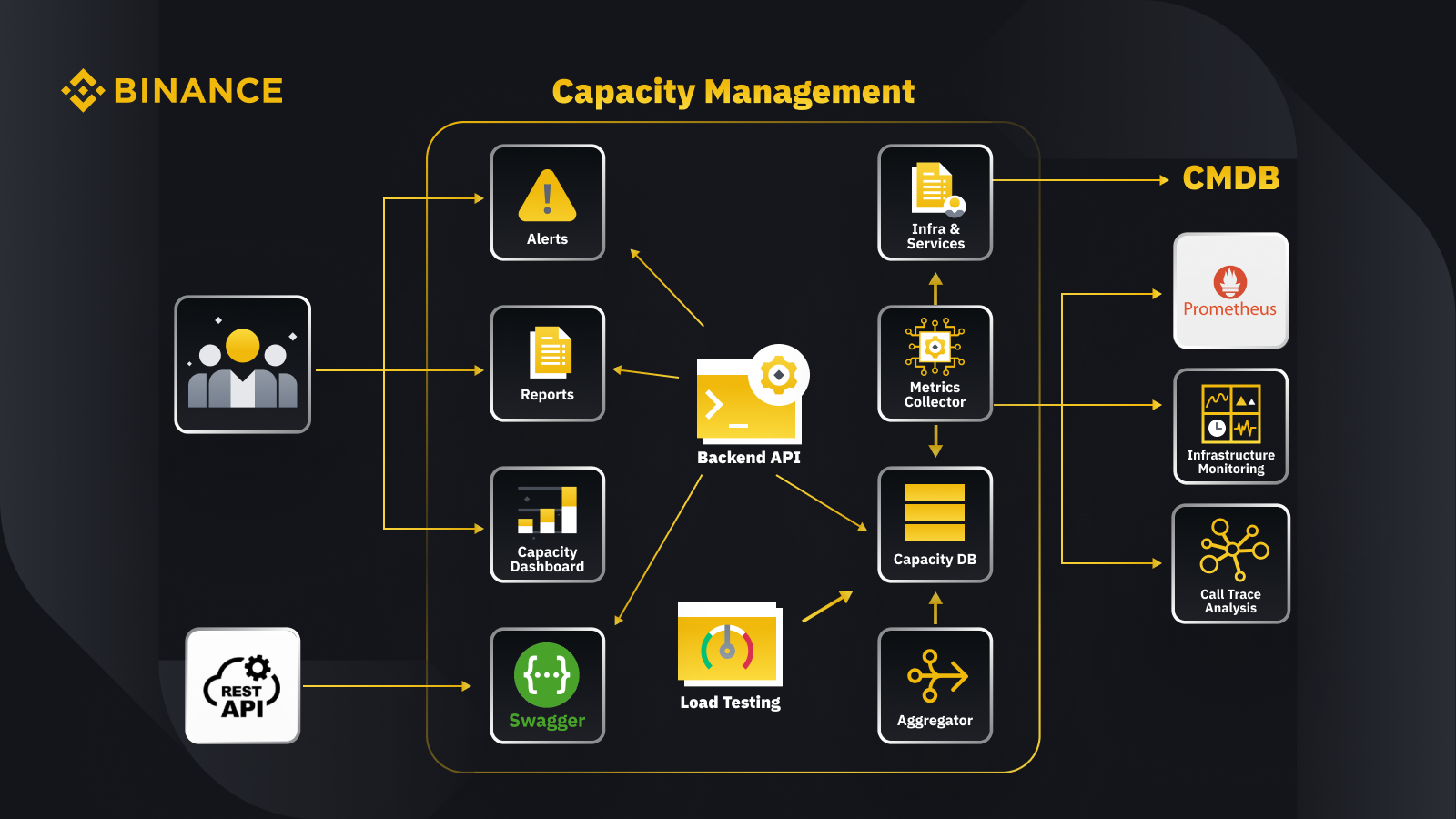
Iegūstot datus no konfigurācijas pārvaldības datu bāzes (CMDB), mēs ģenerējam infrastruktūru un pakalpojumu konfigurācijas. Šajās konfigurācijās esošie vienumi ir jaudas pārvaldības objekti.
Metrikas savācējs ienes jaudas metriku no Prometheus biznesa un pakalpojumu slāņa datiem, infrastruktūras uzraudzību resursu slāņa metrikai un zvanu izsekošanas analīzes sistēmu izsekošanas informācijai. Metrikas savācējs saglabā datus jaudas datu bāzē (CDB).
Slodzes testēšanas sistēma veic pakalpojumu stresa testus un saglabā etalona datus CDB.
Apkopotājs iegūst jaudas datus no CDB un apkopo tos ikdienas un visu laiku augstākajām (ATH) dimensijām. Pēc apkopošanas tas ieraksta apkopotos datus atpakaļ CDB.
Apstrādājot datus no CDB, aizmugursistēmas API nodrošina saskarnes jaudas informācijas panelim, brīdinājumiem un pārskatiem, kā arī pārējo API un saistītos jaudas datus integrācijai.
Ieinteresētās personas gūst ieskatu par jaudu, izmantojot jaudas informācijas paneli, brīdinājumus un pārskatus. Viņi var izmantot arī citas saistītas sistēmas, tostarp pakalpojumu jaudas datu uzraudzību, izmantojot pārējās API, ko nodrošina jaudas pārvaldības sistēma ar Swagger.
stratēģija
Mūsu jaudas pārvaldības un plānošanas stratēģija balstās uz apstrādi, kas virzīta uz maksimumu. Maksimālā apstrāde ir pakalpojuma resursi (tīmekļa serveri, datu bāzes u.c.) darba slodze maksimālās izmantošanas laikā.
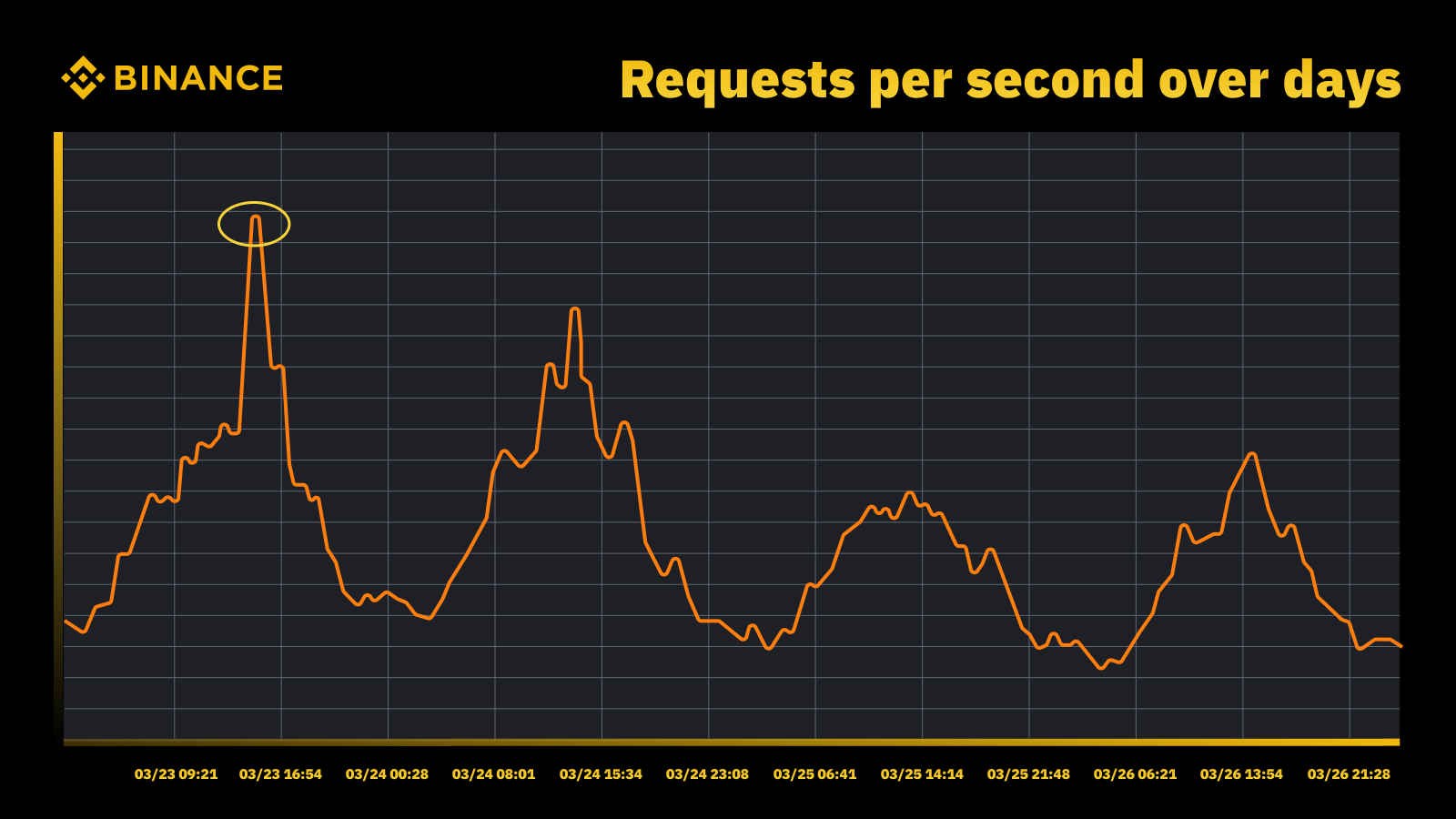
Satiksmes pieaugums, kad Fed 2023. gada martā paaugstināja likmi
Mēs analizējam periodiskos maksimumus un izmantojam tos, lai vadītu jaudas trajektoriju. Tāpat kā ar jebkuru pīķa virzītu resursu, mēs vēlamies noskaidrot, kad notiek maksimumi, un pēc tam izpētīt, kas patiesībā notiek šo ciklu laikā.
Vēl viena svarīga lieta, ko mēs apsveram kopā ar pārslodzes novēršanu, ir automātiskā mērogošana. Automātiskā mērogošana novērš pārslodzi, dinamiski palielinot jaudu, izmantojot vairāk pakalpojuma gadījumu. Pēc tam tiek sadalīta pārmērīga trafika, un viena pakalpojuma (vai atkarības) datplūsma tiek pārvaldīta.
Automātiskajai mērogošanai ir sava vieta, taču tā nespēj tikt galā tikai ar pārslodzes situācijām. Parasti tas nevar pietiekami ātri reaģēt uz pēkšņu satiksmes pieaugumu un vislabāk darbojas tikai tad, ja tas pakāpeniski palielinās.
Mērīšana
Mērīšanai ir izšķiroša nozīme Binance jaudas pārvaldības darbā, un datu vākšana ir mūsu pirmais mērīšanas solis. Pamatojoties uz Informācijas tehnoloģiju infrastruktūras bibliotēkas (ITIL) standartiem, mēs apkopojam datus mērīšanai jaudas pārvaldības apakšprocesos, proti:
Resurss - IT infrastruktūras resursu patēriņš, ko nosaka lietojumprogrammu/pakalpojumu lietojums. Koncentrējas uz fizisko un virtuālo skaitļošanas resursu iekšējās veiktspējas metriku, tostarp servera centrālo procesoru, atmiņu, diska krātuvi, tīkla joslas platumu utt.
Apkalpošana. Lietojumprogrammas līmeņa veiktspējas, SLA, latentuma un caurlaidspējas pasākumi, kas izriet no uzņēmējdarbības aktivitātēm. Koncentrējas uz ārējās veiktspējas metriku, pamatojoties uz to, kā lietotāji uztver pakalpojumu, tostarp pakalpojuma latentumu, caurlaidspēju, maksimumus utt.
Bizness. Apkopo datus, kas mēra mērķa lietojumprogrammā apstrādātās uzņēmējdarbības aktivitātes, tostarp pasūtījumus, lietotāju reģistrāciju, maksājumus utt.
Jaudas pārvaldība, kuras pamatā ir tikai infrastruktūras resursu izmantošana, novedīs pie neprecīzas plānošanas. Tas ir tāpēc, ka tas var neatspoguļot faktiskos uzņēmējdarbības apjomus un caurlaidspēju, kas veicina mūsu infrastruktūras jaudu.
Plānotie pasākumi ir lieliska vieta, lai to tālāk apspriestu. Piedalieties Watch Web Summit 2022 vietnē Binance Live, lai kopīgotu līdz 15 000 BUSD Crypto Box Rewards kampaņā. Papildus pamatā esošajiem resursu un pakalpojumu slāņa rādītājiem mums bija jāņem vērā arī uzņēmējdarbības apjomi. Jaudas plānošana šeit tika balstīta uz uzņēmējdarbības metriku, piemēram, aptuveno tiešraides straumes skatītāju skaitu, maksimālo kriptogrāfijas kastes pieprasījumu skaitu lidojuma laikā, latentumu no gala līdz galam un citiem faktoriem.
Pēc datu apkopošanas mūsu jaudas pārvaldības procesi apkopo un apkopo daudzos datu punktus, kas savākti attiecībā uz konkrētu jaudas draiveri. Metrikas apkopotā vērtība ir viena vērtība, ko var izmantot jaudas brīdināšanai, ziņošanai un citās ar jaudu saistītās funkcijās.
Mēs varam piemērot vairākas datu apkopošanas metodes periodiskiem datu punktiem, piemēram, summa, vidējais, mediānas, minimums, maksimums, procentile un visu laiku augstākais rādītājs (ATH).

Mūsu izvēlētā metode nosaka mūsu rezultātus no kapacitātes pārvaldības procesa un no tā izrietošajiem lēmumiem. Mēs izvēlamies dažādas metodes, pamatojoties uz dažādiem scenārijiem. Piemēram, mēs izmantojam maksimālo metodi kritiskajiem pakalpojumiem un saistītajiem datu punktiem. Lai reģistrētu vislielāko trafiku, mēs izmantojam ATH metodi.
Dažādos lietošanas gadījumos datu apkopošanai izmantojam dažādus precizitātes veidus. Vairumā gadījumu mēs izmantojam minūti, stundu, dienu vai ATH.
Ar minimālu precizitāti mēs izmērām pakalpojuma darba slodzi, lai savlaicīgi brīdinātu par pārslodzi.
Mēs izmantojam stundu apkopotus datus, lai izveidotu dienas datus un apkopotu stundas datus, lai reģistrētu dienas maksimumu.
Parasti mēs izmantojam ikdienas datus jaudas pārskatiem un izmantojam ATH datus jaudas modelēšanai un plānošanai.
Viens no jaudas pārvaldības galvenajiem rādītājiem ir pakalpojumu salīdzinošā novērtēšana. Tas palīdz mums precīzi novērtēt pakalpojuma veiktspēju un jaudu. Mēs iegūstam pakalpojuma etalonu ar slodzes testēšanu, un vēlāk mēs to aplūkosim sīkāk.
Jaudas pārvaldība, pamatojoties uz prioritāti
Līdz šim esam redzējuši, kā mēs apkopojam jaudas metriku un apkopojam datus dažādos precizitātes veidos. Vēl viena svarīga joma, kas jāapspriež, ir prioritāte, kas ir noderīga brīdinājumu un jaudas ziņojumu kontekstā. Pēc IT līdzekļu ranžēšanas ierobežots infrastruktūras lietojums un skaitļošanas resursi tiek piešķirti par prioritāti un vispirms tiek piešķirti kritiskajiem pakalpojumiem un darbībām.
Var būt vairāki veidi, kā definēt pakalpojumu un pieprasīt kritiskumu. Noderīga atsauce ir Google. SRE grāmatā. Tie definē kritiskuma līmeņus kā CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS utt. Tāpat mēs definējam vairākus prioritātes līmeņus, piemēram, P0, P1, P2 un tā tālāk.
Mēs definējam prioritātes līmeņus šādi:
P0: vissvarīgākajiem pakalpojumiem un pieprasījumiem, kas radīs nopietnu, lietotājam redzamu ietekmi, ja tie neizdodas.
P1: tiem pakalpojumiem un pieprasījumiem, kas radīs lietotājam redzamu ietekmi, taču ietekme ir mazāka nekā P0. Paredzams, ka P0 un P1 pakalpojumi tiks nodrošināti ar pietiekamu jaudu.
P2: šī ir noklusējuma prioritāte pakešdarbiem un bezsaistes darbiem. Šie pakalpojumi un pieprasījumi nedrīkst radīt lietotājam redzamu ietekmi, ja tie ir daļēji nepieejami.
Kas ir slodzes pārbaude un kāpēc mēs to izmantojam ražošanas vidē?
Slodzes pārbaude ir nefunkcionāls programmatūras testēšanas process, kurā lietojumprogrammas veiktspēja tiek pārbaudīta noteiktā darba slodzē. Tas palīdz noteikt, kā lietojumprogramma darbojas, kamēr tai vienlaikus piekļūst vairāki galalietotāji.
Uzņēmumā Binance mēs izveidojām risinājumu, kas ļautu mums veikt slodzes testēšanu ražošanā. Parasti slodzes testēšana tiek veikta izlaiduma vidē, taču mēs nevarējām izmantot šo opciju, pamatojoties uz mūsu vispārējiem jaudas pārvaldības mērķiem. Slodzes pārbaude ražošanas vidē ļāva mums:
Apkopojiet precīzu mūsu pakalpojumu etalonu reālās dzīves slodzes apstākļos.
Palieliniet pārliecību par sistēmu un tās uzticamību un veiktspēju.
Identificējiet sistēmas vājās vietas, pirms tās rodas ražošanas vidē.
Iespējot nepārtrauktu ražošanas vides uzraudzību.
Iespējojiet proaktīvu jaudas pārvaldību ar normalizētiem testēšanas cikliem, kas notiek regulāri.
Tālāk varat skatīt mūsu slodzes testēšanas sistēmu ar dažiem galvenajiem ieteikumiem:

Binance mikropakalpojumu ietvaram ir pamata slānis, lai atbalstītu uz konfigurāciju balstītu un uz karodziņiem balstītu trafika maršrutēšanu, kas ir būtiska mūsu TIP pieejai.
Lai novērtētu testējamo gadījumu, tiek izmantota automatizētā kanārijas analīze (ACA). Tajā tiek salīdzināti galvenie pārraudzības sistēmā savāktie rādītāji, lai mēs varētu apturēt/pārtraukt pārbaudi, ja rodas kāda neparedzēta problēma, lai samazinātu lietotāju ietekmi.
Slodzes testēšanas laikā tiek apkopoti etaloni un metrika, lai iegūtu datu ieskatus par uzvedību un lietojumprogrammu veiktspēju.
API ir pakļautas vērtīgu veiktspējas datu kopīgošanai dažādos scenārijos, piemēram, jaudas pārvaldības un kvalitātes nodrošināšanas jomā. Tas palīdz veidot atvērtu ekosistēmu.
Mēs veidojam automatizācijas darbplūsmas, lai organizētu visas darbības un kontroles punktus no pilnīgas testēšanas perspektīvas. Mēs arī nodrošinām elastīgu integrāciju ar citām sistēmām, piemēram, CI/CD konveijeru un operāciju portālu.
Mūsu testēšanas ražošanā (TIP) pieeja
Tradicionālā veiktspējas testēšanas pieeja (testu veikšana inscenēšanas vidē ar simulētu vai atspoguļotu trafiku) sniedz dažas priekšrocības. Tomēr produkcijai līdzīgas iestudēšanas vides izvietošanai mūsu kontekstā ir vairāk trūkumu:
Tas gandrīz divkāršo infrastruktūras izmaksas un uzturēšanas centienus.
Ir neticami sarežģīti nodrošināt pilnīgu darbu ražošanā, jo īpaši liela mēroga mikropakalpojumu vidē vairākās biznesa vienībās.
Tas palielina datu privātuma un drošības riskus, jo mums neizbēgami, iespējams, vajadzēs dublēt datus inscenēšanas laikā.
Imitētā datplūsma nekad neatkārtos to, kas faktiski notiek ražošanā. Iestudēšanas vidē iegūtais etalons būtu neprecīzs un tam ir mazāka vērtība
Testēšana ražošanā, kas pazīstama arī kā TIP, ir pārslēgšanas pa labi testēšanas metodika, kurā jauns kods, līdzekļi un laidieni tiek testēti ražošanas vidē. Mūsu pieņemtā slodzes pārbaude ražošanā ir ļoti izdevīga, jo tā mums palīdz:
Analizējiet sistēmas stabilitāti un robustumu.
Atklājiet lietojumprogrammu etalonus un vājās vietas dažādos trafika līmeņos, servera specifikācijās un lietojumprogrammu parametros.
Uz FlowFlag balstīta maršrutēšana
Mūsu uz FlowFlag balstīta maršrutēšana, kas iegulta mikropakalpojumu bāzes sistēmā, ir pamats, lai TIP būtu iespējams. Tas attiecas uz konkrētiem gadījumiem, tostarp lietojumprogrammām, kas trafika sadalei izmanto Eureka pakalpojumu atklāšanu.
Kā parādīts diagrammā, Binance tīmekļa serveris kā ieejas punkti apzīmē dažus procentus no trafika, kā norādīts konfigurācijās ar FlowFlag galvenēm, slodzes testa laikā mēs varam atlasīt vienu konkrēta pakalpojuma resursdatoru un atzīmēt to kā mērķa perf instanci. konfigurācijas, tad šie marķētie perf pieprasījumi galu galā tiks novirzīti uz perf instanci, kad tie sasniegs pakalpojumu apstrādei.
Tas ir pilnībā konfigurēts, un tas tiek ielādēts ar karstu, mēs varam viegli pielāgot darba slodzes procentus, izmantojot automatizāciju, neizvietojot jaunu laidienu.
To var plaši pielietot lielākajai daļai mūsu pakalpojumu, jo mehānisms ir vārtejas un bāzes pakotnes sastāvdaļa
Viens izmaiņu punkts nozīmē arī vienkāršu atcelšanu, lai samazinātu riskus ražošanā

Pārveidojot mūsu risinājumu, lai tas būtu vairāk mākonis, mēs arī pētām, kā mēs varam izveidot līdzīgu pieeju, lai atbalstītu citu trafika maršrutēšanu, ko piedāvā publiskā mākoņa pakalpojumu sniedzēji vai Kubernetes.
Automatizēta kanārijas analīze, lai samazinātu risku, kas saistīts ar ietekmi uz lietotāju
Canary izvietošana ir izvietošanas stratēģija, lai samazinātu jaunas programmatūras versijas izvietošanas risku ražošanā. Tas parasti ietver jaunas programmatūras versijas, ko sauc par kanārijputnu, izvietošanu nelielai lietotāju apakškopai līdzās stabilai darbības versijai. Pēc tam mēs sadalām trafiku starp abām versijām, lai daļa ienākošo pieprasījumu tiktu novirzīta uz kanārijputniņu.
Pēc tam kanārijputniņu versijas kvalitāte tiek novērtēta ar tā saukto kanārijputnu analīzi. Tas salīdzina galvenos rādītājus, kas raksturo vecās un jaunās versijas darbību. Ja notiek ievērojama metrikas pasliktināšanās, kanārijputniņš tiek pārtraukts un visa datplūsma tiek novirzīta uz stabilo versiju, lai samazinātu neparedzētas darbības ietekmi.
Mēs izmantojam to pašu koncepciju, lai izveidotu mūsu automātiskās slodzes pārbaudes risinājumu. Risinājums izmanto Kayenta platformu automatizētai kanārijputnu analīzei (ACA), izmantojot Spinnaker, lai nodrošinātu automatizētu kanāriju izvietošanu. Mūsu tipiskā slodzes testa plūsma, ievērojot šo metodi, izskatās šādi:
Izmantojot darbplūsmu, mēs pakāpeniski pievienojam datplūsmas slodzi (piemēram, 5%, 10%, 25%, 50%) mērķa saimniekdatoram, kā norādīts vai līdz tas sasniedz pārtraukuma punktu.
Katrai slodzei ar Kayenta noteiktu laiku (piemēram, 5 minūtes) atkārtoti tiek veikta kanārijas analīze, lai salīdzinātu pārbaudītā saimniekdatora galvenos rādītājus ar pirmsslodzes periodu kā bāzes līniju un pašreizējo pēcslodzes periodu kā eksperimentu.
Salīdzinājums (kanāriju konfigurācijas modelis) ir vērsts uz pārbaudi, vai mērķa resursdators:
Sasniedz resursu ierobežojumus, piemēram, CPU lietojums pārsniedz 90%.
Ir ievērojami palielinājies kļūdu metrikas, piemēram, kļūdu žurnālu, HTTP izņēmumu vai ātruma ierobežojuma noraidīšanas gadījumu skaits.
Lietojumprogrammu pamatmetrika joprojām ir saprātīga, piemēram, HTTP latentums ir mazāks par 2 sekundēm (pielāgojams katram pakalpojumam)
Par katru analīzi Kayenta sniedz mums ziņojumu, kurā norādīts rezultāts, un tests tiek nekavējoties pārtraukts pēc neveiksmes.
Šī kļūmes noteikšana parasti aizņem mazāk nekā 30 sekundes, ievērojami samazinot iespēju ietekmēt mūsu galalietotāju pieredzi.

Datu ieskatu iespējošana
Ir ļoti svarīgi savākt pietiekamu informāciju par visiem iepriekš aprakstītajiem procesiem un testu izpildēm. Galīgais mērķis ir uzlabot mūsu sistēmas uzticamību un robustumu, kas nav iespējams bez datu ieskatiem.
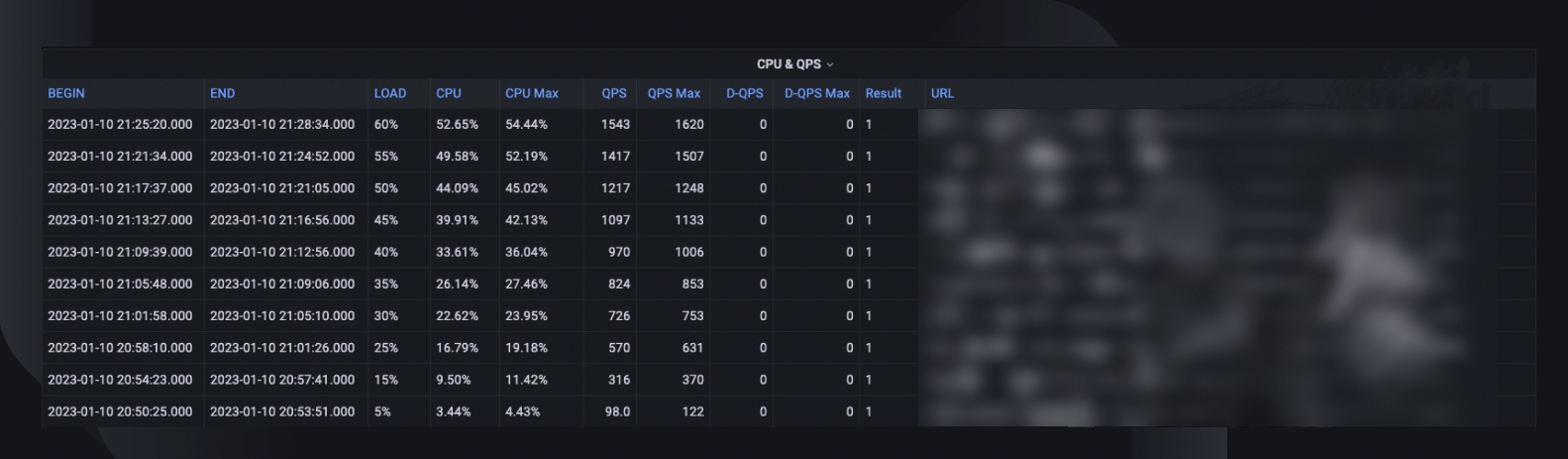
Vispārējā testa kopsavilkumā ir ietverta maksimālā slodzes procentuālā daļa, ar kādu saimniekdators spēja rīkoties, maksimālais CPU lietojums un resursdatora QPS. Pamatojoties uz to, tiek aprēķināts arī gadījumu skaits, kas mums var būt nepieciešams, lai izpildītu jaudas rezervāciju, ņemot vērā pakalpojumu visu laiku augstāko QPS.
Cita vērtīga informācija analīzei ietver programmatūras versiju, servera specifikāciju, izvietoto skaitu un saiti uz monitora informācijas paneli, kur varam atskatīties uz testa laikā notikušo.

Etalona līkne norāda, kā veiktspēja ir mainījusies pēdējo trīs mēnešu laikā, lai mēs varētu atklāt visas iespējamās problēmas, kas saistītas ar konkrētu lietojumprogrammas laidienu.

CPU un QPS tendences parāda, kā CPU lietojums korelē ar pieprasījumu apjomu, kas serverim bija jāapstrādā. Šis rādītājs var palīdzēt novērtēt servera iespējas ienākošās trafika pieaugumam.
API latentuma darbība parāda, kā reakcijas laiks mainās dažādos slodzes apstākļos piecām galvenajām API. Pēc tam mēs varam optimizēt sistēmu, ja nepieciešams, individuālā API līmenī.

API slodzes sadalījuma metrika palīdz mums saprast, kā API sastāvs ietekmē pakalpojuma veiktspēju, un sniedz plašāku ieskatu uzlabojumu jomās.
Normalizācija un produkcijas ražošana
Mūsu sistēmai turpinot augt un attīstīties, mēs turpināsim sekot līdzi un uzlabot pakalpojumu stabilitāti un uzticamību. Mēs to turpināsim, izmantojot:
Regulārs un izveidots slodzes testēšanas grafiks kritiskajiem pakalpojumiem.
Automātiska slodzes pārbaude kā daļa no mūsu CI/CD cauruļvadiem.
Palielināta visa risinājuma produkcijas ražošana, lai sagatavotos liela mēroga ieviešanai visā organizācijā.
Ierobežojumi
Pašreizējai slodzes testa pieejai ir daži ierobežojumi:
Uz FlowFlag balstīta maršrutēšana ir piemērojama tikai mūsu mikropakalpojumu sistēmai. Mēs cenšamies paplašināt risinājumu vairākiem maršrutēšanas scenārijiem, izmantojot mākoņa slodzes balansētāju vai Kubernetes Ingress kopējo svērto maršrutēšanas funkciju.
Tā kā testēšanas pamatā ir reāla lietotāju datplūsma ražošanā, mēs nevaram veikt funkciju testus pret noteiktiem API vai lietošanas gadījumiem. Turklāt ļoti maza apjoma pakalpojumiem vērtība būtu ierobežota, jo mēs, iespējams, nevarēsim noteikt tā vājo vietu.
Mēs veicam šīs pārbaudes, salīdzinot ar atsevišķiem pakalpojumiem, nevis aptveram zvanu ķēdes no gala līdz galam.
Testēšana ražošanā dažkārt var ietekmēt reālus lietotājus, ja rodas kļūmes. Tāpēc mums ir jābūt kļūdu analīzei un automātiskai atcelšanai ar pilnām automatizācijas iespējām.
Noslēguma domas
Mums ir ļoti svarīgi domāt par satiksmes pieauguma scenārijiem, lai novērstu sistēmas pārslodzi un nodrošinātu to darbspēju. Tāpēc esam izveidojuši šajā rakstā aprakstītos jaudas pārvaldības un slodzes testēšanas procesus. Apkopot:
Mūsu jaudas pārvaldība ir balstīta uz maksimumu un ir iegulta katrā pakalpojuma dzīves cikla posmā, novēršot pārslodzi ar tādām darbībām kā mērīšana, prioritāšu iestatīšana, brīdinājumi un jaudas ziņojumi utt. Galu galā tas padara Binance procesus un vajadzības unikālus salīdzinājumā ar tipisku jaudas pārvaldības situāciju. .
Pakalpojumu etalons, kas iegūts no slodzes testēšanas, ir jaudas pārvaldības un plānošanas centrālais punkts. Tas precīzi nosaka infrastruktūras resursus, kas nepieciešami, lai atbalstītu pašreizējās un nākotnes biznesa prasības. Galu galā tas bija jāveic ražošanā, izmantojot unikālu, Binance izstrādātu risinājumu, kas ļāva mums apmierināt mūsu īpašās vajadzības.
Ņemot to visu kopā, mēs ceram, ka jūs redzēsiet, ka laba plānošana un rūpīgi izstrādāti ietvari palīdz izveidot pakalpojumu, ko binansieši zina un bauda.
Atsauces
Dominiks Ogbonna, kapacitātes pārvaldības A–Z: praktiska rokasgrāmata uzņēmuma IT uzraudzības un kapacitātes plānošanas ieviešanai, 4. nodaļa, 6. nodaļa
Luis Quesada Torres, Doug Colish, SRE jaudas pārvaldības labākās prakses
Alehandro Forero Kuervo, Sāra Čavisa, Google SRE grāmata, 21. nodaļa — pārslodzes apstrāde
Tālāka lasīšana
(emuārs) Kā Binance Ledger uzlabo jūsu binances pieredzi
(Emuārs) Iepazīstinām ar Binance Oracle VRF — nākamās paaudzes pārbaudāmu nejaušību
(Blogs) Binance pievienojas FIDO aliansei, lai sagatavotos piekļuves atslēgas ieviešanai