
主なポイント
Binance では、機械学習 (ML) を使用して、アカウント乗っ取り (ATO) 詐欺、P2P 詐欺、支払い詳細の盗難などを含むさまざまなビジネス上の問題を解決しています。
Binance Risk AI データ サイエンティストは、機械学習オペレーション (MLOps) を使用して、本番環境に対応した ML サービスを継続的に提供するリアルタイムのエンドツーエンド ML パイプラインを構築しました。

なぜ MLOps を使用するのでしょうか?
まず、ML サービスの作成は反復的なプロセスです。データ サイエンティストは、ビジネスに価値を提供するという目的に基づいて、オフラインまたはオンラインで特定の指標を改善するために常に実験を行っています。では、このプロセスをより効率的にするにはどうすればよいでしょうか (たとえば、ML モデルの市場投入までの時間を短縮するなど)。
第二に、ML サービスの動作は、開発者が定義するコードだけでなく、収集されるデータによっても影響を受けます。コンセプト ドリフトとも呼ばれるこの考え方は、Google の「機械学習システムにおける隠れた技術的負債」という論文で強調されています。
詐欺を例に挙げてみましょう。詐欺師は単なる機械ではなく、攻撃方法を常に変化させて適応する人間です。そのため、基盤となるデータ分布は、攻撃ベクトルの変化を反映して進化します。実稼働モデルが最新のデータ パターンを考慮していることを効果的に確認するにはどうすればよいでしょうか。
上記の課題を克服するために、私たちは MLOps という概念を使用します。これは、2018 年に Google が最初に提案した用語です。MLOps では、モデルのパフォーマンスと本番システムをサポートするインフラストラクチャに重点を置いています。これにより、スケーラブルで可用性が高く、信頼性が高く、保守可能な ML サービスを構築できます。
リアルタイムのエンドツーエンド ML パイプラインの詳細
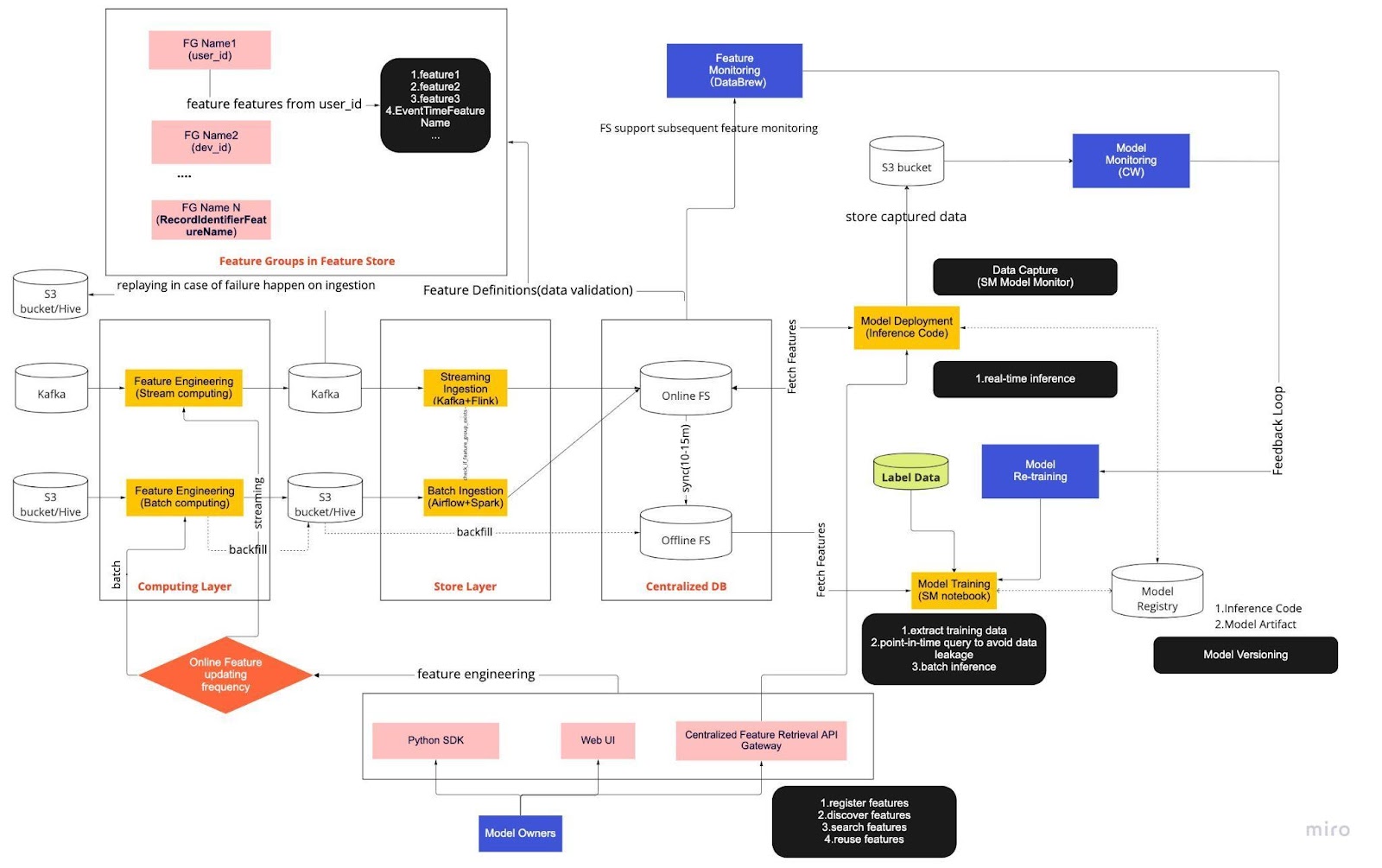
上の図は、機能ストアを使用したリアルタイム モデル開発の標準操作手順 (SOP) と考えてください。エンドツーエンドの ML パイプラインは、チームが MLops を適用する方法を示し、機能的要件と非機能的要件の 2 種類の要件に基づいて構築されています。
機能的
情報処理
モデルトレーニング
モデル開発
モデルの展開
監視
非機能要件
スケーラブル
高可用性
信頼性のある
メンテナンス可能
パイプラインはさらに 6 つの主要コンポーネントに分かれています。
コンピューティング層
ストアレイヤー
集中型DB
モデルトレーニング
モデルの展開
モデル監視
1. コンピューティング層

コンピューティング層は主に、生データを有用な特徴に変換するプロセスである特徴エンジニアリングを担当します。
コンピューティング層は、更新頻度に基づいて、1 分/秒間隔のストリーム コンピューティングと、日/時間間隔のバッチ コンピューティングの 2 つのタイプに分類されます。
コンピューティング レイヤーの入力データは通常、Apache Kafka や Kinesis などのイベントベースのデータベース、またはオープンソースの Apache Hive やクラウド ソリューションの Snowflake などの OLAP データベースから取得されます。
2. ストアレイヤー
ストア レイヤーは、機能定義を登録して機能ストアにデプロイするとともに、バックフィルを実行する場所です。バックフィルとは、新しい機能が定義されるたびに履歴データを使用して機能を再構築できるプロセスです。バックフィルは通常、データ サイエンティストがノートブック環境で実行できる 1 回限りのジョブです。Kafka は過去 7 日間のイベントしか保存できないため、s3/hive テーブルへのバックアップ メカニズムを使用してフォールト トレランスを高めます。
中間層である Hive と Kafka が、コンピューティング層とストア層の間に意図的に配置されていることに気づくでしょう。この配置は、コンピューティング機能と書き込み機能の間のバッファーと考えてください。類似点は、プロデューサーとコンシューマーを分離することです。ストリーム コンピューティングはプロデューサーであり、ストリームの取り込みはコンシューマーです。
コンピューティングと取り込みを分離することで、ML パイプラインにさまざまなメリットがもたらされます。まず、障害発生時のパイプラインの堅牢性を高めることができます。運用、ハードウェア、またはネットワークの問題により取り込みレイヤーまたはコンピューティング レイヤーが利用できない場合でも、データ サイエンティストは集中データベースから特徴値を引き出すことができます。
さらに、インフラストラクチャのさまざまな部分を個別に拡張して、パイプラインの構築と運用に必要なエネルギーを削減できます。たとえば、何らかの理由で障害が発生した場合でも、取り込みレイヤーがコンピューティング レイヤーをブロックすることはありません。イノベーションの面では、既存のインフラストラクチャに影響を与えることなく、Flink アプリケーションの新バージョンなどの新しいテクノロジーを試して採用できます。

コンピューティング レイヤーとストア レイヤーはどちらも、自動化された機能パイプラインと呼ばれています。これらのパイプラインは独立しており、さまざまなスケジュールで実行され、ストリーミング パイプラインまたはバッチ パイプラインとして分類されます。2 つのパイプラインの動作の違いは次のとおりです。バッチ パイプラインの 1 つの機能グループは夜間に更新されるのに対し、別のグループは 1 時間ごとに更新されます。ストリーミング パイプラインでは、Apache Kafka トピックなどの入力ストリームにソース データが到着すると、機能グループがリアルタイムで更新されます。
3. 集中型DB
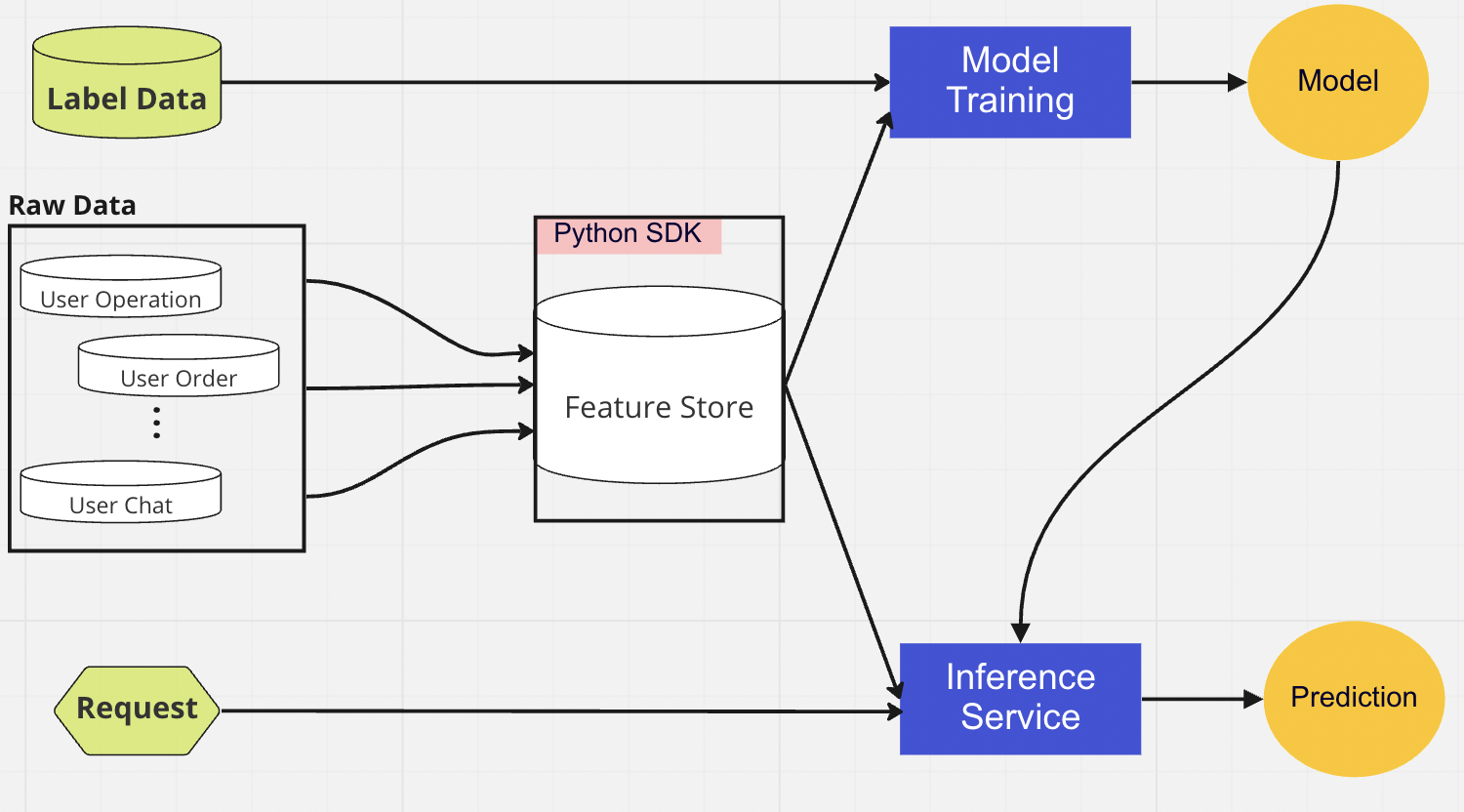
集中型 DB レイヤーは、データ サイエンティストが機能対応データをオンラインまたはオフラインの機能ストアに提示する場所です。
オンライン フィーチャ ストアは、低レイテンシで可用性の高いストアであり、レコードのリアルタイム検索が可能です。一方、オフライン フィーチャ ストアは、すべてのフィーチャ データの安全でスケーラブルなリポジトリを提供します。これにより、科学者は、オブジェクト ストレージ システム内のフィーチャ値の完全な履歴レコードを使用して、一元管理されたフィーチャ グループのセットから、トレーニング、検証、またはバッチ スコアリングのデータセットを作成できます。
両方の機能ストアは、トレーニングとサービスの偏りを回避するために、10〜15 分ごとに自動的に相互に同期します。今後の記事では、パイプラインで機能ストアを使用する方法について詳しく説明します。
4. モデルのトレーニング
モデル トレーニング レイヤーは、当社の科学者がオフライン機能ストアからトレーニング データを抽出し、ML サービスを微調整する場所です。抽出プロセス中にデータが漏洩するのを防ぐため、ポイントインタイム クエリを使用します。
さらに、このレイヤーには、モデル再トレーニング フィードバック ループと呼ばれる重要なコンポーネントが含まれています。モデル再トレーニングは、展開されたモデルが最新のデータ パターン (たとえば、ハッカーの攻撃行動の変更) を正確に表すことを保証することで、概念ドリフトのリスクを最小限に抑えます。
5. モデルの展開
モデルの展開では、リアルタイム データ サービングのバックボーンとして、主にクラウドベースのスコアリング サービスを使用します。現在の推論コードが機能ストアとどのように統合されるかを示す図を以下に示します。

6. モデルの監視
このレイヤーでは、当社のチームが QPS、レイテンシ、メモリ、CPU/GPU 使用率などのスコアリング サービスの使用状況メトリックを監視します。これらの基本的なメトリックに加えて、キャプチャされたデータを使用して、時間の経過に伴う特徴の分布、トレーニングとサービングの偏り、予測のドリフトをチェックし、コンセプトのドリフトを最小限に抑えます。
終わりに
まとめると、パイプライン インフラストラクチャをコンピューティング レイヤー、ストア レイヤー、集中型 DB に緩く分割すると、より密結合されたアーキテクチャに比べて 3 つの重要な利点が得られます。
障害発生時のパイプラインの堅牢性向上
実装するツールを選択する際の柔軟性の向上
独立して拡張可能なコンポーネント
ML を使用して世界最大の暗号エコシステムとそのユーザーを保護することに興味がありますか? 求人情報については、採用ページの Binance Engineering/AI をご覧ください。