
Stability AI は、Stable Diffusion 2 に関する新しい論文をブログで公開しました。その中で、Stability AI は、他の最先端の手法と比較してベンチマークを行いながら、以前のアルゴリズムよりも効率的で堅牢な新しいアルゴリズムを提案しています。

CompVis のオリジナルの Stable Diffusion V1 モデルは、オープンソース AI モデルの性質に革命をもたらし、世界中で何百もの異なるモデルと進歩を生み出しました。これは、Github のスター数が 10,000 に最速で増加したものの 1 つであり、2 か月足らずで 33,000 を獲得しました。これは、Github 上の他のプログラムよりも速い速度です。
オリジナルの Stable Diffusion V1 リリースは、Björn Ommer 教授が率いる LMU ミュンヘンの CompVis グループの Robin Rombach 氏 (Stability AI) と Patrick Esser 氏 (Runway ML) によるダイナミックなチームによって主導されました。彼らは、潜在拡散モデルに関するラボのこれまでの研究を基に構築し、LAION と Eleuther AI から重要なサポートを受けました。

 Stable Diffusion v1 と Stable Diffusion v2 の違いは何ですか?
Stable Diffusion v1 と Stable Diffusion v2 の違いは何ですか?
Stable Diffusion 2.0 には、以前のバージョンに比べて大幅に強化された機能が多数含まれているので、それらを見てみましょう。
Stable Diffusion 2.0 リリースには、LAION が Stability AI の支援を受けて開発した新しいテキスト エンコーダー (OpenCLIP) でトレーニングされた堅牢なテキストから画像への変換モデルが搭載されており、以前の V1 リリースに比べて生成される画像の品質が大幅に向上しています。このリリースのテキストから画像への変換モデルは、デフォルトの解像度 512×512 ピクセルと 768×768 ピクセルの画像を出力できます。
これらのモデルは、Stability AI の DeepFloyd チームによって生成された LAION-5B データセットの美的サブセットを使用してトレーニングされ、その後、LAION の NSFW フィルターを使用してアダルト コンテンツを除外するようにフィルタリングされます。
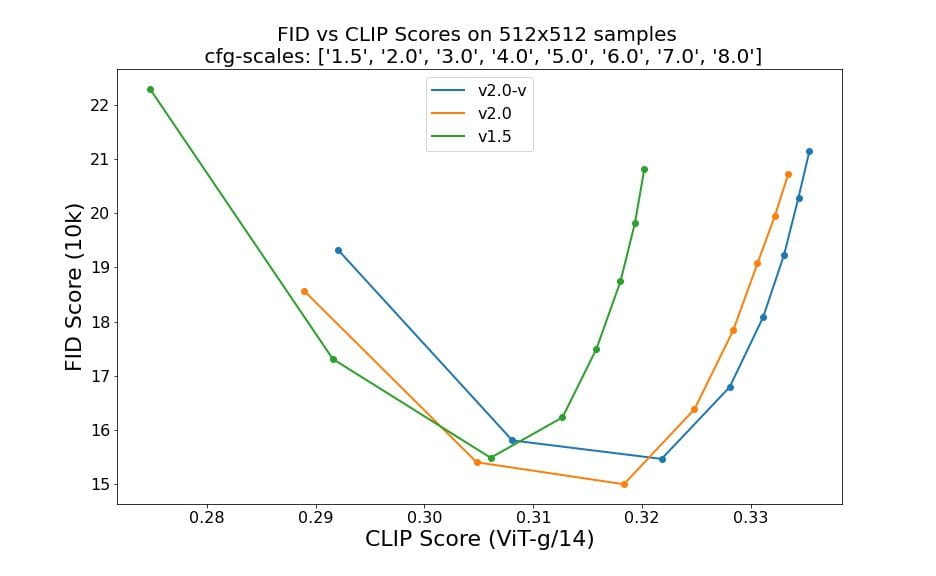
50 個の DDIM サンプル ステップ、50 個の分類子のないガイド スケール、および 1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0 を使用した評価では、チェックポイントの相対的な改善が示されています。
Stable Diffusion 2.0 には、画像の解像度を 4 倍に高める Upscaler Diffusion モデルが組み込まれました。低品質で生成された画像 (128×128) を高解像度の画像 (512×512) にアップスケールするモデルの例を以下に示します。Stable Diffusion 2.0 をテキストから画像への変換モデルと組み合わせると、2048×2048 以上の解像度の画像を生成できるようになりました。

新しい深度誘導安定拡散モデル depth2img は、V1 の以前の画像間機能をまったく新しいクリエイティブな可能性で拡張します。Depth2img は、入力画像の深度を (既存のモデルを使用して) 決定し、テキストと深度情報の両方に基づいて新しい画像を生成します。Depth-to-Image は、画像の一貫性と深度を維持しながら、元の画像とは大きく異なるように見える変更を提供する、新しいクリエイティブなアプリケーションを多数提供できます。
Stable Diffusion 2 の新機能は何ですか?
新しい安定した拡散モデルは、768×768 の解像度を提供します。
U-Net はバージョン 1.5 と同じ量のパラメータを持ちますが、最初からトレーニングされており、テキスト エンコーダーとして OpenCLIP-ViT/H を使用します。いわゆる v 予測モデルは SD 2.0-v です。
前述のモデルは、同じく公開されている SD 2.0 ベースから調整され、512×512 の画像で一般的なノイズ予測モデルとしてトレーニングされました。
x4 スケーリングの潜在テキストガイド拡散モデルが追加されました。
改良された SD 2.0 ベースの深度誘導安定拡散モデル。このモデルは、構造保存 img2img および形状条件付き合成に利用でき、MiDaS によって推定された単眼深度推定値に基づいて調整されます。
SD 2.0 基盤上に構築された、改良されたテキストガイドによる修復モデル。
開発者たちは、Stable Diffusion の最初のイテレーションと同様に、モデルを単一の GPU で実行できるように最適化するために懸命に取り組みました。最初からできるだけ多くの人が利用できるようにしたいと考えていたのです。彼らはすでに、何百万もの人々がこれらのモデルを手に入れ、協力して本当に素晴らしいものを作るとどうなるかを目にしています。これがオープンソースの力です。最先端のモデルをトレーニングするリソースはないかもしれませんが、そのモデルを使って素晴らしいことを実現する能力を持つ何百万人もの才能ある人々の大きな可能性を活用するのです。

この新しいアップデートは、depth2img や解像度のアップスケーリング機能の向上などの強力な新機能と組み合わせることで、多数の新しいアプリケーションの基盤となり、新たな創造的可能性の爆発的な拡大を可能にします。
安定拡散の詳細については、以下をご覧ください。
安定した拡散 AI が VR とメタバースの夢の世界を創造
アーティストは安定拡散法を使って初の完全AIアニメーション映画を制作した
ビデオインペインティングのご紹介: Stable Diffusion と Neural Atlases によるテキスト駆動型編集
Stability AI の Stable Diffusion 2 アルゴリズムがついに公開されました: 新しい depth2img モデル、超解像度アップスケーラー、アダルト コンテンツなし が最初に Metaverse Post に掲載されました。