
主なポイント
Binance は、高いボラティリティによって引き起こされる予期しないトラフィックの急増に対して容量管理を活用し、ビジネス需要に対して適切かつタイムリーなインフラストラクチャとコンピューティング リソースを確保します。
Binance は、ステージング環境ではなく本番環境で負荷テストを実施し、正確なサービス ベンチマークを取得します。この方法は、定義された負荷に対応するためにリソース割り当てが適切であることを検証するのに役立ちます。
Binance のインフラストラクチャは大量のトラフィックを処理しており、ユーザーが信頼できるサービスを維持するには、適切な容量管理と自動負荷テストが必要です。

Binance に特殊な容量管理プロセスが必要なのはなぜですか?
キャパシティ管理は、システム安定性の基盤です。キャパシティ管理には、現在および将来のビジネス需要に合わせて、適切なコストでアプリケーションとインフラストラクチャ リソースを適正規模に調整することが必要です。この目標を達成するために、当社はキャパシティ管理ツールとパイプラインを構築し、過負荷を回避して企業がスムーズなユーザー エクスペリエンスを提供できるように支援します。
暗号通貨市場では、従来の金融市場よりも定期的にボラティリティが発生することがよくあります。つまり、Binance のシステムは、ユーザーが市場の動きに反応するたびに発生するトラフィックの急増に耐える必要があります。適切な容量管理により、一般的なビジネス需要とトラフィックの急増シナリオに十分な容量を維持できます。この重要なポイントこそが、Binance の容量管理プロセスを独特で困難なものにしているのです。
プロセスを妨げ、サービスの遅延や利用不能につながる要因を見てみましょう。まず、通常、トラフィックの急激な増加によって発生する過負荷があります。たとえば、マーケティング イベント、プッシュ通知、さらには DDoS (分散型サービス拒否) 攻撃によって過負荷が発生する可能性があります。
トラフィックの急増と容量不足は、システムの機能に次のような影響を及ぼします。
サービスはますます多くの作業を引き受けます。
応答時間が増加し、クライアントのタイムアウト内にリクエストに応答できなくなります。この低下は通常、リソースの飽和 (CPU、メモリ、IO、ネットワークなど) またはサービス自体またはその依存関係での GC 一時停止の長時間化が原因で発生します。
その結果、サービスはリクエストを迅速に処理できなくなります。
プロセスを分解する
容量管理の一般原則について説明したので、次に Binance がこれをビジネスにどのように適用しているかを見てみましょう。ここでは、容量管理システムのアーキテクチャといくつかの主要なワークフローを簡単に紹介します。
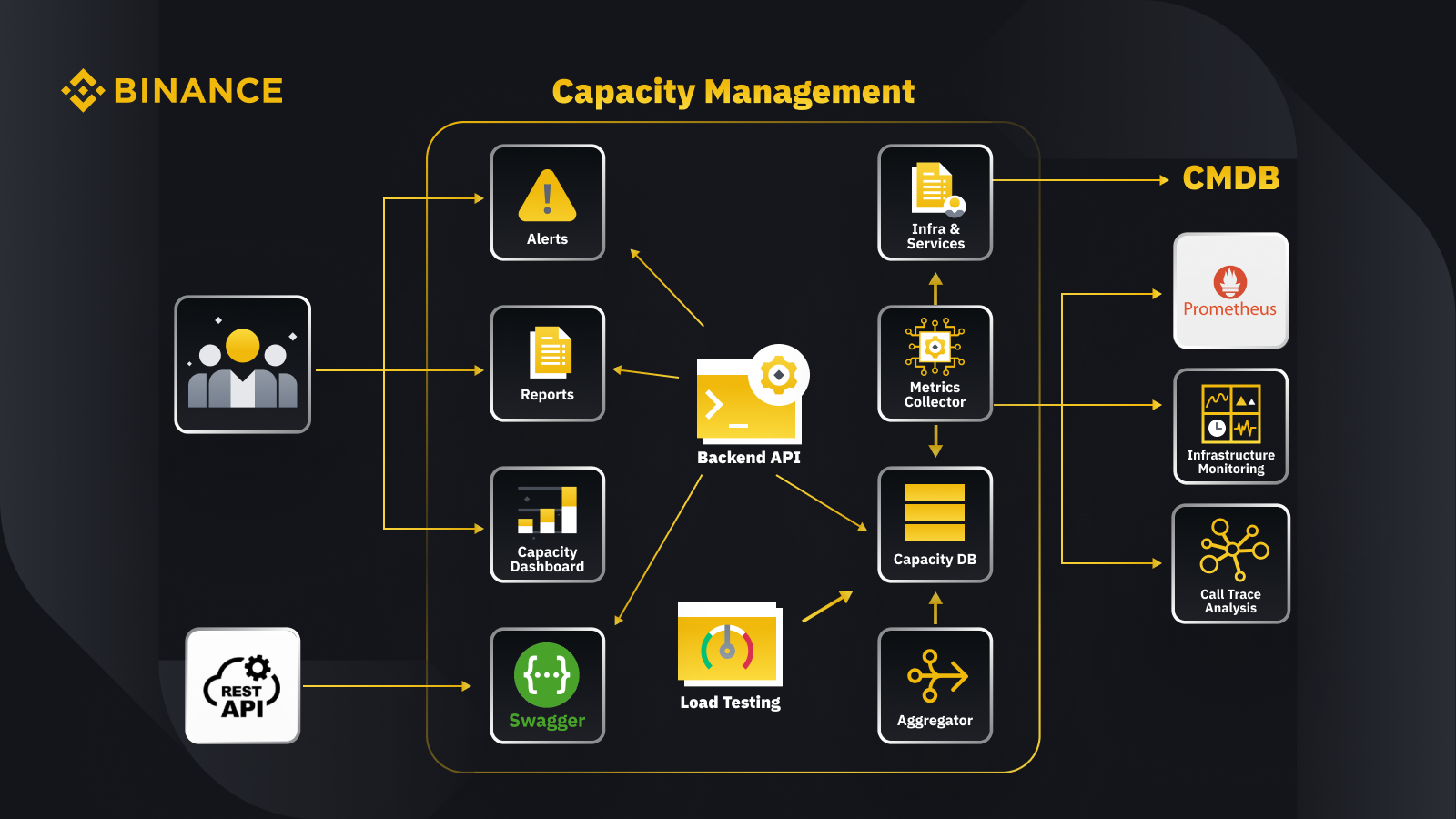
構成管理データベース (CMDB) からデータを取得して、インフラとサービスの構成を生成します。これらの構成内の項目が容量管理オブジェクトです。
メトリクス コレクターは、ビジネス層およびサービス層のデータについては Prometheus から、リソース層のメトリクスについては Infrastructure Monitoring から、トレース情報についてはコール トレース分析システムから容量メトリクスを取得します。メトリクス コレクターは、データを容量データベース (CDB) に保存します。
負荷テスト システムは、サービスに対してストレス テストを実行し、ベンチマーク データを CDB に保存します。
アグリゲータは、CDB から容量データを取得し、日次および過去最高 (ATH) ディメンションで集計します。集計後、集計されたデータを CDB に書き戻します。
バックエンド API は、CDB からのデータ処理により、容量ダッシュボード、アラート、レポート、および統合用の残りの API と関連容量データのインターフェイスを提供します。
関係者は、容量ダッシュボード、アラート、レポートを通じて容量に関する洞察を得ることができます。また、Swagger を使用した容量管理システムによって提供される REST API を使用してサービスの容量データを監視するなど、他の関連システムを使用することもできます。
戦略
当社の容量管理および計画戦略は、ピーク駆動型処理に依存しています。ピーク駆動型処理とは、ピーク使用時にサービスのリソース (Web サーバー、データベースなど) が経験するワークロードのことです。
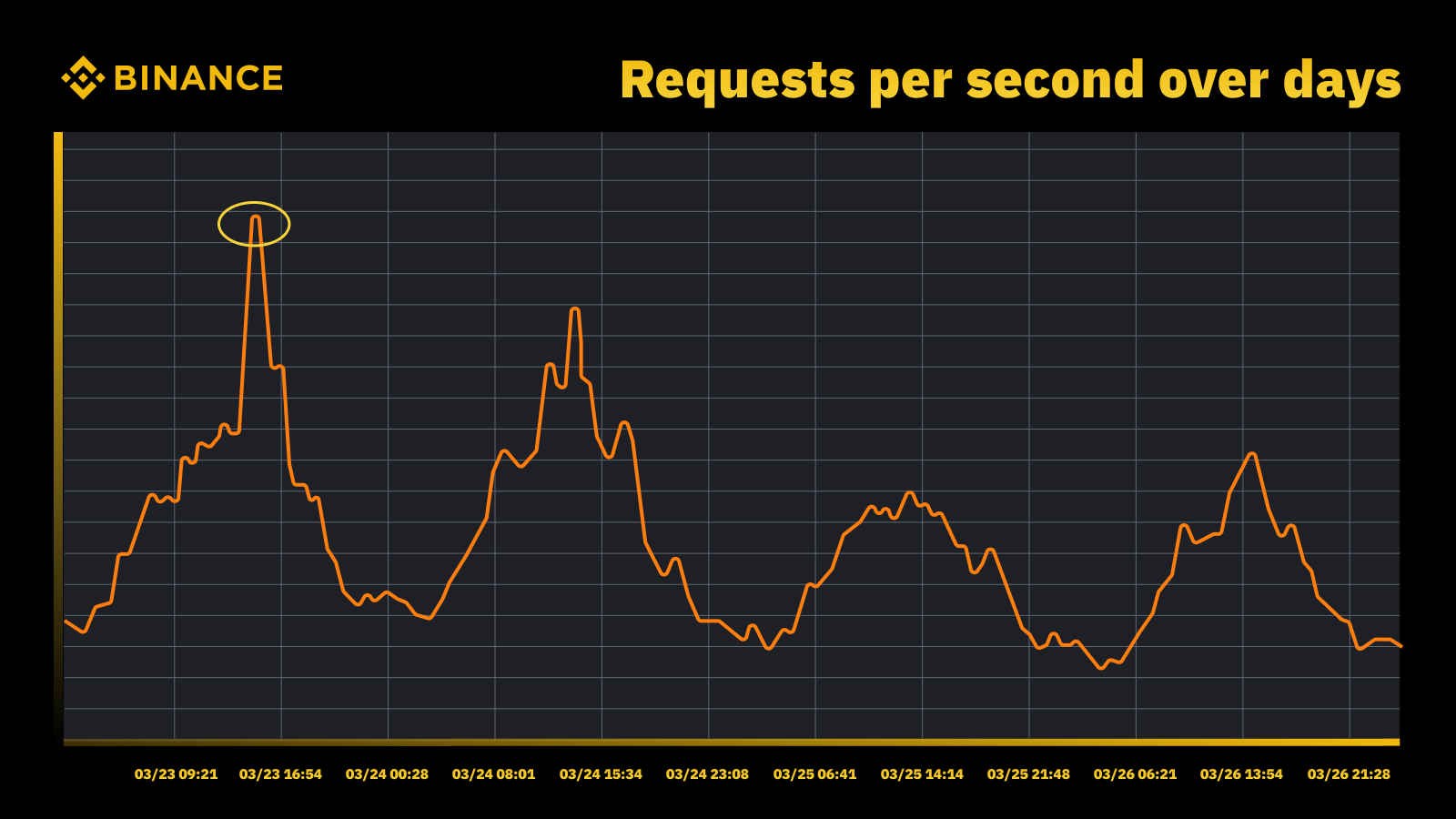
2023年3月にFRBが金利を引き上げると交通量が急増
定期的なピークを分析し、それを利用して容量の軌道を決定しています。ピーク駆動型リソースの場合と同様に、ピークがいつ発生するかを把握し、そのサイクル中に実際に何が起こっているかを調べます。
過負荷の防止とともに考慮するもう 1 つの重要な点は、自動スケーリングです。自動スケーリングは、サービスのインスタンスを増やして容量を動的に増加させることで過負荷に対処します。その後、過剰なトラフィックが分散され、サービスの 1 つのインスタンス (または依存関係) が処理するトラフィックは管理可能なままになります。
自動スケーリングは、その用途はありますが、過負荷状況の処理だけでは不十分です。通常、トラフィックの急激な増加に十分な速さで対応できず、徐々に増加する場合にのみ最適に機能します。
測定
測定は Binance の容量管理作業において重要な役割を果たしており、データの収集は最初の測定ステップです。情報技術インフラストラクチャ ライブラリ (ITIL) 標準に基づいて、容量管理サブプロセスで測定用のデータを収集します。
リソース - アプリケーション/サービスの使用状況によって決まる IT インフラストラクチャ リソースの消費。サーバー CPU、メモリ、ディスク ストレージ、ネットワーク帯域幅などの物理および仮想コンピューティング リソースの内部パフォーマンス メトリックに焦点を当てます。
サービス。ビジネス アクティビティから生じるアプリケーション レベルのパフォーマンス、SLA、レイテンシ、スループットの測定。サービス レイテンシ、スループット、ピークなど、ユーザーがサービスをどのように認識するかに基づく外部パフォーマンス メトリックに焦点を当てます。
ビジネス。注文、ユーザー登録、支払いなど、対象アプリケーションによって処理されるビジネス アクティビティを測定するデータを収集します。
インフラストラクチャ リソースの使用率のみに基づいた容量管理は、不正確な計画につながります。これは、インフラストラクチャ容量を推進する実際のビジネス ボリュームとスループットを反映していない可能性があるためです。
スケジュールされたイベントは、これについてさらに議論するのに最適な場です。Binance Live で Watch Web Summit 2022 に参加して、Crypto Box Rewards キャンペーンで最大 15,000 BUSD をシェアしましょう。基盤となるリソースとサービス レイヤーのメトリックとは別に、ビジネス ボリュームも考慮する必要がありました。ここでは、ライブ ストリーム視聴者の推定数、Crypto Box の最大インフライト リクエスト数、エンドツーエンドのレイテンシ、その他の要因などのビジネス メトリックに基づいてキャパシティ プランニングを行いました。
データの収集後、当社の容量管理プロセスは、特定の容量ドライバーに対して収集された多数のデータ ポイントを集約して要約します。メトリックの集約値は、容量アラート、レポート、およびその他の容量関連機能で使用できる単一の値です。
合計、平均、中央値、最小値、最大値、パーセンタイル、過去最高値 (ATH) など、いくつかのデータ集計方法を定期的なデータ ポイントに適用できます。

選択した方法によって、容量管理プロセスからの出力と、その結果としての決定が決まります。シナリオに応じて、さまざまな方法を選択します。たとえば、重要なサービスと関連データ ポイントには最大方法を使用します。最も高いトラフィックを記録するには、ATH 方法を使用します。
さまざまなユースケースでは、データ集約にさまざまな粒度タイプを使用します。ほとんどの場合、分、時間、日、または ATH のいずれかを使用します。
タイムリーな過負荷アラートを実現するために、サービスのワークロードを細かい粒度で測定します。
時間ごとに集計されたデータを使用して日次データを構築し、時間ごとのデータを集計して毎日のピークを記録します。
通常、容量レポートには毎日のデータを使用し、容量モデリングと計画には ATH データを活用します。
キャパシティ管理のコア メトリックの 1 つは、サービス ベンチマークです。これにより、サービスのパフォーマンスとキャパシティを正確に測定できます。サービス ベンチマークは負荷テストで取得しますが、これについては後で詳しく説明します。
優先度に基づいたキャパシティ管理
これまで、容量メトリックを収集し、さまざまな粒度でデータを集計する方法を見てきました。もう 1 つの重要な領域は優先順位です。これは、アラートや容量レポートのコンテキストで役立ちます。IT 資産をランク付けした後、限られたインフラストラクチャの使用とコンピューティング リソースが優先され、最初に重要なサービスとアクティビティに割り当てられます。
サービスとリクエストの重要度を定義する方法はいくつかあります。役に立つ参考資料は Google です。SRE の本では、重要度レベルが CRITICAL_PLUS、CRITICAL、SHEDDABLE_PLUS などと定義されています。同様に、P0、P1、P2 など、複数の優先度レベルを定義します。
優先度のレベルは次のように定義します。
P0: 最も重要なサービスとリクエスト。失敗した場合に、ユーザーに目に見える重大な影響が生じるもの。
P1: ユーザーに目に見える影響をもたらすサービスとリクエストですが、その影響は P0 よりも小さくなります。P0 および P1 サービスは、十分な容量でプロビジョニングされることが予想されます。
P2: これはバッチ ジョブとオフライン ジョブのデフォルトの優先度です。これらのサービスとリクエストは、部分的に利用できなくても、ユーザーに見える影響は発生しない可能性があります。
負荷テストとは何ですか? また、なぜ本番環境で負荷テストを使用するのですか?
負荷テストは、特定のワークロード下でアプリケーションのパフォーマンスをテストする非機能ソフトウェア テスト プロセスです。これにより、複数のエンドユーザーが同時にアクセスしているときにアプリケーションがどのように動作するかを判断することができます。
Binance では、本番環境で負荷テストを実行できるソリューションを作成しました。通常、負荷テストはステージング環境で実行されますが、全体的な容量管理の目標に基づいてこのオプションを使用することはできませんでした。本番環境で負荷テストを実行することで、次のことが可能になります。
実際の負荷条件下での当社のサービスの正確なベンチマークを収集します。
システムとその信頼性およびパフォーマンスに対する信頼を高めます。
実稼働環境でボトルネックが発生する前に、システムのボトルネックを特定します。
実稼働環境の継続的な監視を可能にします。
定期的に実行される標準化されたテスト サイクルにより、プロアクティブな容量管理が可能になります。
以下に、負荷テスト フレームワークといくつかの重要なポイントを示します。

Binance のマイクロサービス フレームワークには、TIP アプローチに不可欠な、構成駆動型およびフラグベースのトラフィック ルーティングをサポートする基本レイヤーがあります。
テスト対象のインスタンスを評価するために、自動カナリア分析 (ACA) を採用しています。監視システムで収集された主要なメトリックを比較するため、予期しない問題が発生した場合にはテストを一時停止/終了して、ユーザーへの影響を最小限に抑えることができます。
負荷テスト中にベンチマークとメトリックが収集され、動作とアプリケーションのパフォーマンスに関するデータ分析が生成されます。
API は、容量管理や品質保証など、さまざまなシナリオで貴重なパフォーマンス データを共有するために公開されています。これにより、オープン エコシステムの構築に役立ちます。
エンドツーエンドのテストの観点から、すべてのステップと制御ポイントを調整する自動化ワークフローを作成します。また、CI/CD パイプラインや運用ポータルなどの他のシステムと統合する柔軟性も提供します。
弊社の生産現場でのテスト(TIP)アプローチ
従来のパフォーマンス テスト アプローチ (シミュレートまたはミラーリングされたトラフィックを使用してステージング環境でテストを実行する) には、いくつかの利点があります。ただし、本番環境のようなステージング環境を展開すると、私たちのコンテキストではより多くの欠点があります。
インフラストラクチャのコストとメンテナンスの労力がほぼ2倍になります。
特に複数のビジネス ユニットにまたがる大規模なマイクロサービス環境では、エンドツーエンドを本番環境で動作させることは非常に複雑です。
必然的にステージングでデータを複製する必要が生じる可能性があるため、データのプライバシーとセキュリティのリスクがさらに高まります。
シミュレートされたトラフィックは、実際の運用環境で発生するものを再現することはできません。ステージング環境で取得されたベンチマークは不正確であり、価値が低くなります。
TIP とも呼ばれる本番環境でのテストは、シフトライト テスト手法であり、新しいコード、機能、リリースが本番環境でテストされます。私たちが採用した本番環境での負荷テストは、次のような点で非常に有益です。
システムの安定性と堅牢性を分析します。
さまざまなレベルのトラフィック、サーバー仕様、アプリケーション パラメータでのアプリケーションのベンチマークとボトルネックを検出します。
FlowFlagベースのルーティング
マイクロサービス ベース フレームワークに組み込まれた FlowFlag ベースのルーティングは、TIP を可能にする基盤です。これは、トラフィック分散に Eureka サービス ディスカバリを使用するアプリケーションなど、特定のケースに当てはまります。
図に示されているように、エントリ ポイントとしての Binance Web サーバーは、FlowFlag ヘッダーを使用して構成で指定されたトラフィックの一定の割合にラベルを付けます。負荷テスト中に、特定のサービスのホストを 1 つ選択し、構成でターゲット perf インスタンスとしてマークできます。その後、ラベルの付いた perf 要求は、処理のためにサービスに到達すると、最終的に perf インスタンスにルーティングされます。
完全に構成主導型でホットロードなので、新しいリリースを展開することなく、自動化を使用してワークロードの割合を簡単に調整できます。
このメカニズムはゲートウェイとベースパッケージの一部であるため、ほとんどのサービスに広く適用できます。
変更ポイントが 1 つであれば、ロールバックも簡単になり、本番環境でのリスクを軽減できます。

当社のソリューションをよりクラウドネイティブなものへと変革する一方で、パブリック クラウド プロバイダーや Kubernetes が提供する他のトラフィック ルーティングをサポートするために同様のアプローチを構築する方法についても検討しています。
ユーザーへの影響リスクを最小限に抑える自動カナリア分析
カナリア デプロイメントは、新しいソフトウェア バージョンを本番環境にデプロイする際のリスクを軽減するためのデプロイメント戦略です。通常、カナリア リリースと呼ばれるソフトウェアの新しいバージョンを、安定して実行されているバージョンと並行して、少数のユーザーにデプロイします。次に、2 つのバージョン間でトラフィックを分割し、受信リクエストの一部がカナリアに転送されるようにします。
カナリア バージョンの品質は、いわゆるカナリア分析によって評価されます。これは、古いバージョンと新しいバージョンの動作を説明する主要なメトリックを比較します。メトリックが大幅に低下している場合は、カナリアが中止され、すべてのトラフィックが安定バージョンにルーティングされ、予期しない動作の影響が最小限に抑えられます。
当社では、自動負荷テスト ソリューションの構築にも同じ概念を使用しています。このソリューションでは、Spinnaker を介した自動カナリア分析 (ACA) 用の Kayenta プラットフォームを使用して、自動カナリア デプロイメントを実現します。この方法に従う場合の一般的な負荷テスト フローは次のようになります。
ワークフローを通じて、指定されたとおりに、または限界点に達するまで、ターゲット ホストにトラフィック負荷 (例: 5%、10%、25%、50%) を段階的に追加します。
各負荷の下で、一定時間 (たとえば 5 分) Kayenta を使用してカナリア分析を繰り返し実行し、テスト対象ホストの主要なメトリックを、負荷前の期間をベースラインとして、現在の負荷後の期間を実験として比較します。
比較 (カナリア構成モデル) では、ターゲット ホストが次の条件を満たしているかどうかの確認に重点が置かれます。
リソース制約に達します。例: CPU 使用率が 90% を超えます。
エラー ログ、HTTP 例外、レート制限拒否などの失敗メトリックが大幅に増加します。
コア アプリケーションのメトリックが依然として妥当であるか (例: HTTP レイテンシが 2 秒未満 (サービスごとにカスタマイズ可能))
分析ごとに、Kayenta は結果を示すレポートを提供し、失敗するとテストは直ちに終了します。
この障害検出には通常 30 秒もかからないため、エンドユーザーのエクスペリエンスに影響を与える可能性が大幅に減ります。

データ分析の有効化
前述のすべてのプロセスとテスト実行に関する十分な情報を収集することが重要です。最終的な目標はシステムの信頼性と堅牢性を向上させることですが、これはデータの洞察なしには不可能です。
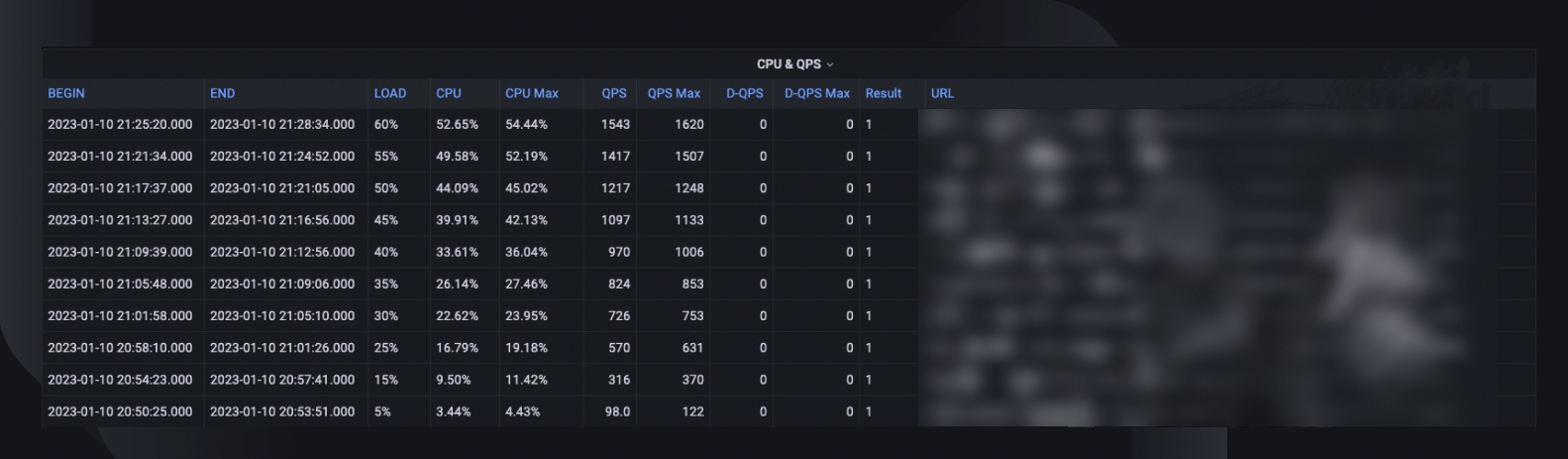
全体的なテストの概要には、ホストが処理できた最大負荷率、ピーク時の CPU 使用率、およびホストの QPS が記録されます。これに基づいて、サービスの過去最高の QPS を考慮して、容量予約を満たすために展開する必要があるインスタンスの数も推定されます。
分析に役立つその他の貴重な情報には、ソフトウェアのバージョン、サーバーの仕様、デプロイされた数、テスト中に何が起こったかを振り返ることができるモニター ダッシュボードへのリンクなどがあります。

ベンチマーク曲線は、過去 3 か月間のパフォーマンスの変化を示し、特定のアプリケーション リリースに関連する可能性のある問題を発見できます。

CPU と QPS の傾向は、CPU 使用率とサーバーが処理する必要のあるリクエスト量との相関関係を示します。このメトリックは、受信トラフィックの増加に対するサーバーの余裕を見積もるのに役立ちます。
API レイテンシ動作は、上位 5 つの API について、さまざまな負荷条件下での応答時間の変化をキャプチャします。その後、必要に応じて個々の API レベルでシステムを最適化できます。

API 負荷分散メトリックは、API 構成がサービス パフォーマンスにどのように影響するかを理解し、改善領域に関するより詳細な情報を得るのに役立ちます。
標準化と製品化
当社のシステムは成長と進化を続けており、サービスの安定性と信頼性を継続的に追跡し、改善していきます。私たちは以下の方法でこれを継続します。
重要なサービスに対する定期的かつ確立された負荷テスト スケジュール。
CI/CD パイプラインの一部としての自動負荷テスト。
組織全体にわたる大規模な導入に備えるために、ソリューション全体の製品化を強化します。
制限事項
現在の負荷テストのアプローチにはいくつかの制限があります。
FlowFlag ベースのルーティングは、当社のマイクロサービス フレームワークにのみ適用できます。当社は、クラウド ロード バランサーや Kubernetes Ingress の一般的な重み付けルーティング機能を活用して、より多くのルーティング シナリオにソリューションを拡張することを検討しています。
テストは実際の本番環境のユーザー トラフィックに基づいているため、特定の API やユース ケースに対して機能テストを実行することはできません。また、ボリュームが非常に少ないサービスの場合、ボトルネックを特定できない可能性があるため、価値は限られます。
これらのテストは、エンドツーエンドの呼び出しチェーンをカバーするのではなく、個々のサービスに対して実行します。
運用環境でのテストでは、障害が発生した場合に実際のユーザーに影響を与えることがあります。そのため、完全な自動化機能を備えた障害分析と自動ロールバックが必要です。
終わりに
システムの過負荷を防ぎ、稼働時間を確保するには、トラフィックの急増シナリオについて考えることが重要です。そのため、この記事で説明した容量管理と負荷テストのプロセスを構築しました。要約すると、次のようになります。
当社の容量管理はピーク主導型で、サービスライフサイクルの各段階に組み込まれており、測定、優先順位の設定、アラート、容量レポートなどのアクティビティによる過負荷を防止します。これが最終的に、Binance のプロセスとニーズを一般的な容量管理状況と比較してユニークなものにしているのです。
負荷テストから得られるサービス ベンチマークは、キャパシティ管理と計画の焦点です。これにより、現在および将来のビジネス需要をサポートするために必要なインフラストラクチャ リソースが正確に決定されます。最終的には、当社の特定のニーズを満たすことができる Binance 独自のソリューションを使用して、これを本番環境で実行する必要がありました。
これらすべてをまとめると、適切な計画と徹底したフレームワークが、Binancians が知っていて楽しんでいるサービスの作成に役立つことがおわかりいただけると思います。
参考文献
ドミニク・オグボンナ、キャパシティ管理のA-Z: エンタープライズIT監視とキャパシティプランニングの実装のための実践ガイド、第4章、第6章
Luis Quesada Torres、Doug Colish、SRE キャパシティ管理のベスト プラクティス
Alejandro Forero Cuervo、Sarah Chavis、Google SRE ブック、第 21 章 - 過負荷の処理
さらに読む
(ブログ) Binance Ledger が Binance 体験をどのように強化するか
(ブログ) Binance Oracle VRF の紹介: 検証可能なランダム性の次世代
(ブログ) Binance がパスキー実装の準備として FIDO アライアンスに参加