
正確で一貫性があり、本番環境に対応した機械学習機能を提供します。

この記事では、機械学習 (ML) 機能ストアについて詳しく説明します。これは、ML パイプライン インフラストラクチャ全体のより広範な概要を提供する前回のブログ投稿の続きです。
なぜフィーチャーストアを使用するのですか?
パイプラインの多くの部分のうちの 1 つである特徴ストアは、システムで最も重要な歯車であると言えます。その主な目的は、モデルのトレーニングや推論のために送信される前に特徴を管理する中央データベースとして機能することです。
この用語に馴染みがない方のために説明すると、特徴とは本質的には生データであり、特徴エンジニアリングと呼ばれるプロセスを通じて、ML モデルが自分自身をトレーニングしたり予測を計算したりするために使用できるように、より使いやすいものに精製されます。
簡単に言うと、フィーチャー ストアを使用すると次のことが可能になります。
さまざまなモデルやチーム間で機能を再利用および共有する
ML実験に必要な時間を短縮
トレーニングとサービングの大きな偏りによる不正確な予測を最小限に抑える
機能ストアの重要性をよりよく理解するために、機能ストアを使用しない ML パイプラインの図を示します。
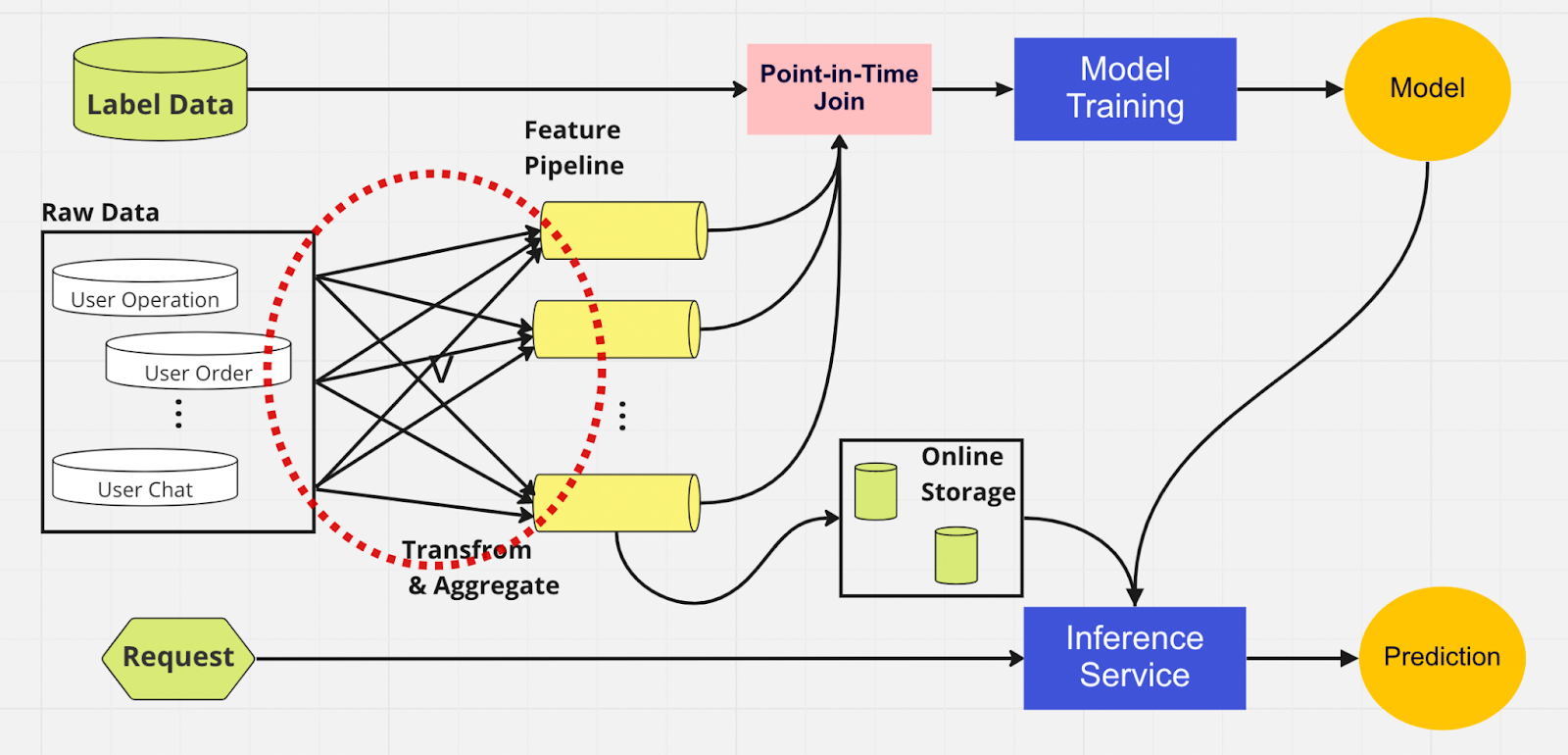
このパイプラインでは、モデル トレーニングと推論サービスの 2 つの部分で、どの機能がすでに存在し、再利用できるかを識別できません。これにより、ML パイプラインで機能エンジニアリング プロセスが重複することになります。図の赤い円でわかるように、ML パイプラインは機能を再利用する代わりに、重複した機能と冗長なパイプラインの塊を構築しています。この塊を機能パイプラインのスプロールと呼びます。
ビジネスが成長し、プラットフォームを利用するユーザーが増えるにつれて、こうした機能の拡散を維持することは、ますますコストがかかり、管理不能な状況になります。このように考えてみましょう。データ サイエンティストは、作成する新しいモデルごとに、長くて面倒な機能エンジニアリング プロセスを最初から完全に開始する必要があります。
さらに、特徴ロジックの再実装が多すぎると、トレーニング サービング スキューと呼ばれる概念が発生します。これは、トレーニング段階と推論段階のデータ間の不一致です。これにより、予測が不正確になり、モデルの動作が予測不能になり、本番環境でのトラブルシューティングが難しくなります。特徴ストアが導入される前は、データ サイエンティストがサニティ チェックを使用して特徴の一貫性をチェックしていました。これは手動で時間のかかるプロセスであり、モデリングや洞察に富んだ特徴エンジニアリングなどの優先度の高いタスクから注意をそらすことになります。それでは、特徴ストアを使用した ML パイプラインについて見ていきましょう。

他のパイプラインと同様に、左側に同じデータ ソースと機能があります。ただし、複数の機能パイプラインを経由するのではなく、ML パイプラインの両方のフェーズ (モデル トレーニングと推論サービス) に対応する 1 つの中央ハブとして機能ストアを使用します。重複する機能はありません。変換や集約など、機能を構築するために必要なすべてのプロセスは、1 回だけ実行する必要があります。
データ サイエンティストは、カスタム構築された Python SDK を使用して機能ストアと直感的に対話し、下流の ML モデルのトレーニングと推論のための機能を検索、再利用、発見できます。
本質的に、特徴ストアは両方のフェーズを統合する集中型データベースです。また、特徴ストアはトレーニングと推論の一貫した特徴を保証するため、トレーニングとサービングの偏りを大幅に削減できます。
フィーチャー ストアは、上で述べた点よりもはるかに多くのことを行います。もちろん、これはフィーチャー ストアを使用する理由のより基本的な要約であり、さらにいくつかの単語に分解できます。つまり、可能な限り最速かつ簡単な方法でフィーチャーを準備し、ML モデルに送信することです。
フィーチャーストアの内部

上の図は、AWS SageMaker Feature Store、Google vertex AI (Feast)、Azure (Featr)、Iguazio、Tetcom などの一般的な機能ストアのレイアウトを示しています。すべての機能ストアは、オンラインとオフラインの 2 種類のストレージを提供します。
オンライン機能ストアはリアルタイム推論に使用され、オフライン機能ストアはバッチ予測とモデルトレーニングに使用されます。ユースケースが異なるため、パフォーマンスを評価するために使用するメトリックはまったく異なります。オンライン機能では、低レイテンシを求めます。オフライン機能ストアでは、高スループットを求めます。
開発者は、テクノロジースタックに基づいて、任意のエンタープライズ機能ストアまたはオープンソースを選択できます。下の図は、AWS SageMaker Feature Store のオンラインストアとオフラインストアの主な違いを示しています。

オンライン ストア: 機能の最新のコピーを保存し、低ミリ秒のレイテンシで提供します。レイテンシの速度はペイロード サイズによって異なります。8 つの機能グループと合計 55 の機能を持つアカウント乗っ取り (ATO) モデルの場合、レイテンシは約 30 ミリ秒 (p99) です。
オフライン ストア: すべての履歴機能を追跡し、タイム トラベルを有効にしてデータ漏洩を回避できる追加専用ストアです。データは、読み取り効率を高めるために時間分割された parquet 形式で保存されます。
機能の一貫性に関しては、機能グループがオンラインとオフラインの両方で使用できるように構成されている限り、機能がオンライン ストアに取り込まれる間、データは自動的に内部的にオフライン ストアにコピーされます。
Feature Store はどのように使用しますか?

上に示したコードには多くの複雑さが隠されています。特徴ストアを使用すると、モデルのトレーニングと推論のための Python インターフェイスを簡単にインポートできます。
機能ストアを使用すると、データ サイエンティストは、バックエンドでの面倒なデータ エンジニアリング プロセスを気にすることなく、簡単に機能を定義し、新しいモデルを構築できます。
フィーチャーストアの使用に関するベストプラクティス
前回のブログ投稿では、ストア レイヤーを使用して機能を集中型 DB に取り込む方法について説明しました。ここでは、機能ストアを使用する際のベスト プラクティスを 2 つ紹介します。
変更されていない機能は取り入れない
機能を2つの論理グループに分けます。アクティブなユーザー操作と非アクティブなユーザー操作です。
次の例を考えてみましょう。オンライン機能ストアの PutRecord に 10K TPS のスロットル制限があるとします。この仮定を使用して、1 億人のユーザーの機能を取り込みます。一度にすべてを取り込むことはできず、現在の速度では完了するまでに約 2.7 時間かかります。これを解決するために、最近更新された機能のみを取り込むことを選択します。たとえば、前回取り込まれてから値が変更されていない場合は、機能を取り込みません。
2 つ目のポイントとして、一連の機能を 1 つの論理機能グループにまとめるとします。一部はアクティブですが、大部分は非アクティブです。つまり、ほとんどの機能は変更されていません。論理的な手順としては、アクティブと非アクティブを 2 つの機能グループに分割して、取り込みプロセスを迅速化することが考えられます。
非アクティブな機能については、機能パイプラインで 1 億人のユーザー向けに機能ストアに取り込む必要があるデータの 95% を 1 時間ごとに削減します。さらに、アクティブな機能に必要なデータの 20% も削減します。そのため、バッチ取り込みパイプラインでは、1 億人のユーザー分の機能を 3 時間ではなく 10 分で処理します。
終わりに
要約すると、特徴ストアを使用すると、トレーニングと推論の一貫性を維持しながら、特徴を再利用し、特徴エンジニアリングを迅速化し、不正確な予測を最小限に抑えることができます。
ML を使用して世界最大の暗号エコシステムとそのユーザーを保護することに興味がありますか? 求人情報については、採用ページの Binance Engineering/AI をご覧ください。
参考文献:
(ブログ) MLOps を使用してリアルタイムのエンドツーエンドの機械学習パイプラインを構築する