

原題:「GPT-1 から GPT-4 まで、ChatGPT の台頭を見る」
原著者: Alpha Rabbit Research Notes
ChatGPTとは何ですか?

ChatGPTとは何ですか?
最近、OpenAI は対話形式で対話できるモデルである ChatGPT をリリースし、そのインテリジェンスにより多くのユーザーに歓迎されています。 ChatGPT は、OpenAI によって以前にリリースされた InstructGPT の親戚でもあります。ChatGPT モデルは、RLHF (人間によるフィードバックによる強化学習) を使用してトレーニングされます。おそらく、ChatGPT の登場は、OpenAI の GPT-4 の正式リリースの前段階でもあります。
GPTとは何ですか? GPT-1からGPT-3へ
Generative Pre-trained Transformer (GPT) は、インターネット上で入手可能なデータでトレーニングされたテキスト生成深層学習モデルです。質問応答、テキスト要約、機械翻訳、分類、コード生成、会話型 AI に使用されます。
2018 年は GPT-1 が誕生し、NLP (自然言語処理) の事前トレーニング モデルの元年でもありました。パフォーマンスの点では、GPT-1 は一定の汎化能力を備えており、監視タスクとは関係のない NLP タスクでも使用できます。一般的なタスクは次のとおりです。
自然言語推論: 2 つの文間の関係 (包含、矛盾、中立性) を判断します。
問答と常識推論: 記事と複数の回答を入力し、回答の正確さを出力します。
意味的類似性の認識: 2 つの文が意味的に関連しているかどうかを判断します。
カテゴリ: 入力テキストがどのカテゴリに属するかを決定します。
GPT-1 は、調整されていないタスクにはある程度の効果がありますが、その汎化能力は、調整された教師ありタスクに比べてはるかに低いため、会話型 AI というよりは、かなり優れた言語理解ツールとしか考えられません。
GPT-2 も予定どおり 2019 年に登場しました。ただし、GPT-2 は元のネットワークにあまり多くの構造革新や設計を実行せず、より多くのネットワーク パラメーターとより大きなデータ セットを使用しただけで、最大モデル合計 48 層がありました。学習ターゲットは教師なし事前トレーニング モデルを使用して教師ありタスクを実行します。パフォーマンスの面では、理解能力に加えて、GPT-2 は、この世代で初めて、要約を読んだり、チャットしたり、書き続けたり、物語をでっち上げたり、さらにはフェイク ニュース、フィッシング メール、ロールプレイングを生成したりする強力な才能を示しました。オンラインでも問題ありません。 「大きくなった」後、GPT-2 はその普遍的で強力な機能を実証し、複数の特定の言語モデリング タスクで当時最高のパフォーマンスを達成しました。
その後、教師なしモデル (現在は自己教師ありモデルと呼ばれることが多い) として GPT-3 が登場し、問題指向検索、読解、意味推論、機械翻訳などの自然言語処理のほとんどのタスクを完了できます。 、記事生成や自動質疑応答など。さらに、このモデルは、フランス語から英語、ドイツ語から英語の機械翻訳タスクで現在の最先端レベルに達するなど、多くのタスクで良好なパフォーマンスを発揮します。自動生成された記事では、人間と機械を区別することはほとんど不可能です。 52% の精度)、ランダムな推測に匹敵します)、そしてさらに驚くべきことは、2 桁の加算および減算タスクでほぼ 100% の精度を達成し、タスクの説明に基づいてコードを自動生成することもできることです。教師なしモデルには多くの機能と優れた効果があり、人々は一般的な人工知能への期待を感じているようです。これが GPT-3 が大きな影響を与える主な理由かもしれません。
GPT-3 モデルとは一体何ですか?
実際、GPT-3 は単純な統計言語モデルです。機械学習の観点から見ると、言語モデルは単語シーケンスの確率分布をモデル化します。つまり、発話された断片を条件として使用して、次の瞬間に出現するさまざまな単語の確率分布を予測します。一方で、言語モデルは、文が言語文法にどの程度準拠しているかを測定できます(たとえば、人間とコンピュータの対話システムによって自動的に生成された応答が自然で流暢であるかどうかを測定します)。新しい文を予測して生成します。たとえば、「正午です。一緒にレストランに行きましょう」というクリップの場合、言語モデルは「レストラン」の後に出現する可能性のある単語を予測できます。一般的な言語モデルは、次の単語が「食べる」であると予測します。強力な言語モデルは、時間情報を取得し、コンテキストに適合する単語「昼食を食べる」を予測できます。
通常、言語モデルが強力であるかどうかは、主に 2 つの点に依存します。1 つは、モデルがすべての歴史的コンテキスト情報を利用できるかどうかです。上記の例では、「正午 12 時」という長距離の意味情報を取得できない場合、言語モデルは、「昼食をとる」という 1 つの単語を次回予測することはほとんど不可能です。第二に、モデルが学習するのに十分な歴史的コンテキストが存在するかどうか、つまりトレーニング コーパスが十分に豊富であるかどうかにも依存します。言語モデルは自己教師あり学習であるため、最適化の目標は、表示されるテキストの言語モデルの確率を最大化することであるため、ラベルを付けずに任意のテキストをトレーニング データとして使用できます。
GPT-3 はパフォーマンスが向上し、パラメーターが大幅に増加したため、より多くのトピック テキストが含まれており、前世代の GPT-2 よりも明らかに優れています。現在利用可能な最大の高密度ニューラル ネットワークである GPT-3 は、Web ページの説明を対応するコードに変換し、人間の物語を模倣し、カスタム詩を作成し、ゲーム スクリプトを生成し、さらには亡くなった哲学者を模倣して、人生の真の意味を予測することができます。また、GPT-3 は微調整を必要とせず、難しい文法問題に対処するために必要な出力タイプのサンプルをいくつか (少量の学習) するだけです。 GPT-3 は、言語専門家にとって私たちの想像力をすべて満たしてくれたと言えます。
注:上記は主に以下の記事を参照しています。
1. GPT 4 はまもなくリリースされ、人間の脳に匹敵します。業界の多くの大手企業が黙ってはいません。 -Xu Jiecheng、Yun Zhao -パブリックアカウント51 CTOテクノロジースタック- 2022-11-24 18:08
2. GPT-3 に関するあなたの好奇心に 1 つの記事で答えます! GPT-3とは何ですか?なぜそんなに優れているのでしょうか? -張家軍、中国科学院オートメーション研究所、北京で2020-11-11 17:25に公開
3.バッチ: 329 | InstructGPT、よりフレンドリーで優しい言語モデル - パブリック アカウント DeeplearningAI-2022-02-07 12:30
GPT-3の問題点は何ですか?
しかし、GTP-3 は完璧ではありません。人工知能に関して人々が最も懸念している主な問題の 1 つは、チャットボットやテキスト生成ツールが、インターネット上のすべてのテキストを無差別かつ高品質で学習する可能性があることです。あるいは攻撃的な言語出力が生成されると、次のアプリケーションに完全に影響を及ぼします。
OpenAI は、より強力な GPT-4 が近い将来リリースされることも提案しています。
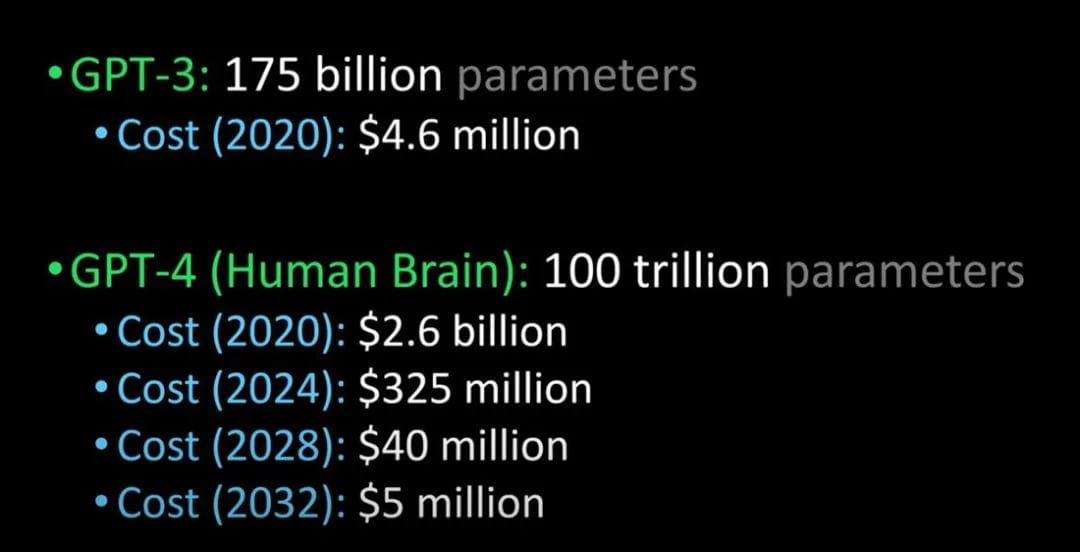
GPT-3 と GPT-4 および人間の脳の比較 (画像クレジット: Lex Fridman @youtube)
GPT-4は来年リリースされる予定で、チューリングテストをクリアし、人間と見分けがつかないほどの高性能になるといわれており、また、企業の導入コストも大幅に削減されるとのこと。
ChatGP と InstructGPT
ChatGPT と InstructGPT
Chatgpt について話すときは、その「前身」である InstructGPT について話さなければなりません。
2022 年の初めに、OpenAI は InstructGPT をリリースしました。この研究では、OpenAI は、GPT-3 と比較して、より現実的で、より無害で、ユーザーの意図によく従う言語モデルをトレーニングするためにアラインメント リサーチを使用しました。 InstructGPT は、新しく、微調整されたものです。有害で非現実的で偏った出力を最小限に抑える GPT-3 のバージョン。
InstructGPT はどのように機能しますか?
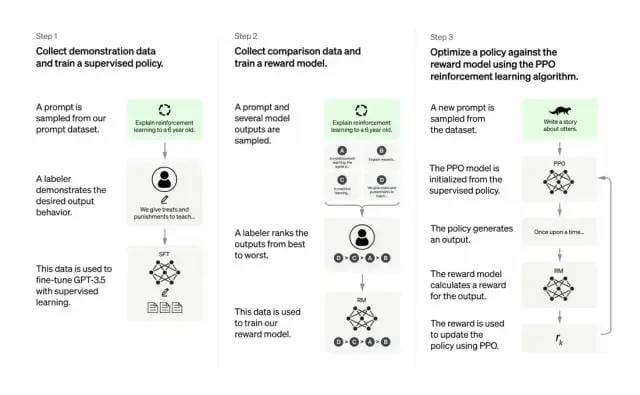
開発者は、教師あり学習と人間のフィードバックからの強化学習を組み合わせてこれを行います。 GPT-3の出力品質を向上させるため。このタイプの学習では、人間がモデルの潜在的な出力をランク付けします。強化学習アルゴリズムは、高レベルの出力と同様の内容を生成するモデルに報酬を与えます。
トレーニング データセットは、プロンプトを作成することから始まります。その一部は、「カエルについての話をしてください」や「6 歳児に月面着陸について数文で説明してください」など、GPT-3 ユーザーからの入力に基づいています。 」
開発者はプロンプトを 3 つの部分に分割し、各部分に異なる応答を作成しました。
人間のライターは最初の一連のプロンプトに応答します。開発者はトレーニング済み GPT-3 を微調整し、それを InstructGPT に変換して、各プロンプトに対する既存の応答を生成しました。
次のステップは、より良い応答に対してより高い報酬を与えるようにモデルをトレーニングすることです。 2 番目のプロンプト セットでは、最適化されたモデルは複数の応答を生成します。人間の評価者が各回答をランク付けします。プロンプトと 2 つの応答が与えられた場合、報酬モデル (別の事前トレーニング済み GPT-3) は、高評価の応答に対してはより高い報酬を計算し、低評価の応答に対してはより低い報酬を計算することを学習しました。
開発者は、3 番目のヒント セットと強化学習手法である Proximal Policy Optimization (PPO) を使用して、言語モデルをさらに微調整しました。プロンプトが与えられると、言語モデルは応答を生成し、報酬モデルはそれに応じて報酬を与えます。 PPO は報酬を使用して言語モデルを更新します。
この段落の参照: The Batch: 329 | InstructGPT、よりフレンドリーで優しい言語モデル - パブリック アカウント DeeplearningAI- 2022-02-07 12:30
何が重要ですか?核心は、人工知能は責任ある人工知能である必要があるということです
OpenAI の言語モデルは、教育、仮想セラピスト、筆記補助、ロールプレイング ゲームなどの分野で役立ちます。これらの分野では、社会的偏見、誤った情報、有害な情報の存在がより厄介であり、これらの欠陥を回避できるシステムは、より有能になる。
Chatgpt と InstructGPT のトレーニング プロセスの違いは何ですか?
一般に、Chatgpt は、上記の InstructGPT と同様に、RLHF (ヒューマン フィードバックからの強化学習) を使用してトレーニングされます。違いは、データをトレーニング用にセットアップする (および収集する) 方法です。 (ここでの説明: 以前の InstructGPT モデルは入力に対して出力を提供し、それをトレーニング データと比較しました。はい、報酬はありましたがペナルティはありませんでした。現在の Chatgpt は入力であり、モデルは複数の出力を提供し、その後人々がこの出力結果の並べ替えにより、モデルはこれらの結果を「より人間らしいもの」から「ナンセンスなもの」までランク付けできるようになり、この戦略は教師あり学習と呼ばれます。Zhang Zijie 博士に感謝します。この段落)
ChatGPT の制限は何ですか?
次のように:
a) トレーニングの強化学習 (RL) フェーズでは、特定の真実の情報源や質問に対する標準的な回答はありません。
b) モデルはより慎重になるようにトレーニングされており、(プロンプトの誤検知を避けるために) 回答を拒否する場合があります。
c) 教師ありトレーニングは、モデルがランダムな応答セットを生成し、人間のレビュー担当者のみが良い/上位ランクの応答を選択するのではなく、モデルを誤解させたり、理想的な答えを知る方向にバイアスしたりする可能性があります。
注: ChatGPT は言葉遣いに敏感です。 、場合によっては、モデルがフレーズに応答しなくなることがありますが、質問/フレーズを少し調整すると、最終的には正しく応答するようになります。トレーナーは、より包括的であるように見える可能性があるため、長い回答を好む傾向があり、その結果、モデル内の特定のフレーズがより長くなり、最初のプロンプトや質問があいまいな場合、モデルは適切に説明を求めなくなります。
ChatGPT が自ら認識している制限は次のとおりです。
もっともらしいが間違っている回答:
a) トレーニングの強化学習 (RL) フェーズ中にこの問題を修正するための実際の情報源は存在しません。
b) モデルをより慎重にトレーニングすると、誤って回答を拒否する可能性があります (問題のあるプロンプトの誤検知)。
c) 教師ありトレーニングは、モデルがランダムな応答セットを生成し、人間のレビュー担当者だけが優れた/高ランクの応答を選択するのではなく、モデルが理想的な回答を認識する傾向があるため、誤解や偏りが生じる可能性があります。ChatGPT はフレーズに敏感です。モデルがフレーズに対して応答しないこともありますが、質問/フレーズを少し調整するだけで、正しく回答できるようになります。
トレーナーは、より包括的に見える長い回答を好むため、冗長な回答や特定のフレーズの過剰使用に偏る傾向があります。最初のプロンプトまたは質問があいまいな場合、モデルは適切に説明を求めません。モデレーション API を介して不適切なリクエストを拒否する安全レイヤーが実装されています。ただし、偽陰性および偽陽性の回答が依然として予想されます。
参考文献:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 はまもなくリリースされ、人間の脳に匹敵します。業界の多くの大手企業が黙ってはいません。 -Xu Jiecheng、Yun Zhao -パブリックアカウント51 CTOテクノロジースタック- 2022-11-24 18:08
5. GPT-3 に関するあなたの好奇心に 1 つの記事で答えます! GPT-3とは何ですか?なぜそんなに優れているのでしょうか? -張家軍中国科学院オートメーション研究所 2020-11-11 17:25に北京で公開
6.バッチ: 329 | InstructGPT、よりフレンドリーで優しい言語モデル - パブリック アカウント DeeplearningAI-2022-02-07 12:30