Continuando dai due articoli precedenti su questioni che richiedono attenzione nel trading programmatico:
Merci secche hard-core: dettagli e riflessioni sul commercio automatizzato in tempo reale dei sistemi di commercio quantitativo (1. Problemi e difficoltà)
Sistema di trading quantitativo - Dettagli e riflessioni sull'offerta aziendale automatizzata (2. Scopo dell'offerta aziendale)
Qui continueremo a parlare di alcune abilità di gestione dettagliate nella progettazione del codice.
Banca dati
Come accennato nei due articoli precedenti, la registrazione dello stato di una combinazione di strategie più complessa è molto importante e richiede l’utilizzo di un database.
In effetti, la maggior parte delle attività di programmazione può essere classificata nella categoria CRUD, ovvero il processo principale consiste semplicemente nell'aggiunta, eliminazione, modifica e controllo del database. I codici commerciali non fanno eccezione. Il comportamento di negoziazione sul mercato secondario a media e bassa frequenza non è in realtà molto diverso da quando le persone acquistano e vendono un determinato tesoro. Il focus del trading automatizzato risiede nella gestione dello stato strategico.
Se non hai già familiarità con i database relazionali come SQL, ti consigliamo di imparare direttamente a utilizzare i database in memoria NoSQL come Redis. I suoi vantaggi sono che è facile da avviare, ha prestazioni eccellenti ed è intrinsecamente a thread singolo. Non è necessario considerare operazioni di basso livello come il blocco dei dati durante la lettura e la scrittura. Lo svantaggio però è che non esiste una chiave primaria e non è possibile realizzare funzioni come l'incremento automatico del numero. Se necessario, devi scrivere il codice per implementarlo tu stesso. Tuttavia, non ho mai utilizzato questa funzione nel trading automatizzato per così tanto tempo.
Un altro problema non importante è che per i database in memoria, se la quantità di dati che devono essere archiviati è relativamente grande, la memoria del server deve essere più grande. Tuttavia, per il trading quantitativo generale, 4G o anche 2G di memoria sono sufficienti e lo sono non è necessario. Salva così tanti dati.
Redis è davvero potente nel mondo reale Se la tua strategia ha requisiti ad alta frequenza, può anche implementare il modello di sottoscrizione dei messaggi pub/sub, eliminando la necessità di aggiungere vari moduli MQ aggiuntivi. Se utilizzi un database relazionale come MySQL, come accennato in precedenza, a patto di non averlo mai utilizzato nella pratica, dovrai investire tempo ed energie nell'apprendimento di SQL, un linguaggio di programmazione relativamente disgustoso e difficile. Tieni presente che tutti sono qui per fare trading quantitativo, non per imparare a scrivere codice. Prova a utilizzare una soluzione più semplice.
Inoltre, se desideri costruire un market center, considerando le prestazioni, utilizzerai anche il database Redis e coopererai con la coda dei messaggi per comodità. La soluzione è semplice e adatta alla maggior parte degli scenari. È possibile utilizzare un server (o più server).
progettazione del codice
Fondamentalmente, quando si scrive codice, la struttura dei dati principali è la più importante. Il design della struttura dati non è sufficientemente ragionevole e il codice verrà scritto in modo scomodo, perché inevitabilmente causerà l'accoppiamento dei vari moduli, rendendo le modifiche molto problematiche. Ma per progettarlo correttamente è necessaria una certa esperienza di trading, cioè esperienza di business. Riguardano tutti come scrivere codice, non c'è molto da dire. Le strategie di ognuno sono diverse e non possono essere trattate allo stesso modo. Tuttavia, alcuni principi sono probabilmente gli stessi.
Ad esempio, dopo che un ordine è stato inviato, non vi è alcuna garanzia di successo, anche se si tratta di un ordine di mercato, perché potrebbe essere rifiutato dalla borsa. Ad esempio, lo scambio è troppo occupato o si verifica una perdita temporanea di pacchetti di dati di rete. Quindi, è meglio progettare alcuni stati intermedi simili a 2 Phase Commit. Se fallisce, continua a provare (ovviamente non troppo frequentemente, altrimenti verrà bannato se supera il limite. C'è uno speciale decoratore di tentativi per farlo). o aggiungere altro Un metodo per correggere lo stato di errore.
In circostanze normali, anche se lo scambio è in ribasso, si riprenderà in breve tempo. Se non ti ripristini, una delle parti sarà completamente inattiva, l'exchange o il tuo server di codice. Questo deve essere monitorato e allertato. È impossibile che il codice automatizzato copra tutto. Se non può essere elaborato automaticamente, verrà emesso un allarme. Se l’elaborazione manuale non viene gestita in tempo, finché non continuiamo ad aprire posizioni per aumentare l’esposizione, il problema non sarà troppo grande, perché ci sono ordini algoritmici di stop-loss per coprire il fondo.
Quella che segue è una logica di apertura della strategia che ho risolto io stesso:
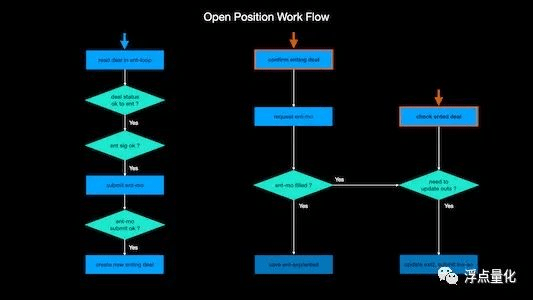
In sostanza, disegnando un diagramma di flusso simile, il codice sarà molto più organizzato e il numero di potenziali bug sarà ridotto. Pertanto, prima di scrivere il codice, è meglio disegnare un diagramma di flusso o risolverlo durante la scrittura, in modo che la logica sia chiara e tu abbia un'idea.
La logica di chiusura di una posizione è molto più complicata di così, perché ci sono più condizioni per chiudere una posizione, come stop-profit, stop-loss e segnali di uscita di varie strategie, che attiveranno la chiusura della posizione. Insomma, l’importanza dell’uscita è superiore a quella dell’ingresso, e anche l’offerta reale è un po’ più problematica.
Poiché la logica strategica di ognuno è decisamente diversa, non entrerò nei dettagli qui. La cosa principale è chiarire la tua logica strategica ed evitare che si verifichino vari possibili errori.
Tuttavia, questi sembrano complicati e sono solo un mucchio di if else (Python non ha nemmeno un'istruzione switch). Se le condizioni sono soddisfatte, procedi al passaggio successivo. In caso contrario, esci. Nessun grosso problema.
controllo del tempo
Quando si effettuano transazioni, il tempismo è senza dubbio molto importante. Qui condividerò alcune delle mie capacità di controllo del tempo.
Nella programmazione generale, se ci sono attività che devono essere eseguite regolarmente, vengono solitamente utilizzati pacchetti di lavori cron come apscheduler. Ad esempio, pianifica un'attività pianificata per rilevare se il prezzo della linea K deve aprire o chiudere una posizione non appena arriva l'ora.
Questo tipo di pacchetto in realtà apre un nuovo thread immediatamente all'ora impostata (può essere accurato fino al secondo livello) e quindi esegue l'attività specificata. Il problema è che se il tempo di esecuzione di questa attività è troppo lungo, verrà eseguita l'attività successiva ricomincerà. Ci saranno problemi, anche se possono essere risolti, ma sono più fastidiosi.
Di solito utilizzo tali attività pianificate quando ho bisogno di generare regolarmente informazioni di registro ed eseguire l'autocorrezione e l'autotest del programma, che sono funzioni a bassa frequenza che possono essere completate rapidamente. Queste funzioni leggono solo i dati nel database e non ci sono operazioni di scrittura o aggiornamento, quindi non fa male lasciare che apscheduler apra un altro thread per l'elaborazione.
Tuttavia, la logica che richiede interrogazioni costanti e frequenti sui prezzi di mercato o sullo stato delle politiche locali non è adatta per un tale pacchetto di tempistiche e deve essere controllata da un ciclo while.
Ad esempio, se la strategia utilizza segnali all'interno della barra della linea K, significa che il segnale può apparire in qualsiasi momento ed è necessario controllare costantemente il prezzo sottostante o il volume degli scambi per determinare se è necessario eseguire le operazioni corrispondenti. Se hai bisogno di un controllo temporale più preciso in questo momento, ad esempio, esegui la logica della serie di apertura di una posizione solo 10 secondi prima della fine dell'ora della linea k. Allora come puoi semplicemente giudicare se sono gli ultimi 10 secondi?
Ho preso il resto di 3600 utilizzando il timestamp.
(Se non si ha familiarità con il timestamp sul computer, ovvero il timestamp, inizia dal Greenwich Mean Time 1970.1.1. Ad esempio, è circa il 1691240298esimo secondo. Non vi è alcun problema se il computer è preciso rispetto al livello di microsecondi.)
Dopo aver preso il resto da 3600, se il resto è maggiore di 3590 secondi, saranno gli ultimi dieci secondi. L'errore può arrivare al livello del millisecondo. Come accennato in precedenza, è meglio che le principali operazioni di transazione vengano eseguite in sequenza in un thread. In questo modo, il tempo di esecuzione può essere controllato approssimativamente o il periodo di tempo può essere confuso, il che non sarà un problema.
Questo tipo di controllo richiede che l'impostazione dell'ora del proprio server non si discosti notevolmente dall'ora standard. Questo tipo di controllo però non sarà molto preciso, potrà arrivare solo al secondo livello. Tuttavia, Python non può controllare il tempo in modo molto preciso e queste funzioni di sospensione causeranno errori di circa microsecondi.
Ridurre la frequenza di accesso all'API
Se hai adottato un centro di mercato indipendente basato su websocket per condividere informazioni pubbliche di mercato come le linee K tra diverse strategie o anche diversi codici di trading, allora non c'è alcuna preoccupazione sui limiti di frequenza API a questo riguardo.
Ma dobbiamo anche ottenere tempestivamente le informazioni sul conto, ovvero tre tipi di informazioni: fondi, posizioni e ordini. Sebbene le informazioni sull'account possano anche utilizzare websocket e attendere che il server Exchange le invii attivamente, è più semplice utilizzare direttamente l'API rest per tre motivi.
Innanzitutto, al fine di ridurre il carico sulle informazioni dell'account inviate da websocket, l'exchange richiede di riconnettersi o aggiornare la listenKey di tanto in tanto (Binance dura 60 minuti). Questa situazione è ovviamente più difficile da mantenere. Anche se non è un grosso problema, se esegui l'hosting API e scambi più conti contemporaneamente, devi attivare un programma separato per garantire l'accuratezza in tempo reale delle informazioni e la logica diventa molto più complicata.
In secondo luogo, alcuni scambi non dispongono di push websocket per gli aggiornamenti delle informazioni sull'account. In questo caso, la logica di trading non è universale ed è più problematico cambiare codici di trading reali tra diversi scambi. Naturalmente, la maggior parte delle persone non effettuerà scambi su più borse e non incontrerà una situazione del genere.
In terzo luogo, se il collegamento websocket è interrotto o incontra problemi come l'aggiornamento o la scadenza di listenKey menzionati in precedenza, se il programma non lo rileva in tempo e sembra esserci una transazione in questo momento, se ti affidi solo a websocket, causerà un confronto. Grosso problema, perché le informazioni sull'aggiornamento dell'account mancato non verranno inviate nuovamente. Per evitare la possibilità di tali potenziali problemi, devi anche fare affidamento sulle rest API per ottenere determinate informazioni sull'account. Quindi alla fine devi fare affidamento sul resto dell'API, non è inutile?
In sintesi, per le transazioni a media e bassa frequenza, è meglio utilizzare direttamente rest API per ottenere informazioni sul conto. Per le origini dati importanti, è meglio seguire SSOT (Single Source Of Truth), altrimenti potrebbe causare potenziale confusione. Questo concetto può essere cercato su Google da solo ed è molto utile nella programmazione che si basa sull'elaborazione dei dati.
Quindi, se utilizzi solo l'API REST per ottenere informazioni sull'account, puoi mantenere una tabella temporanea delle informazioni sull'account nella memoria del codice locale, in particolare i fondi disponibili. Ciò può ridurre le visite frequenti allo scambio. La chiave è essere veloci e puoi inviare tutti gli ordini contemporaneamente. In modo simile all'effettuazione degli ordini in lotti e quindi all'elaborazione lenta della logica alla base dell'aggiornamento, più velocemente viene effettuato l'ordine, minore sarà naturalmente lo slittamento.
Inoltre, per determinare se l'ordine algoritmico stop loss è stato eseguito, è possibile utilizzare i recenti prezzi massimi e minimi invece di ottenere direttamente lo stato dell'ordine pendente, poiché per determinare se l'ordine è stato eseguito, è necessario eseguire il poll continuamente, il che è relativamente frequente e causerà molti accessi API non validi. L'aggiornamento del prezzo della linea K del websocket è molto tempestivo e non occupa il limite di frequenza API.
Allo stesso modo, anche alcuni ordini di uscita possono essere così. Se il tuo segnale di uscita si basa sul prezzo all'interno di una barra, potrebbe essere meglio utilizzare i prezzi massimi e minimi recenti. Poiché a volte il prezzo viene attivato e ritorna immediatamente, se la frequenza di controllo non è troppo alta, potresti perderlo. Per garantire coerenza nella tua strategia di trading, controlla i massimi e i minimi in modo da non perdere i prezzi. Questo approccio ha l’ulteriore vantaggio che il prezzo effettivo della transazione potrebbe essere più favorevole rispetto al prezzo limite reale.
Non so se i due punti precedenti siano facili da capire. Potrebbe richiedere qualche esperienza di vita reale.
Vorrei condividere parte della mia esperienza nello sviluppo di codice reale, sperando che possa essere utile a tutti.