

Punti principali
Binance sfrutta la gestione della capacità per i picchi di traffico non pianificati causati da un'elevata volatilità, garantendo infrastrutture e risorse informatiche adeguate e tempestive per le esigenze aziendali.
Test di carico di Binance nell'ambiente di produzione (piuttosto che in un ambiente di staging) per ottenere benchmark di servizio accurati. Questo metodo aiuta a verificare che la nostra allocazione delle risorse sia adeguata per servire un carico definito.
L’infrastruttura di Binance gestisce grandi quantità di traffico e il mantenimento di un servizio su cui gli utenti possono fare affidamento richiede un’adeguata gestione della capacità e test di carico automatici.

Perché Binance ha bisogno di un processo specializzato di gestione della capacità?
La gestione della capacità è un fondamento della stabilità del sistema. Implica il corretto dimensionamento delle risorse applicative e infrastrutturali con le esigenze aziendali attuali e future al costo corretto. Per contribuire a raggiungere questo obiettivo, creiamo strumenti e pipeline di gestione della capacità per evitare sovraccarichi e aiutare le aziende a fornire un'esperienza utente fluida.
I mercati delle criptovalute spesso affrontano periodi di volatilità più regolari rispetto ai mercati finanziari tradizionali. Ciò significa che il sistema di Binance deve sopportare di tanto in tanto questo aumento di traffico mentre gli utenti reagiscono ai movimenti del mercato. Con un'adeguata gestione della capacità, manteniamo la capacità adeguata alla domanda aziendale generale e a questi scenari di aumento del traffico. Questo punto chiave è esattamente ciò che rende i processi di gestione della capacità di Binance unici e stimolanti.
Vediamo i fattori che spesso ostacolano il processo e portano a un servizio lento o non disponibile. Innanzitutto abbiamo il sovraccarico, solitamente causato da un improvviso aumento del traffico. Ciò potrebbe derivare, ad esempio, da un evento di marketing, da una notifica push o persino da un attacco DDoS (Distributed Denial of Service).
Il traffico intenso e la capacità insufficiente influiscono sulla funzionalità del sistema in quanto:
Il servizio richiede sempre più lavoro.
Il tempo di risposta aumenta al punto che non è possibile rispondere a nessuna richiesta entro il timeout del client. Questo peggioramento si verifica in genere a causa della saturazione delle risorse (CPU, memoria, I/O, rete e così via) o di pause prolungate del GC nel servizio stesso o nelle sue dipendenze.
Il risultato è che il servizio non sarà in grado di elaborare le richieste tempestivamente.
Abbattere il processo
Ora che abbiamo discusso il principio generale della gestione della capacità, diamo un’occhiata a come Binance lo applica alla sua attività. Ecco uno sguardo all'architettura del nostro sistema di gestione della capacità con alcuni flussi di lavoro chiave.
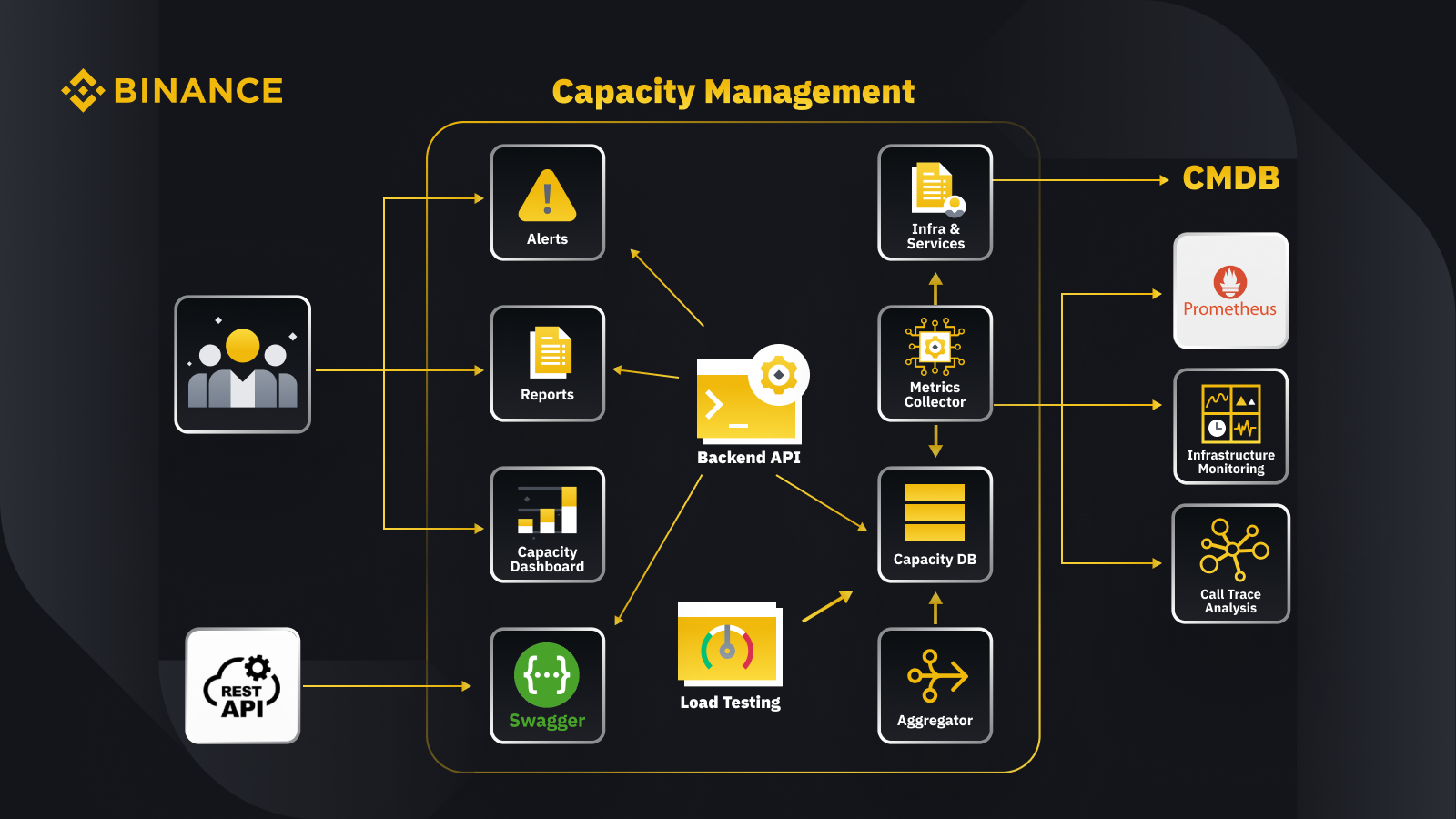
Recuperando i dati dal database di gestione della configurazione (CMDB), generiamo le configurazioni delle infrastrutture e dei servizi. Gli elementi in queste configurazioni sono gli oggetti di gestione della capacità.
Il raccoglitore di parametri recupera i parametri di capacità da Prometheus per i dati del livello aziendale e di servizio, il monitoraggio dell'infrastruttura per i parametri del livello delle risorse e il sistema di analisi della traccia delle chiamate per le informazioni sulla traccia. Il raccoglitore di parametri archivia i dati nel database delle capacità (CDB).
Il sistema di test di carico esegue stress test sui servizi e memorizza i dati di benchmark nel CDB.
L'aggregatore ottiene i dati sulla capacità da CDB e li aggrega per le dimensioni giornaliere e massime storiche (ATH). Dopo l'aggregazione, riscrive i dati aggregati nel CDB.
Elaborando i dati dal CDB, l'API di backend fornisce interfacce per il dashboard della capacità, gli avvisi e i report, nonché il resto dell'API e i relativi dati sulla capacità per l'integrazione.
Le parti interessate ottengono approfondimenti sulla capacità tramite il dashboard della capacità, gli avvisi e i report. Possono anche utilizzare altri sistemi correlati, incluso il monitoraggio dei dati sulla capacità dei servizi di acquisizione con l'API rest fornita dal sistema di gestione della capacità con Swagger.
Strategia
La nostra strategia di gestione e pianificazione della capacità si basa su un'elaborazione guidata dai picchi. L’elaborazione guidata dai picchi è il carico di lavoro sperimentato dalle risorse di un servizio (server Web, database, ecc.) durante i picchi di utilizzo.
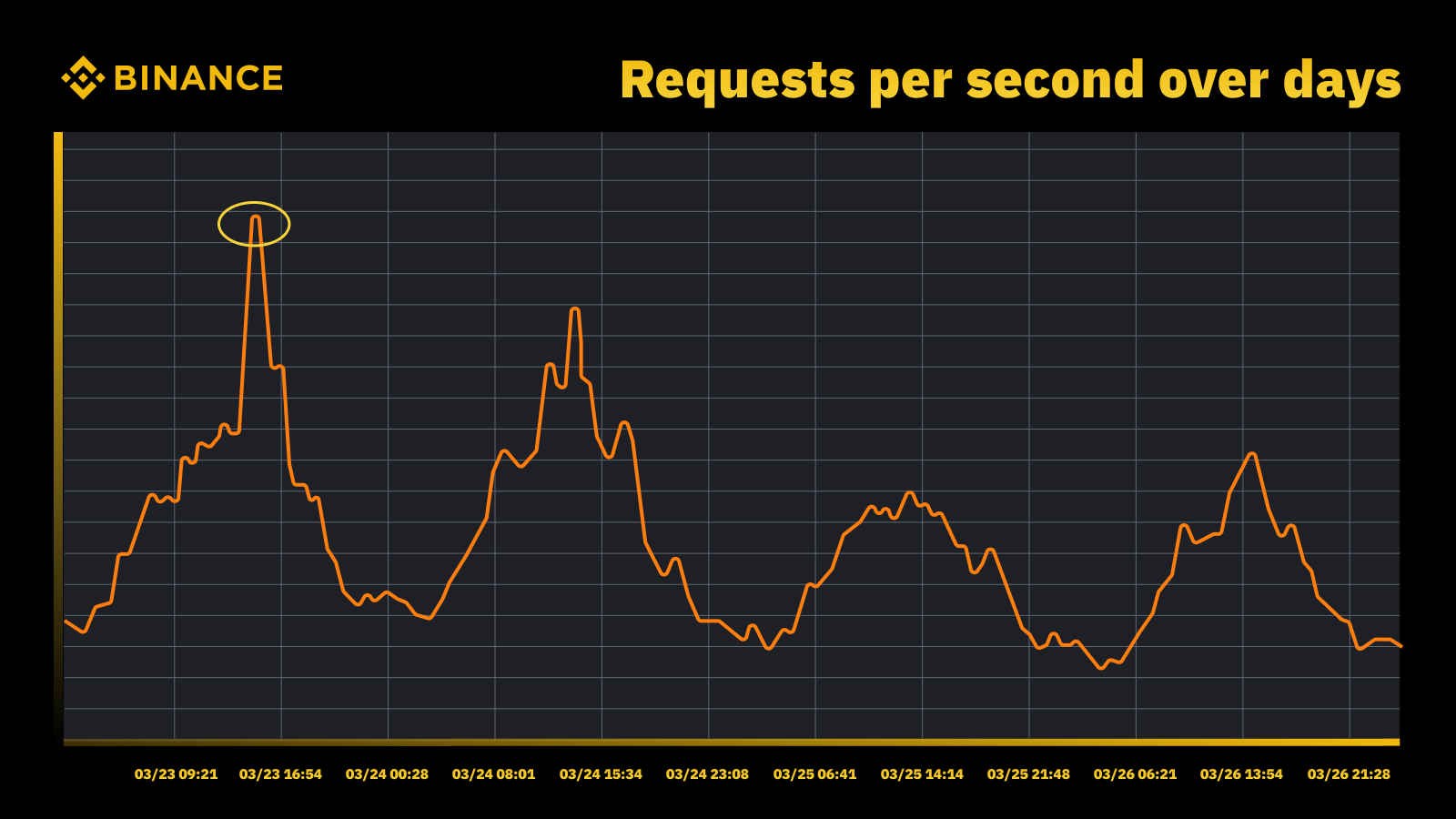
Aumento del traffico quando la Fed ha aumentato il tasso nel marzo 2023
Analizziamo i picchi periodici e li utilizziamo per guidare la traiettoria della capacità. Come con qualsiasi risorsa guidata dai picchi, vogliamo scoprire quando si verificano i picchi e quindi esplorare cosa sta realmente accadendo durante quei cicli.
Un'altra cosa importante che consideriamo insieme alla prevenzione del sovraccarico è la scalabilità automatica. La scalabilità automatica gestisce il sovraccarico aumentando dinamicamente la capacità con più istanze del servizio. Il traffico in eccesso viene quindi distribuito e il traffico gestito da una singola istanza del servizio (o dipendenza) rimane gestibile.
La scalabilità automatica ha la sua funzione, ma non è sufficiente a gestire da sola le situazioni di sovraccarico. Di solito non può reagire abbastanza velocemente a un improvviso aumento del traffico e funziona meglio solo quando si verifica un aumento graduale.
Misurazione
La misurazione gioca un ruolo cruciale nel lavoro di gestione della capacità di Binance e la raccolta dei dati è il nostro primo passo di misurazione. Sulla base degli standard ITIL (Information Technology Infrastructure Library), raccogliamo dati per la misurazione nei sottoprocessi di gestione della capacità, vale a dire:
Risorsa: consumo di risorse dell'infrastruttura IT guidato dall'utilizzo di applicazioni/servizi. Si concentra sulle metriche delle prestazioni interne delle risorse informatiche fisiche e virtuali, tra cui CPU del server, memoria, archiviazione su disco, larghezza di banda della rete, ecc.
Servizio. Le prestazioni a livello di applicazione, lo SLA, la latenza e le misure di throughput che derivano dalle attività aziendali. Si concentra su parametri di prestazione esterni basati su come gli utenti percepiscono il servizio, inclusi latenza del servizio, velocità effettiva, picchi, ecc.
Attività commerciale. Raccoglie dati che misurano le attività commerciali elaborate dall'applicazione di destinazione, inclusi ordini, registrazione dell'utente, pagamenti, ecc.
La gestione della capacità basata esclusivamente sull’utilizzo delle risorse infrastrutturali porterà a una pianificazione imprecisa. Questo perché potrebbe non rappresentare i volumi aziendali effettivi e il throughput che guidano la capacità della nostra infrastruttura.
Gli eventi in programma rappresentano un luogo eccellente per discuterne ulteriormente. Partecipa al Watch Web Summit 2022 su Binance Live per condividere fino a 15.000 BUSD nella campagna Crypto Box Rewards. Oltre alle metriche sottostanti relative alle risorse e al livello di servizio, dovevamo considerare anche i volumi di business. In questo caso abbiamo basato la pianificazione della capacità su parametri aziendali come il numero stimato di spettatori in live streaming, il numero massimo di richieste in volo per una Crypto Box, la latenza end-to-end e altri fattori.
Dopo aver raccolto i dati, i nostri processi di gestione della capacità aggregano e riepilogano i numerosi punti dati raccolti rispetto a uno specifico driver di capacità. Il valore aggregato di una metrica è un valore singolo che può essere utilizzato negli avvisi sulla capacità, nei report e in altre funzioni relative alla capacità.
Possiamo applicare diversi metodi di aggregazione dei dati a punti dati periodici, come somma, media, mediana, minimo, massimo, percentile e massimo storico (ATH).

Il metodo scelto determina i nostri risultati dal processo di gestione della capacità e dalle decisioni conseguenti. Selezioniamo diversi metodi in base a diversi scenari. Ad esempio, utilizziamo il metodo massimo per i servizi critici e i relativi punti dati. Per registrare il traffico più elevato, utilizziamo il metodo ATH.
Per diversi casi d'uso, utilizziamo diversi tipi di granularità per l'aggregazione dei dati. Nella maggior parte dei casi, utilizziamo minuti, ore, giorni o ATH.
Con una granularità minima, misuriamo il carico di lavoro di un servizio per avvisi tempestivi di sovraccarico.
Utilizziamo dati orari aggregati per creare dati giornalieri e aggreghiamo i dati orari per registrare il picco giornaliero.
In genere utilizziamo i dati giornalieri per i report sulla capacità e sfruttiamo i dati ATH per la modellazione e la pianificazione della capacità.
Uno dei parametri fondamentali della gestione della capacità è il benchmarking dei servizi. Questo ci aiuta a misurare con precisione le prestazioni e la capacità del servizio. Otteniamo il benchmark del servizio con il test di carico e approfondiremo l'argomento in modo più dettagliato in seguito.
Gestione della capacità in base alla priorità
Finora abbiamo visto come raccogliamo parametri di capacità e aggreghiamo i dati con diversi tipi di granularità. Un’altra area critica da discutere è la priorità, che è utile nel contesto dei rapporti sugli allarmi e sulla capacità. Dopo aver classificato le risorse IT, viene data la priorità all'utilizzo limitato dell'infrastruttura e delle risorse informatiche e assegnati per primi ai servizi e alle attività critici.
Possono esserci diversi modi per definire il servizio e richiedere la criticità. Un riferimento utile è Google. Nel libro SRE. Definiscono i livelli di criticità come CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS ecc. Allo stesso modo, definiamo più livelli di priorità come P0, P1, P2 e così via.
Definiamo i livelli di priorità come segue:
P0: per i servizi e le richieste più critici, quelli che in caso di fallimento comporteranno un impatto grave e visibile all'utente.
P1: per quei servizi e richieste che comporteranno un impatto visibile all'utente, ma l'impatto è inferiore a quelli di P0. Si prevede che i servizi P0 e P1 disporranno di una capacità sufficiente.
P2: questa è la priorità predefinita per i lavori batch e i lavori offline. Questi servizi e richieste potrebbero non avere un impatto visibile all'utente se sono parzialmente non disponibili.
Cos'è il test di carico e perché lo utilizziamo in un ambiente di produzione?
Il test di carico è un processo di test del software non funzionale in cui le prestazioni di un'applicazione vengono testate in base a un carico di lavoro specifico. Ciò aiuta a determinare il comportamento dell'applicazione durante l'accesso simultaneo da parte di più utenti finali.
In Binance, abbiamo creato una soluzione che ci consente di eseguire test di carico in produzione. In genere, i test di carico vengono eseguiti in un ambiente di staging, ma non abbiamo potuto utilizzare questa opzione in base ai nostri obiettivi generali di gestione della capacità. I test di carico in un ambiente di produzione ci hanno permesso di:
Raccogli un benchmark accurato dei nostri servizi in condizioni di carico reali.
Aumentare la fiducia nel sistema, nella sua affidabilità e prestazioni.
Identificare i colli di bottiglia nel sistema prima che si verifichino nell'ambiente di produzione.
Abilita il monitoraggio continuo degli ambienti di produzione.
Abilita la gestione proattiva della capacità con cicli di test normalizzati che si verificano regolarmente.
Di seguito puoi vedere il nostro framework di test di carico con alcuni suggerimenti chiave:

Il framework dei microservizi di Binance ha un livello base per supportare il routing del traffico basato su configurazione e flag, che è essenziale per il nostro approccio TIP.
Viene adottata l'analisi canary automatizzata (ACA) per valutare l'istanza che stiamo testando. Confronta i parametri chiave raccolti nel sistema di monitoraggio, in modo da poter mettere in pausa/terminare il test se si verifica un problema imprevisto per ridurre al minimo l'impatto sull'utente.
Benchmark e metriche vengono raccolti durante i test di carico per generare informazioni dettagliate sui comportamenti e sulle prestazioni delle applicazioni.
Le API sono esposte per condividere preziosi dati sulle prestazioni in vari scenari, ad esempio, gestione della capacità e garanzia della qualità. Ciò aiuta a costruire un ecosistema aperto.
Creiamo flussi di lavoro di automazione per orchestrare tutti i passaggi e i punti di controllo da una prospettiva di test end-to-end. Forniamo inoltre la flessibilità di integrazione con altri sistemi, come la pipeline CI/CD e il portale operativo.
Il nostro approccio Testing in Production (TIP).
Un approccio tradizionale al test delle prestazioni (esecuzione di test in un ambiente di staging con traffico simulato o con mirroring) offre alcuni vantaggi. Tuttavia, l'implementazione di un ambiente di staging di tipo produttivo presenta più inconvenienti nel nostro contesto:
Quasi raddoppia i costi dell’infrastruttura e gli sforzi di manutenzione.
È incredibilmente complesso ottenere il funzionamento end-to-end della produzione, soprattutto in un ambiente di microservizi su larga scala su più unità aziendali.
Aggiunge ulteriori rischi per la privacy e la sicurezza dei dati poiché, inevitabilmente, potrebbe essere necessario duplicare i dati nello staging.
Il traffico simulato non replicherà mai ciò che realmente accade in produzione. Il benchmark ottenuto nell'ambiente di staging sarebbe impreciso e avrebbe meno valore
Il test in produzione, noto anche come TIP, è una metodologia di test con spostamento a destra in cui il nuovo codice, le funzionalità e le versioni vengono testati nell'ambiente di produzione. Il test di carico in produzione che abbiamo adottato è estremamente vantaggioso perché ci aiuta a:
Analizzare la stabilità e la robustezza del sistema.
Scopri benchmark e colli di bottiglia delle applicazioni con diversi livelli di traffico, specifiche del server e parametri dell'applicazione.
Routing basato su FlowFlag
Il nostro routing basato su FlowFlag integrato nel framework di base dei microservizi è la base per rendere possibile TIP. Ciò è vero per casi specifici, comprese le applicazioni che utilizzano il rilevamento del servizio Eureka per la distribuzione del traffico.
Come illustrato nel diagramma, il server web Binance come punti di ingresso etichetta una percentuale del traffico come specificato nelle configurazioni con intestazioni FlowFlag, durante il test di carico, possiamo selezionare un host di un servizio specifico e contrassegnarlo come istanza perf di destinazione nel configs, le richieste etichettate perf verranno infine instradate all'istanza perf quando raggiungono il servizio per l'elaborazione.
È completamente basato sulla configurazione e con il caricamento a caldo, possiamo facilmente regolare la percentuale del carico di lavoro utilizzando l'automazione senza dover distribuire una nuova versione
Può essere ampiamente applicato alla maggior parte dei nostri servizi, poiché il meccanismo fa parte del gateway e del pacchetto base
Un singolo punto di cambiamento significa anche un facile rollback per ridurre i rischi nella produzione

Mentre trasformiamo la nostra soluzione per renderla più nativa del cloud, stiamo anche esplorando come creare un approccio simile per supportare altri instradamenti del traffico offerti dai provider di cloud pubblici o Kubernetes.
Analisi canary automatizzata per ridurre al minimo i rischi di impatto sull'utente
La distribuzione Canary è una strategia di distribuzione volta a ridurre il rischio di distribuire una nuova versione del software in produzione. In genere comporta la distribuzione di una nuova versione del software, denominata release canary, a un piccolo sottoinsieme di utenti insieme alla versione stabile in esecuzione. Quindi dividiamo il traffico tra le due versioni in modo che una parte delle richieste in entrata venga deviata al canary.
La qualità della versione canarino viene quindi valutata mediante la cosiddetta analisi canarino. Questo confronta le metriche chiave che descrivono il comportamento della vecchia e della nuova versione. Se si verifica un peggioramento significativo delle metriche, il canary viene interrotto e tutto il traffico viene instradato alla versione stabile per ridurre al minimo l'impatto di comportamenti imprevisti.
Utilizziamo lo stesso concetto per creare la nostra soluzione di test di carico automatico. La soluzione utilizza la piattaforma Kayenta per l'analisi canary automatizzata (ACA) tramite Spinnaker per consentire implementazioni canary automatizzate. Il nostro tipico flusso di test di carico quando si segue questo metodo appare così:
Attraverso il flusso di lavoro, aggiungiamo in modo incrementale il carico di traffico (ad esempio, 5%, 10%, 25%, 50%) all'host di destinazione come specificato o finché non raggiunge il punto di rottura.
Sotto ogni carico, l'analisi canary viene eseguita ripetutamente con Kayenta per un certo periodo di tempo (ad esempio, 5 minuti) per confrontare i parametri chiave dell'host testato con il periodo di pre-caricamento come riferimento e l'attuale periodo di post-caricamento come esperimento.
Il confronto (modello di configurazione canary) si concentra sul controllo se l'host di destinazione:
Raggiunge i limiti delle risorse, ad esempio l'utilizzo della CPU supera il 90%.
Presenta un aumento significativo delle metriche di errore, ad esempio log degli errori, eccezioni HTTP o rifiuti del limite di velocità.
Le metriche dell'applicazione principale sono ancora ragionevoli, ad esempio una latenza HTTP inferiore a 2 secondi (personalizzabile per ciascun servizio)
Per ogni analisi, Kayenta ci fornisce un report per indicare il risultato e il test termina immediatamente in caso di fallimento.
Il rilevamento degli errori richiede solitamente meno di 30 secondi, riducendo significativamente la possibilità di influire sull'esperienza dei nostri utenti finali.

Abilitazione di Data Insights
È fondamentale raccogliere informazioni sufficienti su tutti i processi e le esecuzioni dei test descritti in precedenza. L’obiettivo finale è migliorare l’affidabilità e la robustezza del nostro sistema, cosa impossibile senza l’analisi dei dati.
Un riepilogo complessivo del test cattura la percentuale di carico massimo che l'host è stato in grado di gestire, il picco di utilizzo della CPU e il QPS dell'host. Sulla base di ciò, stima anche il numero di istanze che potremmo dover implementare per soddisfare la nostra prenotazione di capacità, considerando il QPS più elevato di tutti i tempi dei servizi.
Altre informazioni preziose per l'analisi includono la versione del software, le specifiche del server, il conteggio delle distribuzioni e un collegamento al dashboard del monitor in cui possiamo rivedere cosa è successo durante il test.

Una curva di riferimento indica come sono cambiate le prestazioni negli ultimi tre mesi in modo da poter scoprire eventuali problemi relativi a una specifica versione dell'applicazione.

Le tendenze di CPU e QPS mostrano come l'utilizzo della CPU sia correlato al volume di richieste che il server ha dovuto gestire. Questa metrica può aiutare a stimare i margini del server per la crescita del traffico in entrata.
Il comportamento della latenza dell'API rileva la variazione del tempo di risposta in diverse condizioni di carico per le cinque API principali. Possiamo quindi ottimizzare il sistema, se necessario, a livello di API individuale.

Le metriche di distribuzione del carico API ci aiutano a capire in che modo la composizione dell'API influisce sulle prestazioni del servizio e forniscono maggiori informazioni sulle aree di miglioramento.
Normalizzazione e productizzazione
Man mano che il nostro sistema continua a crescere ed evolversi, continueremo a monitorare e migliorare la stabilità e l'affidabilità del servizio. Continueremo attraverso:
Un programma di test di carico regolare e stabilito per i servizi critici.
Test di carico automatici come parte delle nostre pipeline CI/CD.
Maggiore produttività dell'intera soluzione per prepararsi all'adozione su larga scala in tutta l'organizzazione.
Limitazioni
Esistono alcune limitazioni all'attuale approccio del test di carico:
Il routing basato su FlowFlag è applicabile solo al nostro framework di microservizi. Stiamo cercando di espandere la soluzione a più scenari di routing sfruttando la funzionalità di routing ponderato comune dei bilanciatori del carico cloud o di Kubernetes Ingress.
Poiché basiamo il test sul traffico utente reale in produzione, non possiamo eseguire test delle funzionalità rispetto ad API o casi d'uso specifici. Inoltre, per i servizi con volume molto basso, il valore sarebbe limitato poiché potremmo non essere in grado di identificarne il collo di bottiglia.
Eseguiamo questi test sui singoli servizi anziché coprire le catene di chiamate end-to-end.
I test in produzione a volte possono avere un impatto sugli utenti reali se si verificano errori. Pertanto dobbiamo disporre di analisi dei guasti e rollback automatico con funzionalità di automazione complete.
Pensieri conclusivi
Per noi è fondamentale pensare agli scenari di aumento del traffico per prevenire il sovraccarico del sistema e garantirne il tempo di attività. Ecco perché abbiamo creato i processi di gestione della capacità e di test del carico descritti in questo articolo. Riassumere:
La nostra gestione della capacità è guidata dai picchi e integrata in ogni fase del ciclo di vita del servizio, prevenendo il sovraccarico con attività come misurazioni, impostazione di priorità, avvisi e report sulla capacità, ecc. Questo è in definitiva ciò che rende i processi e le esigenze di Binance unici rispetto a una tipica situazione di gestione della capacità .
Il benchmark del servizio ottenuto dai test di carico è il punto focale della gestione e pianificazione della capacità. Determina con precisione le risorse infrastrutturali necessarie per supportare le esigenze aziendali attuali e future. Alla fine, questo ha dovuto essere eseguito in produzione con una soluzione unica, creata da Binance, che ci ha permesso di soddisfare le nostre esigenze specifiche.
Mettendo insieme tutto questo, speriamo che tu possa vedere che una buona pianificazione e strutture approfondite aiutano a creare il servizio che i Binanciani conoscono e apprezzano.
Riferimenti
Dominic Ogbonna, Gestione della capacità dalla A alla Z: guida pratica per l'implementazione del monitoraggio e della pianificazione della capacità dell'IT aziendale, capitolo 4, capitolo 6
Luis Quesada Torres, Doug Colish, Migliori pratiche SRE per la gestione della capacità
Alejandro Forero Cuervo, Sarah Chavis, libro Google SRE, capitolo 21 - Gestione del sovraccarico
Ulteriori letture
(Blog) Come Binance Ledger potenzia la tua esperienza su Binance
(Blog) Presentazione di Binance Oracle VRF: la prossima generazione di casualità verificabile
(Blog) Binance si unisce all'Alleanza FIDO in preparazione all'implementazione di Passkey