When the decentralized storage projects discuss adoption, they usually refer to pilots, proof of concept, or a small dataset, which does not substantially stress the system. Chainbase integration with Walrus is special since it is operated in a category that is quite different. It is not of holding on the shelf some dead artifact or long-tail archival data. It concerns managing hundreds of terabytes of raw and constantly increasing blockchain data and rendering that data useful to the downstream systems that require it to be right, available, and accessible again.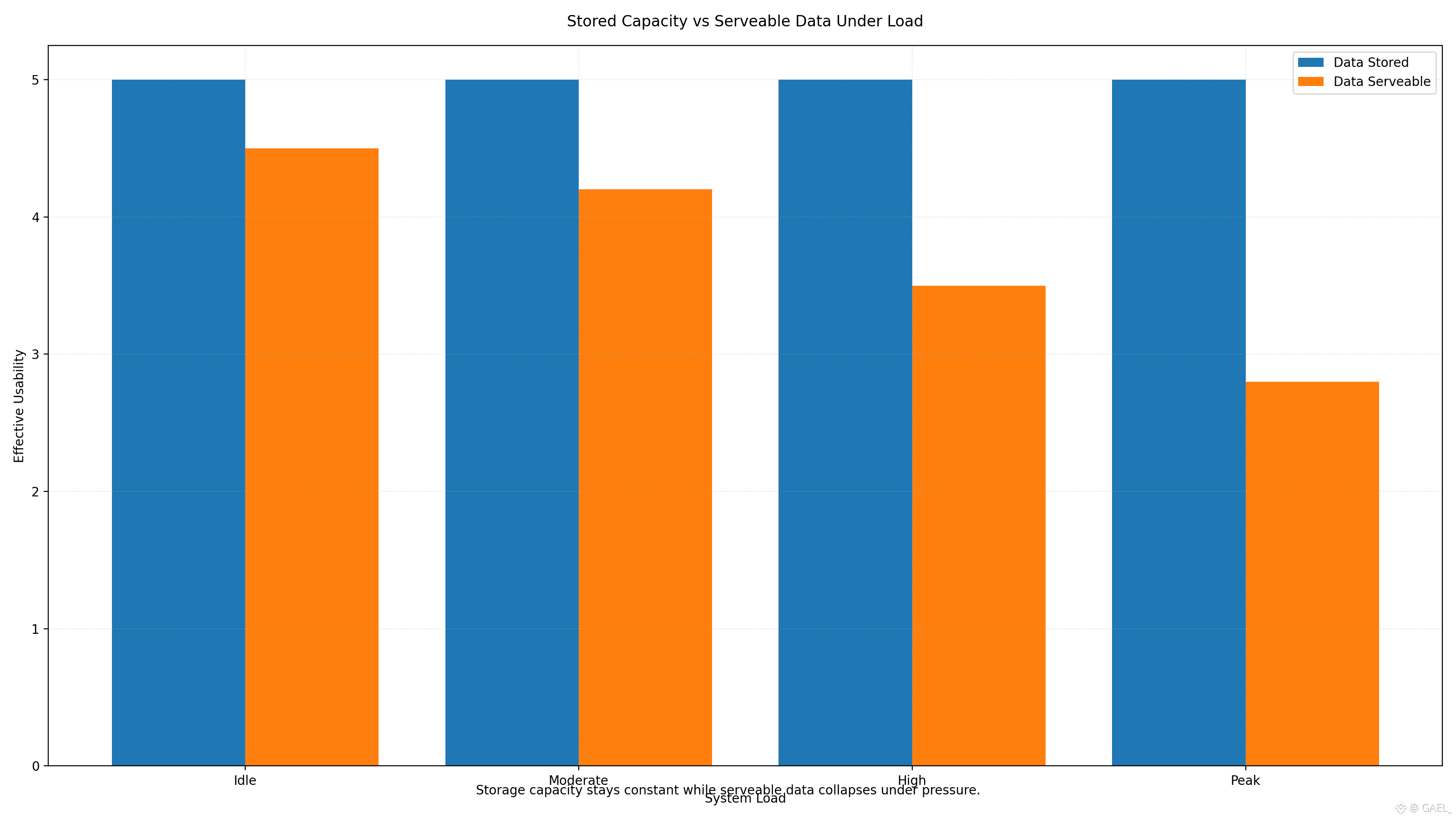
Chainbase is an omnichain data network, which assembles raw data on over two hundred blockchains and makes it available to developers, analysts, and applications that need structured and queryable access. It is significant to the size of this operation. Information is not remembered and lost at this stage. It is loaded with repeated reading, recalculation and cross-referencing. Any defect in availability or serving behaviour is soon an operational bottleneck. The integration with Walrus is a decision that was made in light of the fact that the normal storage assumptions are inapplicable to such workload.
It is not mere decentralized persistence which Walrus brings to this integration. It introduces a data layer that is constructed with a focus on serving pressure, rather than retention. The raw data at Chainbase are big, unstructured and ever-expanding. They have to be available to a large number of independent consumers simultaneously usually at the peak time of the demand. The data is not present everywhere so that a guarantee of finding the data exists in such environments. The point is that the layer of data must be able to service that data without intermediaries that are trusted or centralized choke points.
This integration brings to focus one of the fundamental design decisions that Walrus makes: to make data availability an explicit protocol concern, and not an accidental side-effect. In the case of a system such as Chainbase, this is important, since failures to maintain a system in terms of availability do not usually manifest themselves as complete failures. They appear as latency spikes, partial access or requisite of privileged infrastructure to iron over retrieval instead. In the long run, such workarounds compromise decentralization and transparency of operations. The model proposed by Walrus which focuses on verifiable availability and serving behavior that is economically aligned is more appropriate in an environment where data is actively read as opposed to passively stored.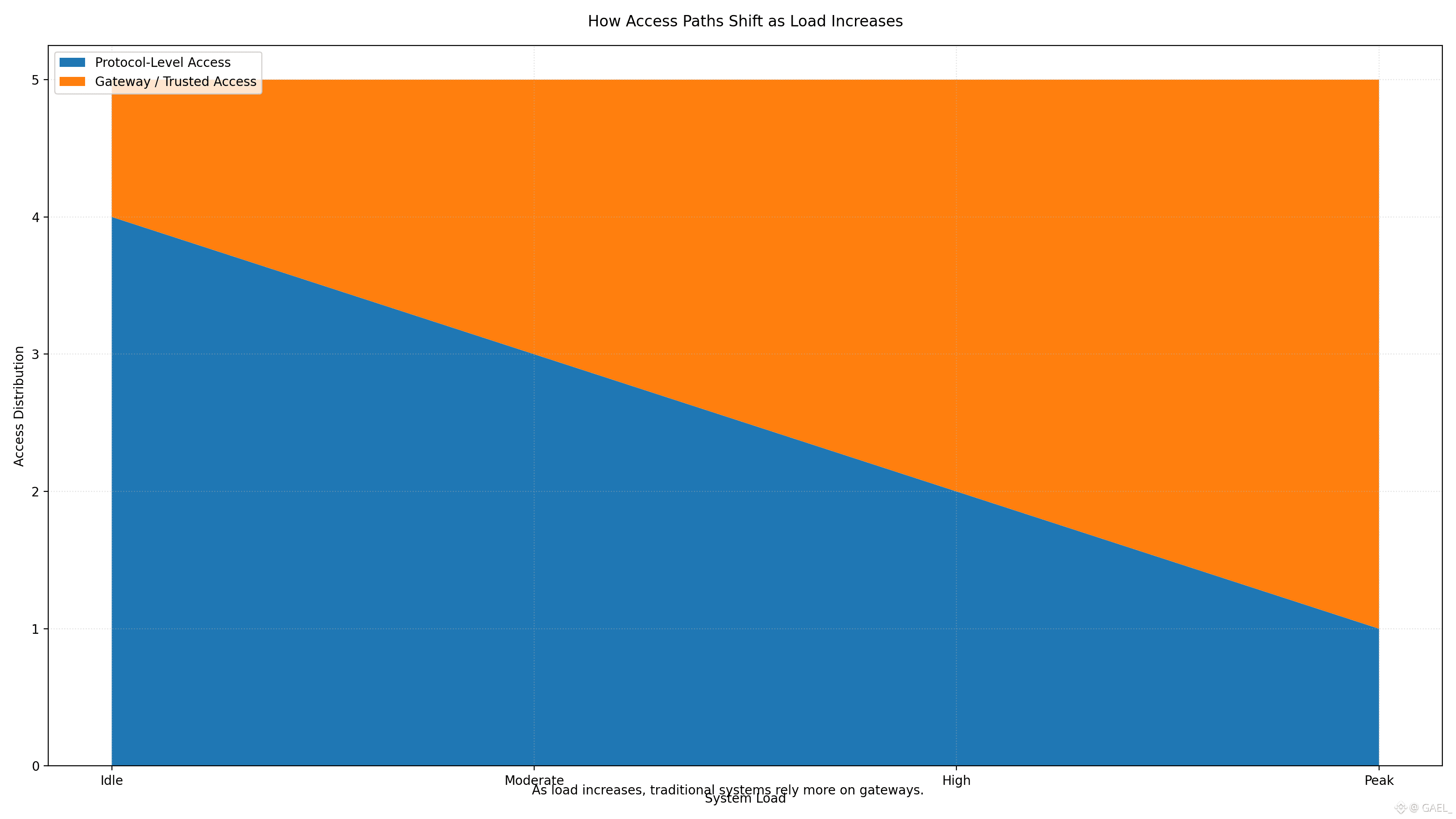
The other relevant factor of this integration is the type of data involved. Chainbase does not work with application-specific and curated blobs. It is working with raw blockchain data that drives analytics, indexing and higher level abstractions. At the storage layer, any error, gap or inconsistency will spread upwards and magnify. Using Walrus as the anchor of this data, Chainbase has a storage substrate which is constructed to ensure availability can be observed and enforced, without depending on off-protocol guarantees.
In the view of Walrus, Chainbase integration is important since it will test the protocol in a hard-production-focused environment. Weaknesses that are obscured by smaller use cases are revealed by big-data workloads. They do not just test capacity, but also coordination, incentive congruence and the capacity to serve data at sustained load. To support a dataset of hundreds of terabytes on dozens of blockchains indicates Walrus is not a test storage layer, it is infrastructure which can be adopted to support data pipelines of critical significance.
The larger conclusion is that decentralized data infrastructure starts to leave the limited number of single-use cases. With the increasing externalization of data through more systems and reliance on common datasets, storage data capability ceases to be the point of difference. The distinguishing factor is the ability to access such data many times, verifiably, and without central points of control. Combos such as this indicate that Walrus is setting up to occur that future, in which data layers will be evaluated based on their suitability in supporting actual workloads as opposed to raw storage metrics.
In the case of the Web3 ecosystem, this integration is also an indicator of a merger between blockchain analytics and indexing and decentralized storage. Data networks such as Chainbase are at the intersection of these areas. There is a pressure on storage protocols to meet real operational limits imposed by their needs. The use of these constraints demonstrates that Walrus resorts to working with them instead of abstracting them out.
That way the Chainbase integration is not as much an individual partnership, but rather an indicator. It indicates that entity["organization,"Walrus,"decentralized data availability protocol] is being adopted in which data is not only valuable, but mission-critical, and in which load-based availability is non-negotiable. Simultaneously, it shows entity[ organization, Chainbase, blockchain data network] and identifies that decentralized storage should not be possible, as passive persistence, but rather needs to be transformed to accommodate the next generation of data-driven applications.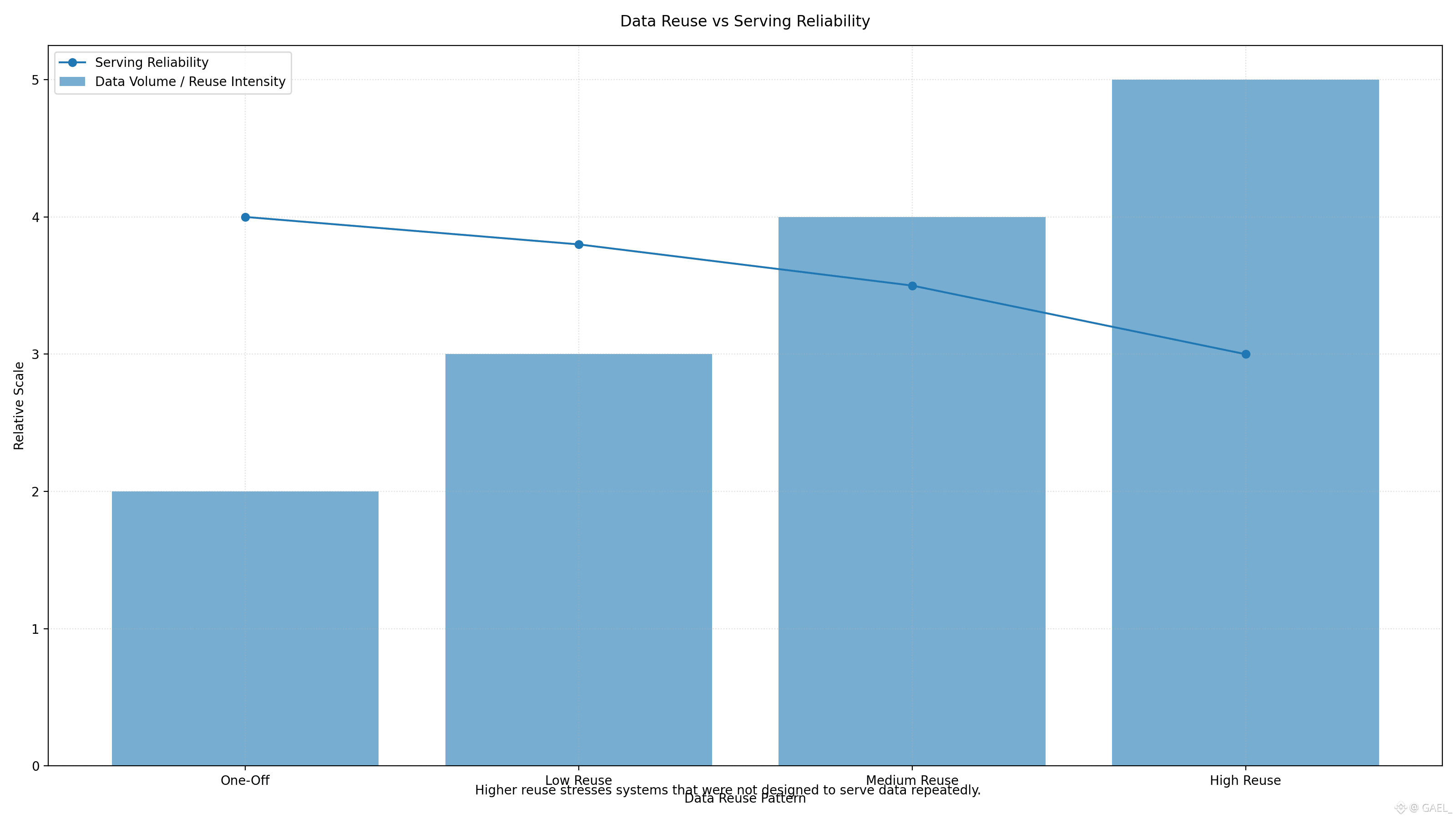
Integrations such as this one will perhaps become even more frequent as Web3 keeps generating data at an accelerating rate. It will not be a matter of whether or not decentralized storage can store the data, but whether it can be a good foundation to systems that have to rely on the data on a daily basis. According to the Walrus-Chainbase conglomeration, this shift is already being followed.

