
It was around 2:17 AM when I stopped looking at price candles and started watching the infrastructure underneath them. BTC was moving sideways again and market crashng hardly liquidity felt thin, and most traders on my feed were already jumping toward the next AI narrative rotation. Same cycle. Same excitment. Same exhaustion after two days.
But something felt different this time.
At that tim I had three screens open. One tracking mempool activity, another showing GPU rental spreads, and the third following a smaller decentralized AI subnet that suddenly started seeing bursts of fragmented inference requests. Not huge volume. Just strange behavior. The kind that makes you pause for a second and zoom in.
On that time at first I honestly thought it was noise.
Then I kept seeing lightweight adapter deployments getting triggered in short intervals instead of one large persistnt environment staying online. One wallet, something ending in 0x7e… kept rotating through multiple interactions almost too cleanly. No dramatic whale movement. No obvious farming behavior. Just repeated modular activity that looked intentional.
That’s when OpenLoRA really got my attention.
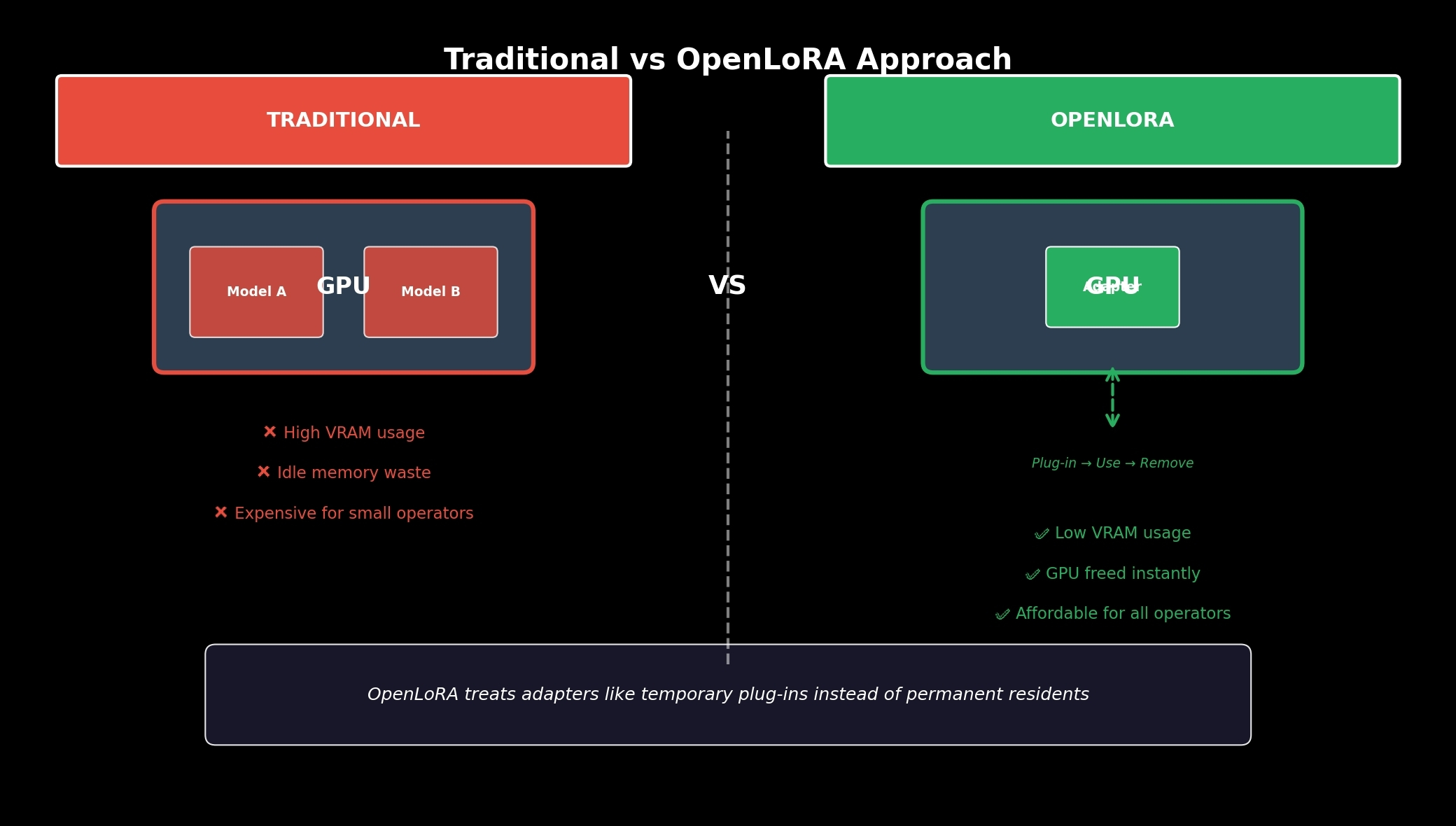
From what I’m seeing lately, decentralized AI systems are quietly running into hardware pressure most people still ignore. A lot of networks were built with the assumption that GPUs could permanently hold massive customized models in VRAM all day without consequences. In reality, smaller operators are getting squeezed hard. Expensive memory sits occupied while actual compute efficiency drops underneath.
OpenLoRA approaches the problem differently yeah
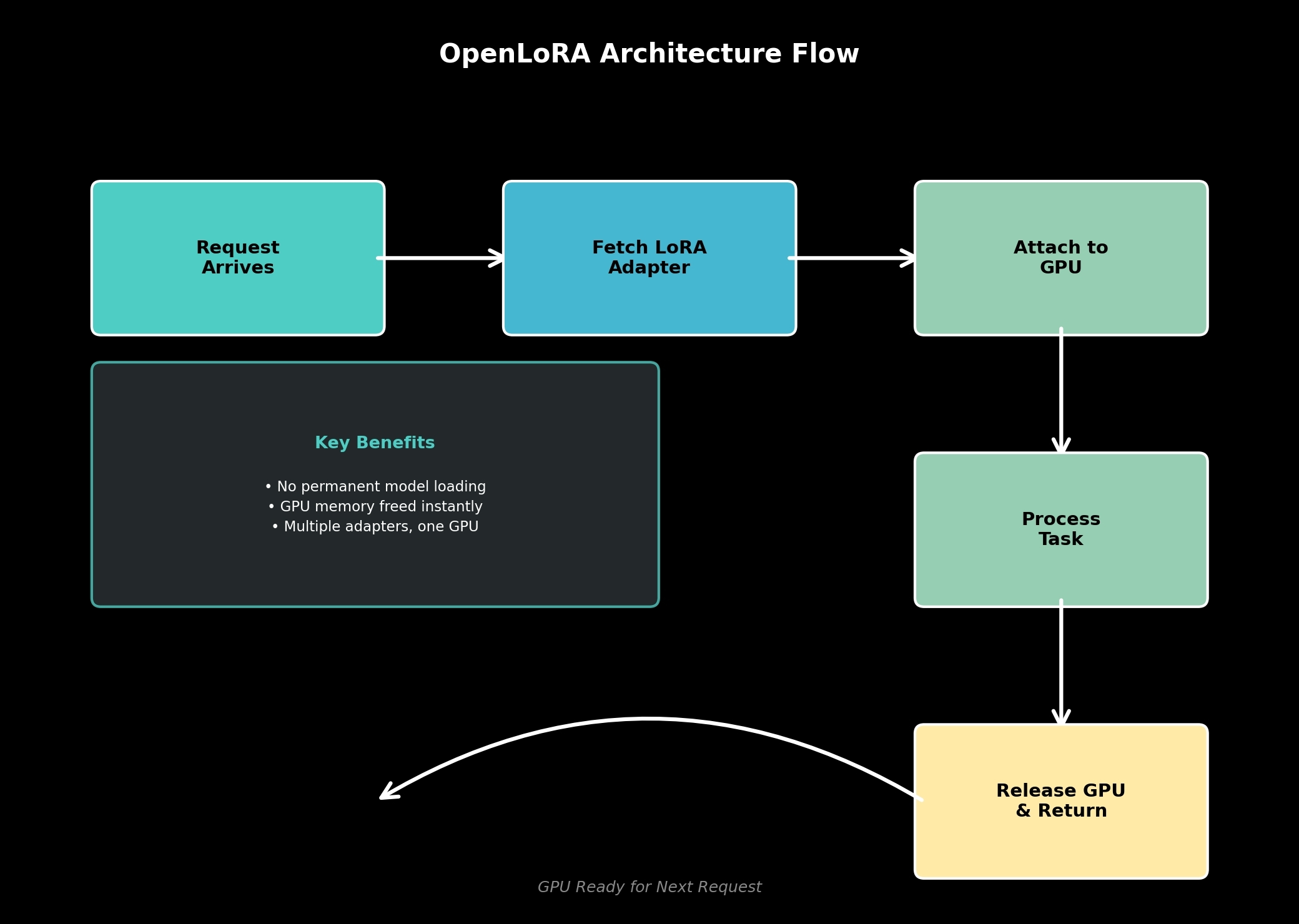
Instead of keeping every model loaded nonstop, it treats LoRA adapters more like temporary plug-ins. A request comes in, the adapter gets pulled from storage, attaches briefly to the inference layer, handlles the task, then disappears again. The GPU becomes reusable immediately instead of staying locked by idle memory weight.
Simple idea honestly. But structurally it changes a lot.
I have been noticing more blockchain AI systems drifting toward modular infrastructure recently because the economics are becoming impossible to ignore. GPU markets tightened again this month. Smaller operators ar struggling to stay profitable while larger infrastructure players absorb more demand. Some subnets I watched last week were already rotating workloads manually during traffic spikes because memory ceilings were becoming a real bottleneck.
That pressure matters.
Most decentralized AI applications don’t actually need one giant universal model running permanently. Autonomous agents, trading tools, monitoring systems, gaming behaviors they need specific capabilities at specific moments. OpenLoRA feels built around that reality instead of pretending infinite hardware exists underneath the network.
I still hesitated while digging through the architecture though.
Dynamic adapter swapping sounds clean until you imagine thousands of simultaneous requests slamming GPU memory at once. I remember sitting there watching latency traces wondering whether constant loading and unloading would eventually create fragmentation issues severe enough to destabilize nodes durng real network stress. That doubt stayed with me longer than I expected.
The backend optimizations are clearly trying to reduce that risk. Flash Attention, tensor parallelism, paged memory systems all of it seems focused on maintaining efficiency while adapters switch rapidly between requests. From what I can tell, the objective isn’t maximum raw speed. It’s stability during unpredictable decentralized traffic conditions.
That difference matters more than people think.
Compared to older decentralized AI frameworks, OpenLoRA feels lighter. Some competing systems still resemble traditional cloud infrastructure wrapped in blockchain branding. Heavy persistent deployments. Constant idle memory burn. Expensive hardware assumptions that slowly push smaller operators out of the ecosystem over time.
OpenLoRA feels closer to liquidity routing than infrastructure locking. Compute floows where demand appears.
The governance side still makes me uneasy though. If adapters are dynamically retrieved from external repositories, trust becomes fragmented fast. Who validates those weights before deployment? Who decides what’s safe enough to load into live inference environments? In permissionless ecosystems, malicious adapters could spread before detection systems even react properly.
The honest part I keep returning to is that decentralized infrastructure usually moves faster than security review.
That tension never really disappears.
What’s interesting is the growth signals don’t even look flashy yet. I’m not seeing massive retail hype or explosive attention cycles. I’m seeing quieter things instead. More fragmented inference behavior. More experimentation from smaller builders. Gas spikes around decentralized compute coordination layers during overlapping workload windows. Activity that feels operational rather than speculative.
And honestly, I think most people are missing the deeper shift happening underneath.
This might not just be about compute efficiency. It could be about ownership pressure inside decentralized AI systems. If smaller operators can remain competitive without absurd VRAM requirements, networks become structurally harder to centralize around a few dominant GPU holders.
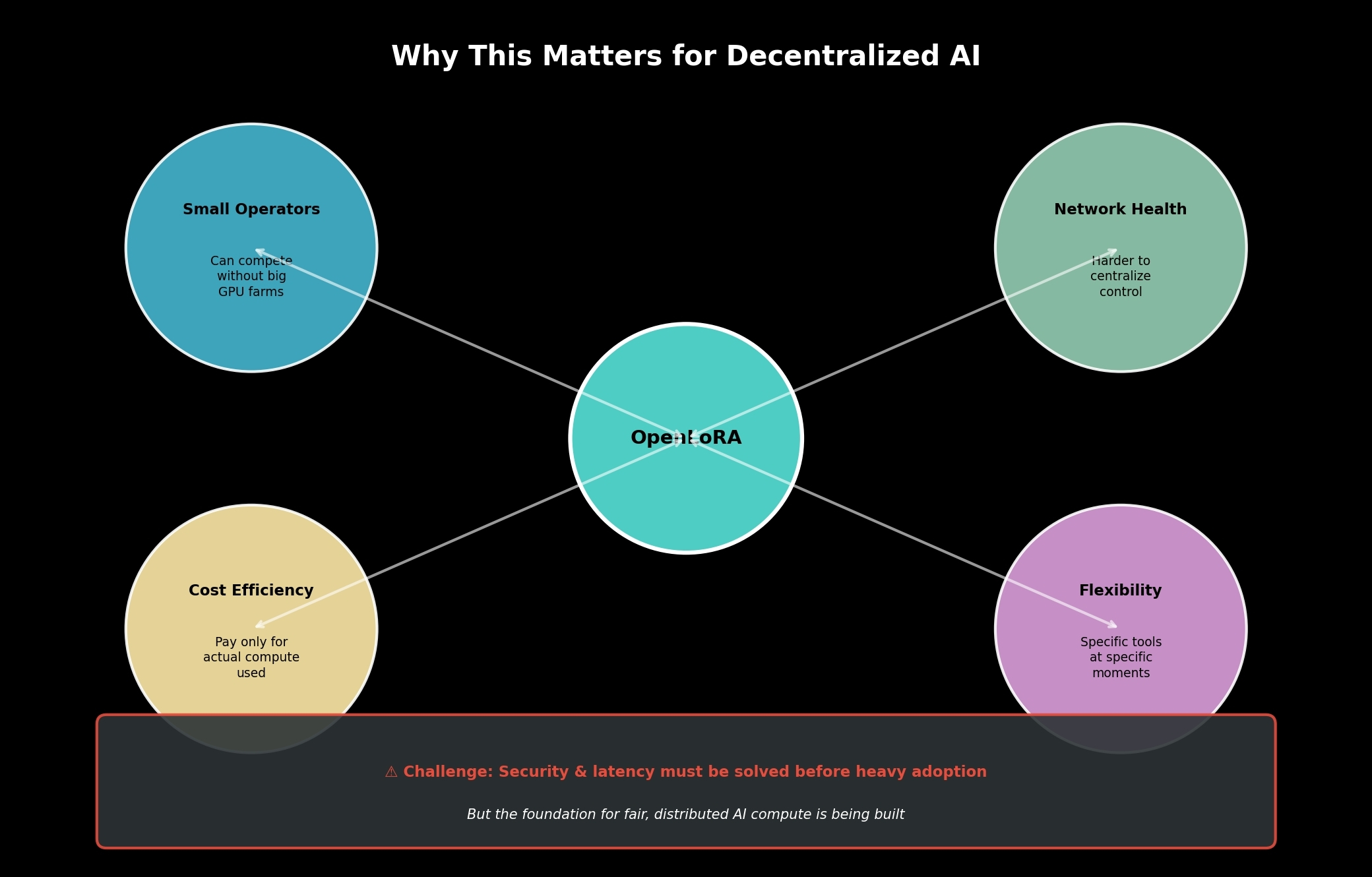
But if latency problems, security failures, or scaling instability start appearing consistently under heavier demand, the model could struggle once real adoption arrives.
Right now I don’t see certainty. I see infrastructure stress colliding with market incentives in real time.
And I keep wondering whether builders are finally creating sustainable decentralized AI systems now… or whether the market is stil temporarily renting another narrative before the next rotation starts again.

