
Il GPT-4 ha ottenuto punteggi più alti rispetto al GPT-3.5 su una varietà di benchmark. Si tratta di un importante passo avanti per le macchine poiché dimostra che ora non solo possono risolvere problemi per i quali sono state originariamente progettate, ma possono anche farlo meglio degli studenti universitari.

Ci sono alcune cose da prendere in considerazione quando si osserva questo risultato. Innanzitutto, al GPT-4 non è stata impartita alcuna formazione specifica per questi esami. Si è proceduto utilizzando i test più recenti disponibili al pubblico (nel caso delle Olimpiadi e delle domande a risposta libera AP) o acquistando le edizioni 2022-2023 degli esami pratici. In secondo luogo, è importante notare che le prestazioni del GPT-4 potrebbero non riflettere necessariamente le capacità dei partecipanti al test umani, poiché funziona secondo una serie diversa di principi e algoritmi.
Si tratta di un risultato importante, in quanto dimostra che le macchine non solo sono capaci di un'intelligenza simile a quella umana, ma possono anche superarci. Ciò apre la strada a un futuro in cui le macchine possono svolgere compiti sempre più complessi, portando infine a un futuro in cui possono assisterci nella nostra vita quotidiana.
 La capacità del GPT-4 di superare gli esseri umani in determinati compiti solleva interrogativi sul futuro dell'intelligenza artificiale e sul suo potenziale impatto sul mercato del lavoro. Evidenzia inoltre la necessità di una continua ricerca e sviluppo in questo campo per garantire che l'IA venga utilizzata in modo etico e responsabile. Leggi di più: 5+ modelli di IA Text-to-Image più attesi del 2023
La capacità del GPT-4 di superare gli esseri umani in determinati compiti solleva interrogativi sul futuro dell'intelligenza artificiale e sul suo potenziale impatto sul mercato del lavoro. Evidenzia inoltre la necessità di una continua ricerca e sviluppo in questo campo per garantire che l'IA venga utilizzata in modo etico e responsabile. Leggi di più: 5+ modelli di IA Text-to-Image più attesi del 2023
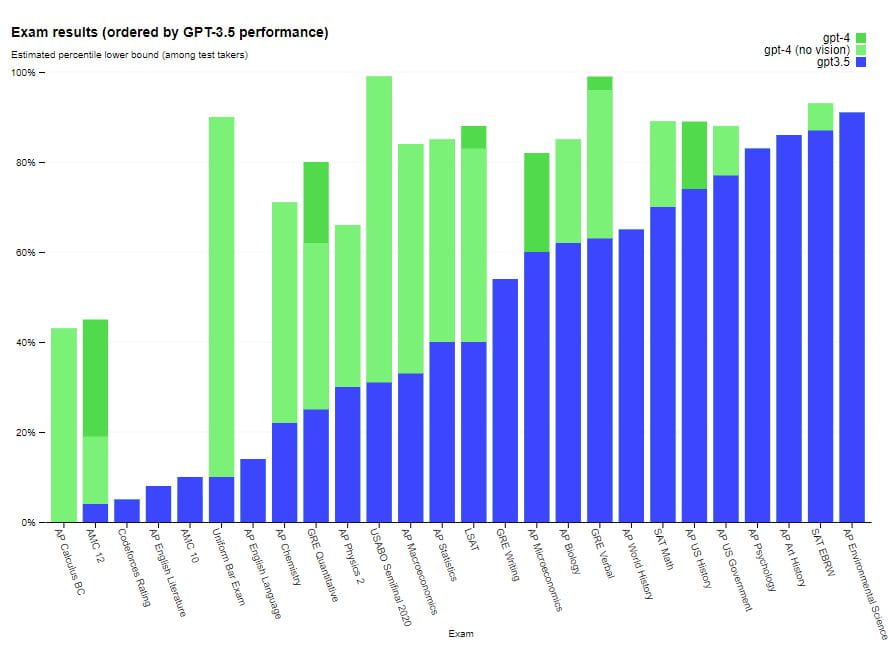
GPT-4, ad esempio, supera un esame di abilitazione simulato con un punteggio nel 10% più alto dei candidati; il punteggio di GPT-3.5 era nel 10% più basso. Questo significativo miglioramento nelle prestazioni di GPT-4 è dovuto ai suoi dati di training più grandi e all'architettura migliorata. Si prevede che avrà un'ampia gamma di applicazioni in vari campi, tra cui l'elaborazione del linguaggio naturale e la scrittura automatizzata.
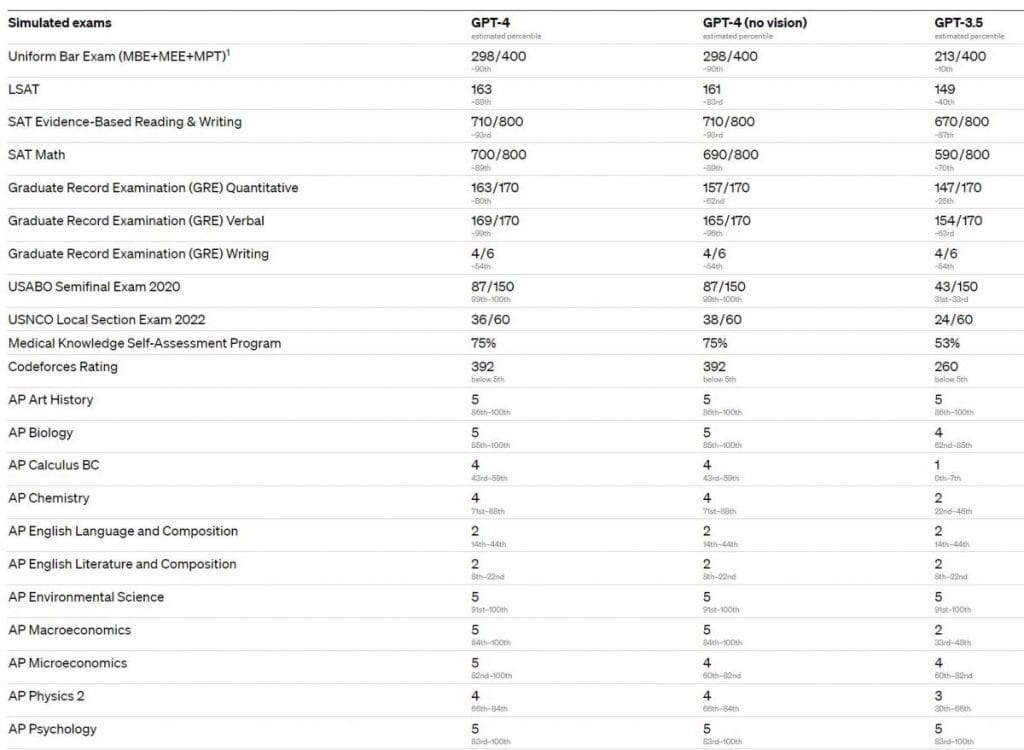 GPT-4 mostra prestazioni di livello umano nella maggior parte di questi esami professionali e accademici. In particolare, ha superato una versione simulata dell'Uniform Bar Examination con un punteggio tra il 10% dei candidati migliori. Le capacità del modello negli esami sembrano derivare principalmente dal processo di pre-formazione e non sono significativamente influenzate da RLHF. Nelle domande a scelta multipla, sia il modello GPT-4 di base che il modello RLHF hanno ottenuto risultati ugualmente buoni in media tra gli sviluppatori dell'esame testato.
GPT-4 mostra prestazioni di livello umano nella maggior parte di questi esami professionali e accademici. In particolare, ha superato una versione simulata dell'Uniform Bar Examination con un punteggio tra il 10% dei candidati migliori. Le capacità del modello negli esami sembrano derivare principalmente dal processo di pre-formazione e non sono significativamente influenzate da RLHF. Nelle domande a scelta multipla, sia il modello GPT-4 di base che il modello RLHF hanno ottenuto risultati ugualmente buoni in media tra gli sviluppatori dell'esame testato.
La maggior parte dei modelli all'avanguardia (SOTA), compresi quelli che possono utilizzare protocolli di formazione aggiuntivi o una progettazione specifica per il benchmark, nonché i grandi modelli linguistici esistenti, sono notevolmente superati da GPT-4.
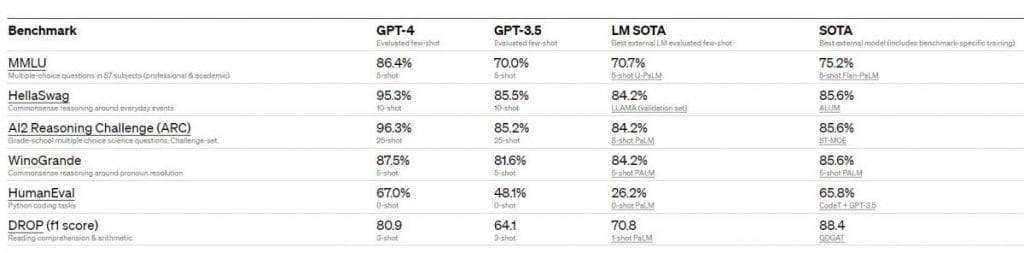 Le prestazioni di GPT-4 in termini di standard accademici. Gli sviluppatori mettono a confronto GPT-4 con il miglior SOTA per un few-shot valutato da LM e con il miglior SOTA con formazione specifica per benchmark. Ad eccezione di DROP, GPT-4 supera tutti gli LM attuali su tutti i benchmark e SOTA con formazione specifica per benchmark.
Le prestazioni di GPT-4 in termini di standard accademici. Gli sviluppatori mettono a confronto GPT-4 con il miglior SOTA per un few-shot valutato da LM e con il miglior SOTA con formazione specifica per benchmark. Ad eccezione di DROP, GPT-4 supera tutti gli LM attuali su tutti i benchmark e SOTA con formazione specifica per benchmark.
Internamente, gli sviluppatori hanno utilizzato GPT-4, che ha avuto un impatto significativo su attività come programmazione, vendite, supporto e moderazione dei contenuti. La seconda fase del nostro metodo di allineamento è ora in corso, poiché gli sviluppatori lo utilizzano per aiutare gli esseri umani a esaminare i risultati dell'IA.
Il dataset MMLU (Massive Multi-Task Language Understanding) contiene domande su un'ampia gamma di argomenti sulla comprensione del linguaggio in diverse attività (che abbracciano 57 domini, tra cui matematica, biologia, giurisprudenza, scienze sociali e umane, ecc.). Ci sono quattro possibili risposte alla domanda, una delle quali è corretta. Vale a dire, l'ipotesi casuale mostra un risultato del 25% di risposte corrette. Guarda l'immagine qui sotto per esempi di domande e le loro difficoltà. La persona media che corregge (vale a dire, non è uno scienziato, non è un professore, una persona normale che lavora come correttore) risponde correttamente al 35% delle domande; tuttavia, gli esperti possono raggiungere un punteggio di +/- 90%.
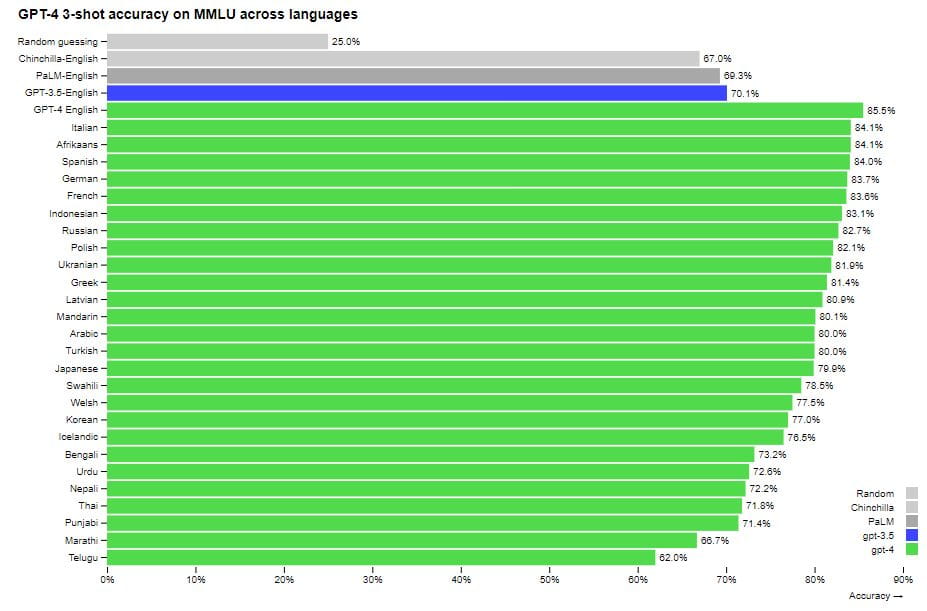 Prestazioni di GPT-4 in una gamma di lingue rispetto ai modelli precedenti in inglese su MMLU. GPT-4 supera le prestazioni in lingua inglese dei modelli linguistici esistenti per la grande maggioranza delle lingue esaminate, comprese le lingue a basse risorse come lettone, gallese e swahili. Leggi di più: 5 motivi per usare Bing basato sull'intelligenza artificiale anziché Google
Prestazioni di GPT-4 in una gamma di lingue rispetto ai modelli precedenti in inglese su MMLU. GPT-4 supera le prestazioni in lingua inglese dei modelli linguistici esistenti per la grande maggioranza delle lingue esaminate, comprese le lingue a basse risorse come lettone, gallese e swahili. Leggi di più: 5 motivi per usare Bing basato sull'intelligenza artificiale anziché Google
Originariamente, l'intero set di dati era in inglese. Ma cosa succederebbe se domande e risposte venissero tradotte in altre lingue, in particolare in quelle meno comuni? Il modello funzionerebbe in qualche modo per loro? In questo test, è stato utilizzato il servizio Microsoft Azure Translate per la traduzione. Le traduzioni non sono perfette; in alcuni casi, si perdono informazioni importanti. Tuttavia, anche in questo caso, il GPT-4 funziona bene in altre lingue. Nelle versioni tradotte del MMLU, il GPT-4 supera il livello di inglese di altri grandi modelli (incluso quello di Google) di 24 delle 26 lingue esaminate.
Inoltre, GPT-4 ha prestazioni migliori nelle lingue rare rispetto a ChatGPT in inglese (ChatGPT ha ottenuto un punteggio del 70,1%, mentre il punteggio del nuovo modello per il tailandese è stato del 71,8%). Il punteggio per il test in inglese è stato il più alto, con GPT-4 che ha ottenuto prestazioni migliori del 10% rispetto ad altri modelli, incluso il più grande PaLM di Google. Ha ottenuto un punteggio dell'86,4%, mentre un gruppo di esperti del 90%.
Entro l'estate del 2023, l'intelligenza artificiale potrebbe aver raggiunto un nuovo livello di potenza grazie a ChatGPT, un chatbot che utilizza l'algoritmo GPT-4 e supera GPT-3 di un fattore 570. Una serie di elementi contribuiscono al successo di ChatGPT, tra cui il suo design per essere più "simile all'uomo" e il suo utilizzo di data mining all'avanguardia e di elaborazione del linguaggio naturale per aumentarne l'efficacia e l'accuratezza.
Microsoft e OpenAI hanno annunciato il rinnovo della loro collaborazione e i piani per la ricerca Bing per adottare capacità di ricerca potenziate dall'intelligenza artificiale a gennaio. Il sostituto del modello GPT3.5 molto sofisticato, GPT4, è appena stato lanciato e ha il potenziale per migliorare notevolmente la capacità di ricerca Bing di comprendere le query in linguaggio naturale e fornire risultati più accurati. È una buona idea avere un buon piano di backup nel caso in cui qualcosa vada storto.
Leggi altre notizie correlate:
Ecco ChatGPT: l'intelligenza artificiale che può uccidere Google
ChatGPT supera l'esame MBA di Wharton
L'evoluzione dei chatbot dall'era T9 e GPT-1 a ChatGPT
Il post GPT-4 supera GPT-3.5 in tutti i settori in una serie di parametri di riferimento è apparso per la prima volta su Metaverse Post.