

L'allerta è scattata alle 2:23 del mattino.
Non il forte. Il tranquillo. Quello che significa che qualcosa di strutturale è cambiato, non che qualcosa si è rotto.
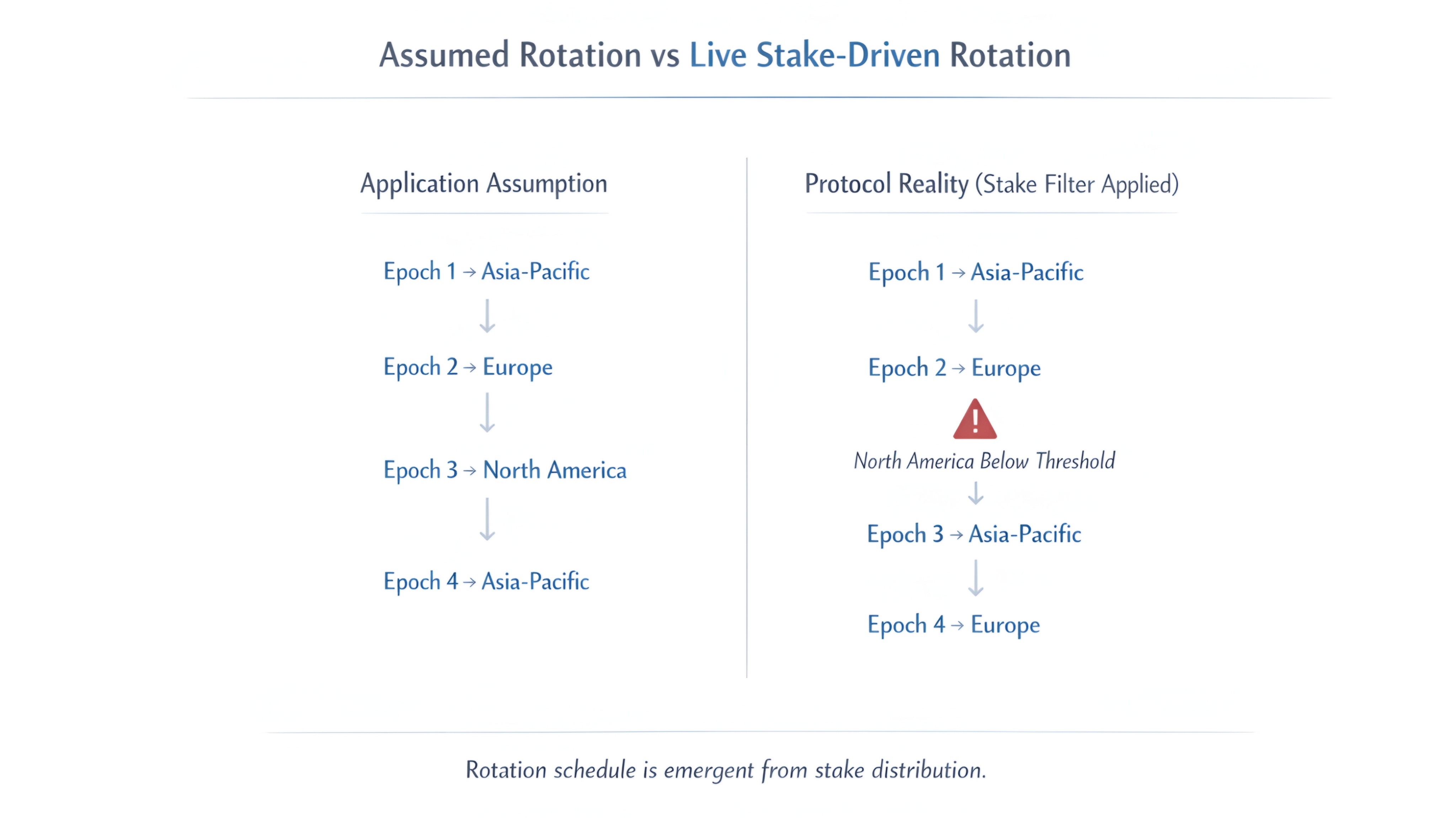
Avevo osservato la distribuzione dello stake per sei giorni. La zona del Nord America era al 94% della soglia. Non sotto. Non sopra. Solo respirando al limite del minimo che il protocollo richiede prima di attivare una zona.
Sono andato a dormire pensando che il 94% andasse bene.
Non andava bene.
Il confine dell'epoca è stato colpito alle 2:19 del mattino. Il protocollo ha eseguito il filtro dello stake. La zona del Nord America è scesa al 91% qualche volta nelle quattro ore in cui non stavo guardando. Tre validatori hanno redelegato. Non per attaccare. Non per manipolare. Solo movimento normale dello stake, quello che accade ogni giorno su ogni catena, quello che nessuno documenta perché prima non importava.
Su FOGO è importante.
La zona è scesa sotto la soglia. Il protocollo l'ha filtrata. La rotazione che doveva andare Asia-Pacifico poi Europa poi Nord America ora va Asia-Pacifico poi Europa poi Asia-Pacifico di nuovo.
La mia applicazione era hardcoded per tre zone.
Ora sta funzionando contro due.
Ho trovato il bug alle 2:31. Non nei log. Nel comportamento. Il motore di liquidazione stava scattando secondo il programma, ma le conferme di esecuzione stavano arrivando il 40% più lentamente rispetto alla baseline. Non rotto. Solo... allungato. Come se l'applicazione stesse cercando qualcosa che prima c'era.
Stava cercando validatori del Nord America che non erano più nella rotazione.
L'applicazione conosceva il programma. Non sapeva che il programma potesse cambiare.
Avevo letto il litepaper. Pagina sei. Parametro della soglia di stake minimo che filtra le zone con stake totale delegato insufficiente. L'avevo letto e avevo pensato: scelta di design interessante. Non avevo pensato: questo scatta alle 2:19 di un martedì e l'intero modello temporale sarà sbagliato quando ti sveglierai.
Il litepaper non ti dice come ci si sente quando una zona scompare.

Ecco come ci si sente.
Tutto continua a funzionare. Questa è la prima cosa. FOGO non si ferma. I blocchi continuano a arrivare ogni 40 millisecondi. Le zone attive continuano a produrre. Firedancer mantiene l'esecuzione uniforme. La catena è completamente sana.
La tua applicazione è l'unica cosa che sa che qualcosa è cambiato.
E la tua applicazione lo sa solo perché è stata costruita con assunzioni che il protocollo non ha mai promesso di mantenere.
Tre zone. Un'ora ciascuna. Rotazione pulita. Avevo costruito un modello di temporizzazione di liquidazione attorno a quel ritmo. Pre-posizionare 55 minuti in ogni epoca. Eseguire a 58 minuti. Uscire prima del picco di latenza del passaggio della zona. Pulito. Ripetibile. Redditizio.
Il modello assumeva che il Nord America si attivasse sempre. Il protocollo non assumeva nulla del genere.
Ho estratto i dati del validatore alle 3:02. Ho tracciato le redelegazioni. Tre validatori di medie dimensioni avevano spostato stake nella zona Asia-Pacifico nelle 96 ore precedenti. Non coordinato. Solo deriva. Il tipo di movimento di stake organico che sembra casuale perché è casuale.
Ma il movimento casuale di stake su FOGO ha conseguenze deterministiche ai confini dell'epoca.
Il protocollo non si preoccupa del motivo per cui lo stake si è mosso. Esegue il filtro. La zona soddisfa la soglia o la zona non si attiva. Il Nord America non si è attivato. La rotazione è cambiata. La mia applicazione ha ereditato il cambiamento senza preavviso perché il cambiamento non richiedeva preavviso. Funzionava esattamente come documentato.
Stavo operando su assunzioni che non avevo mai documentato neanche per me stesso.
La perdita non è stata catastrofica. Esecuzione più lenta, non esecuzione fallita. Forse $31,000 in finestre di liquidazione perse in quattro ore prima di accorgermene e patchare il modello temporale. Forse di più. Il tipo di perdita che non appare come una perdita, appare come sotto rendimento, che è più difficile da vedere e quindi più difficile da riparare.
L'ho patchato alle 3:44. Ho aggiunto una query di configurazione della zona al confine dell'epoca. Estrarre il set di zone attive dalla catena prima di assumere il modello di rotazione. Mi è costato 8 millisecondi per epoca. Mi ha salvato dal costruire altre quattro ore di logica su una base che si era già spostata.
La patch sembrava ovvia alle 3:44. Non sembrava necessaria in nessun momento nei sei giorni precedenti.
Questa è la cosa riguardo al meccanismo della soglia di stake di FOGO di cui nessuno parla perché tutti presumono che lo gestiranno correttamente e nessuno presume correttamente fino a dopo che non lo hanno fatto.
La rotazione della zona non è un programma fisso. Sembra un programma fisso. Si comporta come un programma fisso per giorni o settimane alla volta, abbastanza a lungo da iniziare a trattarlo come infrastruttura piuttosto che come proprietà emergente della distribuzione dello stake.
Poi tre validatori spostano stake in una notte di martedì e il programma su cui hai costruito la tua applicazione smette di essere il programma.
Il protocollo non è sbagliato. Il protocollo ha filtrato una zona che non soddisfaceva la soglia. Questo è ciò che dovrebbe fare. Il parametro di sicurezza esiste perché una zona con stake insufficiente è una zona che può essere attaccata. Il protocollo ha protetto la rete.
Non ha semplicemente protetto le mie assunzioni temporali.
Ho costruito su catene ad alte prestazioni per tre anni. I modi di fallimento che conosco sono congestione, transazioni perse, timeout RPC, finalità fallita. Questi sono fallimenti rumorosi. Si annunciano da soli. Il monitoraggio li cattura. Gli avvisi attivano l'allerta rumorosa, non quella silenziosa.
FOGO ha una modalità di fallimento che non avevo mai incontrato prima, che è l'assunzione che era vera ieri diventando falsa al confine dell'epoca perché la distribuzione dello stake è cambiata e il protocollo ha risposto correttamente e la tua applicazione non stava monitorando la distribuzione dello stake perché non sapevi di dover monitorare la distribuzione dello stake.
È un fallimento silenzioso. La catena è sana. La tua applicazione è sbagliata. La lacuna tra questi due stati è invisibile fino a quando non misuri la cosa giusta.
Stavo misurando la produzione di blocchi e la conferma delle transazioni e la latenza della zona. Non stavo misurando la prossimità della soglia di stake per zona. Non sapevo che fosse una cosa da misurare fino a quando l'allerta silenziosa è scattata alle 2:23.
Gli sviluppatori che costruiscono su FOGO e non colpiscono mai questo non lo colpiranno perché sono migliori. Non lo colpiranno perché la loro distribuzione dello stake è rimasta sopra la soglia, o perché la loro applicazione non dipende dalla cadenza di rotazione, o perché hanno avuto fortuna con il tempismo delle loro redelegazioni.
Quelli che lo colpiranno lo colpiranno nello stesso modo in cui l'ho colpito io. Non da un fallimento di documentazione. Il litepaper è chiaro. Soglia di stake minima, pagina sei, linguaggio semplice.
Colpiranno da accumulo di assunzioni. Ogni giorno la zona ruota correttamente, l'assunzione che ruoterà sempre correttamente diventa un po' più forte. L'assunzione non viene mai testata fino all'epoca in cui viene rotta, e nel frattempo sono le 2:19 e il filtro è già scattato e la zona è già andata.
Ho aggiunto tre cose al mio monitoraggio dopo quella notte.
Prossimità della soglia di stake per zona, aggiornata ogni 30 minuti. Set di zone attive estratto ad ogni confine dell'epoca prima di eseguire qualsiasi logica temporale. Soglia di allerta impostata al 97% del minimo, non al 94%, perché il 94% sembrava sicuro e non era sicuro.
La terza cosa che ho aggiunto era più semplice. Un commento nel codice sopra la logica di rotazione.
Dice: il programma di rotazione è emergente. interrogarlo. non assumerlo.
Otto parole. Mi è costato $31,000 scriverle.
L'architettura di FOGO è onesta su questo. Il filtro della soglia di stake non è un meccanismo nascosto. È documentato, spiegato, giustificato. Il protocollo non promette che una zona si attiverà. Fa una promessa che se una zona soddisfa la soglia si attiverà. La distinzione è precisa e il litepaper lo afferma precisamente.
L'ho letto come una garanzia. Era una condizione.
Quella lacuna tra garanzia e condizione è dove il mio modello temporale viveva per sei giorni, comodo e sbagliato, fino a quando l'epoca è cambiata e la zona non era lì e l'allerta silenziosa è scattata e ho imparato la differenza alle 2:23.
FOGO non ti deve un programma di rotazione stabile. Ti deve uno corretto.
Non sono la stessa cosa.
Gli sviluppatori che comprendono questo presto costruiranno monitoraggi che osservano la distribuzione dello stake invece di assumerla. Interrogeranno la configurazione della zona ai confini dell'epoca invece di memorizzarla all'avvio. Tratteranno il modello di rotazione come dati live invece di infrastruttura statica.
Gli sviluppatori che lo apprendono nel modo in cui l'ho appreso io lo apprenderanno alle 2, nei log, inseguendo un'allerta silenziosa che è scattata perché qualcosa di strutturale è cambiato e niente si è rotto e la catena ha continuato a funzionare e l'unica cosa sbagliata era il modello all'interno della loro applicazione.
Continuo a monitorare lo stake della zona Nord America ogni 30 minuti.
È al 96% in questo momento.
Controllo di nuovo tra 30 minuti.
