

Punti principali da ricordare
Il Ledger di Binance memorizza i saldi dei conti e le transazioni, consentendo anche ai servizi di effettuare transazioni.
Crea le condizioni necessarie per un throughput elevato, una disponibilità 24 ore su 24, 7 giorni su 7 e un'accuratezza dei dati a livello di bit.
Il ruolo di Binance Ledger dietro le quinte lo rende una delle tecnologie più importanti di Binance. Scopri esattamente come funziona e i problemi che sta risolvendo nel funzionamento del più grande exchange di criptovalute al mondo qui.

Ti sei mai chiesto esattamente cosa fa funzionare Binance? Con la necessità di elaborare milioni di transazioni al giorno su una base di utenti enorme, vale la pena dare un'occhiata a cosa Binance ha sotto il cofano.
Alla base delle operazioni tecniche di Binance c'è il suo Ledger. Il Ledger memorizza i saldi e le transazioni dei conti, consentendo al contempo ai servizi di effettuare transazioni.
Binance ha requisiti elevati per il Ledger
Come potete immaginare, i requisiti per Ledger sono elevati per soddisfare l'enorme domanda degli utenti. Ci sono tre punti principali da considerare:
Elevata capacità di elaborazione con possibilità di grandi quantità di TPS (transazioni al secondo) nelle ore di punta.
Disponibilità 24 ore su 24, 7 giorni su 7, senza tempi di inattività.
Precisione dei dati a livello di bit, senza perdite di fondi o errori di transazione.
Diamo un'occhiata a un esempio di una voce base nel Ledger. Ecco una transazione comune in cui il conto 1 trasferisce 1 BTC al conto 2.
Saldo prima della transazione:
tabella-1
Saldo dopo la transazione:
tabella-2
In questa transazione ci sono due comandi:
Conto 1 -1 BTC
Conto 2 +1 BTC
Una volta effettuata la transazione, verranno archiviati due registri del saldo a scopo di verifica e riconciliazione.
tabella-3
La soluzione standard del settore
Una soluzione standard per i registri contabili del settore si basa su un database relazionale. Tornando all'esempio precedente, i due comandi della transazione possono essere tradotti in due istruzioni SQL ed eseguiti in una transazione di database (tabella 4).
tabella-4
I vantaggi della soluzione
È piuttosto semplice da implementare.
È facile applicare tecniche comuni di ottimizzazione del database, come la suddivisione in lettura/scrittura e lo sharding, per migliorare le prestazioni.
Per i DevOps non è difficile ripristinare un sistema in caso di failover, nonché monitorare e gestire un database commerciale.
Gli svantaggi della soluzione
Il TPS diminuirà drasticamente in caso di condizioni di gara dovute ai blocchi di fila.
È difficile scalare orizzontalmente per migliorare le prestazioni.
Il problema del conto caldo
Sfortunatamente per Binance, la soluzione di settore illustrata sopra non soddisfa i suoi elevati requisiti. Quando si verifica una transazione, deve mantenere i blocchi di riga di ogni riga coinvolta. Mentre alcuni account hanno relativamente poche transazioni da gestire, ci sono, ovviamente, account impegnati con molte transazioni simultanee. In questo caso, solo una transazione è in grado di mantenere il blocco di riga dell'account.
Le altre transazioni non possono quindi far altro che attendere che il blocco venga rilasciato. Chiamiamo questa situazione un problema di account caldo e test interni dimostrano che il TPS subirà almeno 10 cali in questa situazione. Potete vedere questo problema nella tabella 5 qui sotto.
Esempio di account attivo:
tabella-5
La soluzione Ledger di Binance
Come risolviamo il problema degli account caldi?
Una possibile soluzione al nostro problema è convertire in modo innovativo il modello multi-thread in una modalità single-thread. Questo eviterà il problema della race condition e, di conseguenza, non si verificherà un problema di account hot.
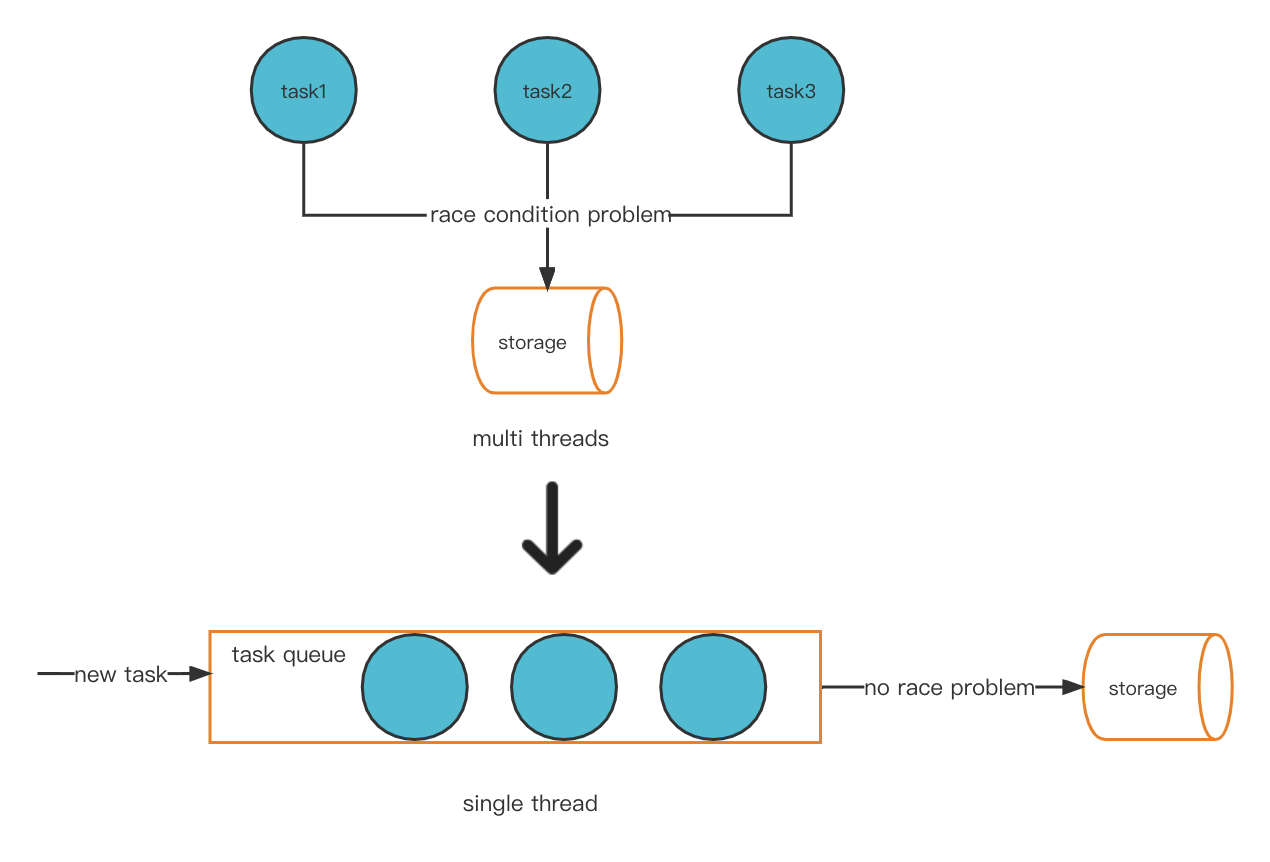
Nuovo modello di thread
Comunicazione basata sui messaggi
Dopo aver implementato il nostro nuovo modello di thread, è necessario risolvere un problema di comunicazione. Il livello della macchina a stati è single-thread, ma il livello di rete è multi-thread, quindi come possiamo comunicare in modo efficiente tra i due?
Un Disruptor [1] è il passo successivo nel puzzle. Crea una coda ad alte prestazioni e senza blocchi basata su un design di buffer ad anello.
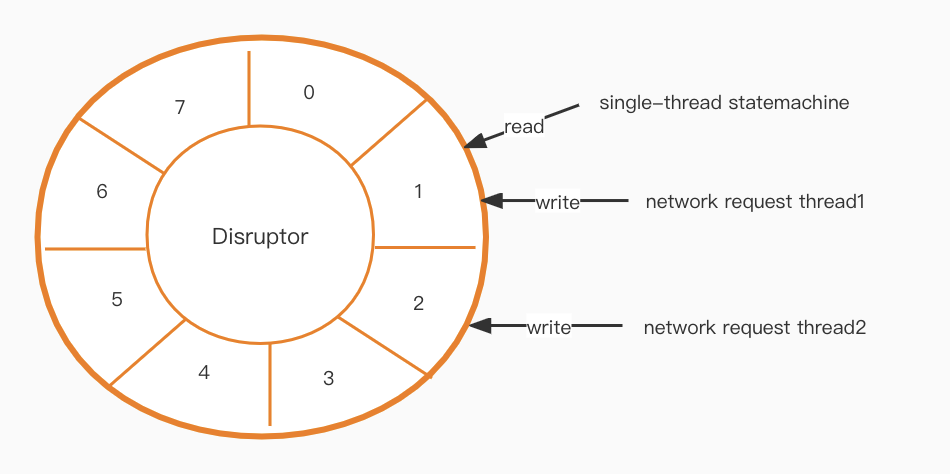
Alta disponibilità
Finora, abbiamo raggiunto prestazioni elevate utilizzando un modello in memoria e l'archiviazione locale di RocksDB [2]. Ma, ancora una volta, si presenta una nuova sfida. Ora dobbiamo garantire un'elevata disponibilità dei dati.
Per garantire la coerenza dei dati tra i nodi, utilizziamo un algoritmo di consenso Raft [3]. Ciò significa che il numero di backup dei dati è pari al numero di nodi non leader presenti. L'algoritmo garantisce inoltre che il sistema continui a funzionare anche con almeno la metà dei nodi integri, per contribuire a garantire un'elevata disponibilità del servizio.
Ruoli del dominio Raft:
Leader. Il leader elabora tutte le richieste dei clienti e replica l'operazione a tutti i follower.
Seguace. I seguaci seguono il leader in tutte le operazioni. Se il leader fallisce, uno dei seguaci verrà eletto come nuovo leader.
Apprendista. Gli apprendisti sono follower senza diritto di voto che inviano ogni record di modifica idempotente/transazione ad altri servizi.
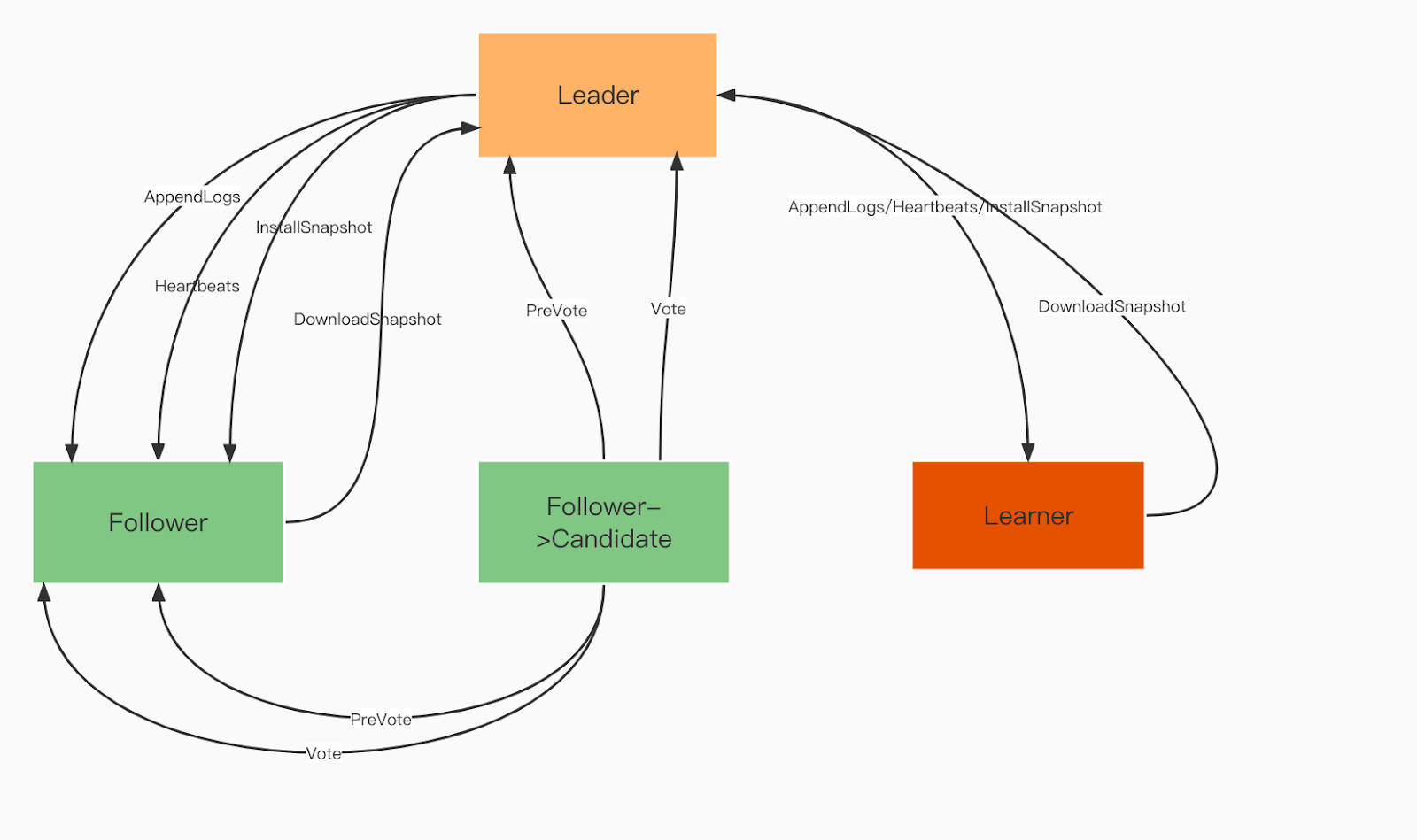
Ruoli del dominio Raft
CQRS (Segregazione delle responsabilità delle query di comando)
Un altro criterio chiave che vogliamo garantire sono le maggiori prestazioni di scrittura del Ledger e la sua capacità di gestire condizioni di query più diversificate. Per questo, dobbiamo creare domini diversi. Il dominio raft offre una scrittura più efficiente basata su rocksdb+raft, mentre il dominio view ascolta i messaggi del dominio raft e li salva nel database relazionale per le query esterne. Possiamo anche implementare la segregazione delle responsabilità delle query di comando a livello di architettura.
Architettura del registro
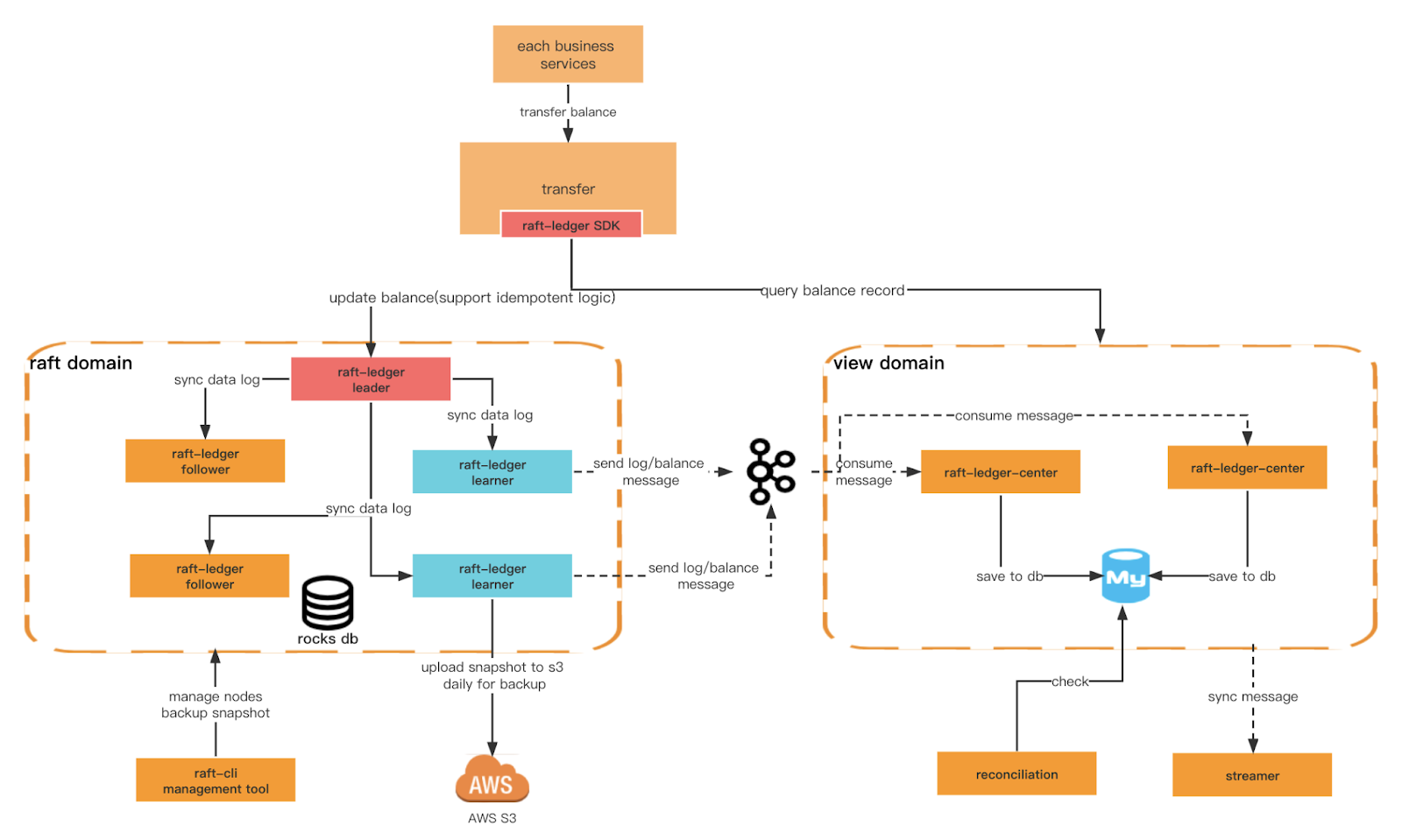
Architettura generale
Termini tra Raft e Ledger:
tabella-6
Visualizza i ruoli di dominio
Centro del registro della zattera
Utilizza il messaggio prodotto dall'apprendista e memorizza i dati delle transazioni e del saldo in MySQL per scopi di query.
Elaborazione della richiesta
Una richiesta di transazione passerà prima attraverso il livello di rete, il livello di registro (gestore delle richieste) e il livello di raft (sincronizzazione dei log di raft). Quindi tornerà al livello di registro (macchina a stati), al livello di rete (gestore delle risposte) e infine restituirà una risposta al client.
I dati vengono passati tramite la coda tra i due livelli.
Livello di rete: deserializza la richiesta RPC e la inserisce nella coda delle richieste.
Ledger Layer: riceve la richiesta dalla coda e prepara il contesto. Quindi inserisce i metadati della richiesta nella coda raft.
Raft Layer: recupera i metadati della richiesta dalla coda del raft e li sincronizza tra tutti i follower. Il risultato verrà quindi inserito nella coda di applicazione.
Livello Ledger: recupera i dati dalla coda di applicazione e aggiorna la macchina a stati. Inserirà quindi il risultato nella coda di risposta.
Livello di rete: ottiene il risultato dalla coda di risposta e costruisce e serializza i dati di risposta prima di restituirli al client.
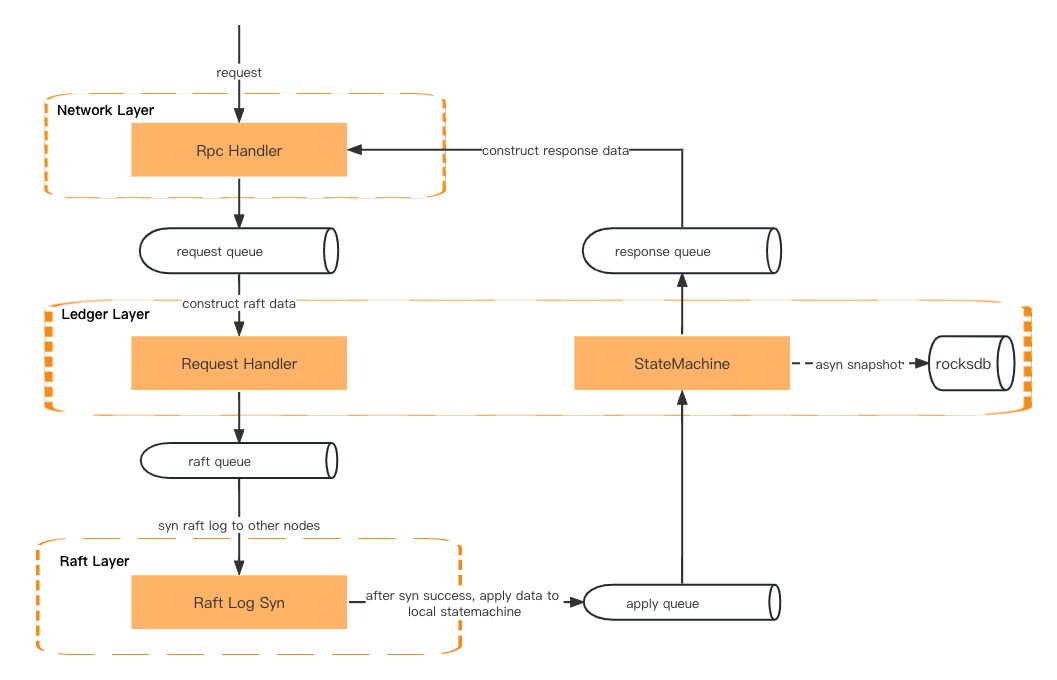
Elaborazione della richiesta
Recupero dati
Ogni nodo Ledger attiverà uno snapshot generico basato su un intervallo di tempo. Inoltre, implementiamo anche uno snapshot coerente. Ogni nodo viene attivato allo stesso indice del log raft per garantire che la macchina a stati sia esattamente la stessa quando ogni nodo attiva uno snapshot. Lo snapshot verrà quindi caricato su S3 per la verifica da parte di Checker e come backup a freddo.
Al riavvio, Ledger legge lo snapshot locale e ricostruisce la macchina a stati. Quindi riproduce il log del raft locale e sincronizza il log più recente dal leader finché non raggiunge l'indice più recente. Se lo snapshot locale o il log del raft non esiste, verrà ottenuto dal leader.
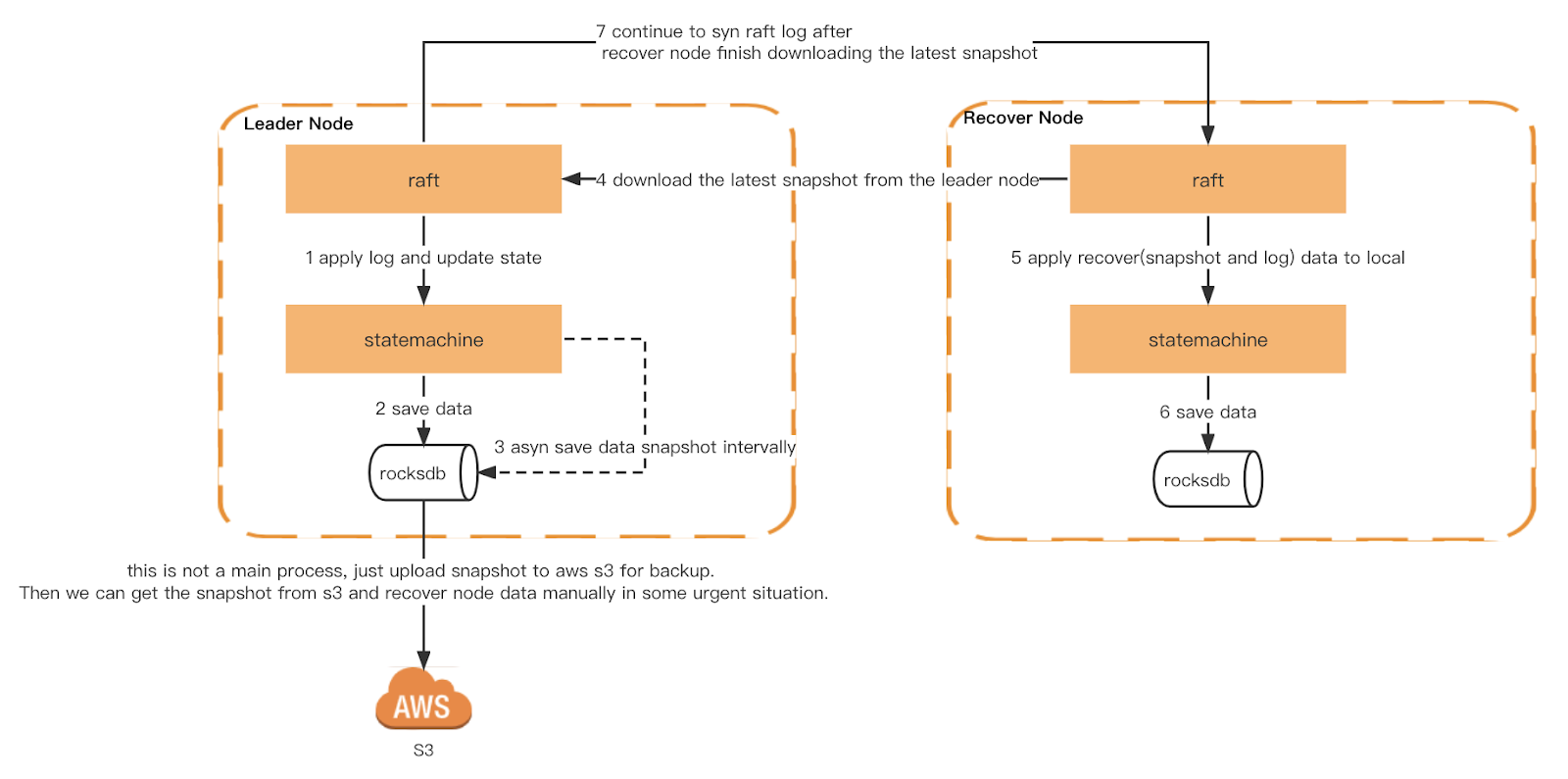
Snapshot e ripristino
Tolleranza ai disastri
Per migliorare la disponibilità e la tolleranza agli errori, i nodi Ledger vengono distribuiti in zone diverse. Finché più della metà dei nodi è integro, i dati non andranno persi e il failover verrà completato in un secondo.
Anche se l'intero cluster dovesse fallire, il che è molto improbabile, possiamo comunque ripristinarlo tramite lo snapshot coerente archiviato in Amazon S3 e recuperare gli ultimi dati persi tramite il sistema downstream.
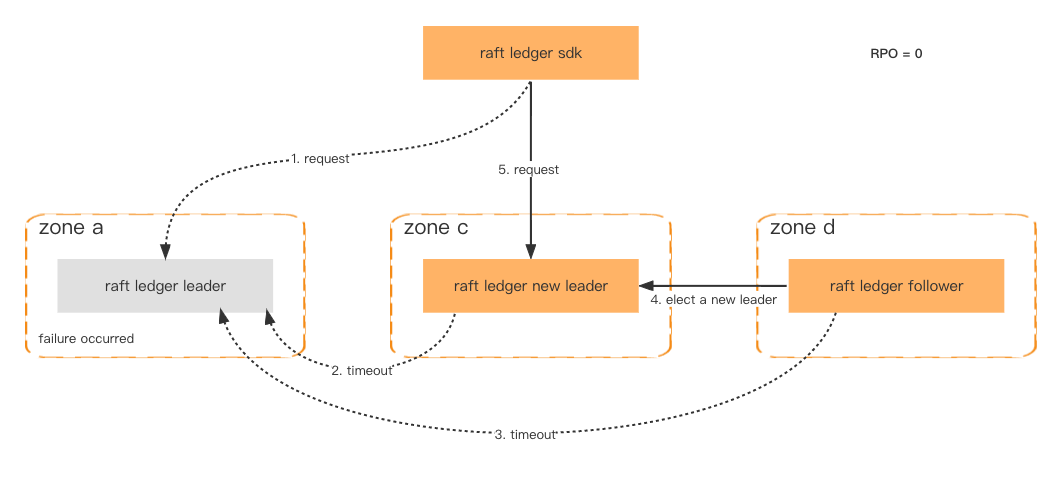
Tolleranza ai guasti
Prestazione
La tabella seguente mostra le specifiche hardware per il test delle prestazioni
Test interni dimostrano che un cluster a 4 nodi (un leader, due follower e un learner) può elaborare più di 10.000 TPS. Per impostazione predefinita, il cluster elabora tutte le transazioni una alla volta. Non vi è alcuna condizione di blocco o di competizione. Pertanto, nello scenario di account attivo, il TPS è elevato quanto negli scenari normali.
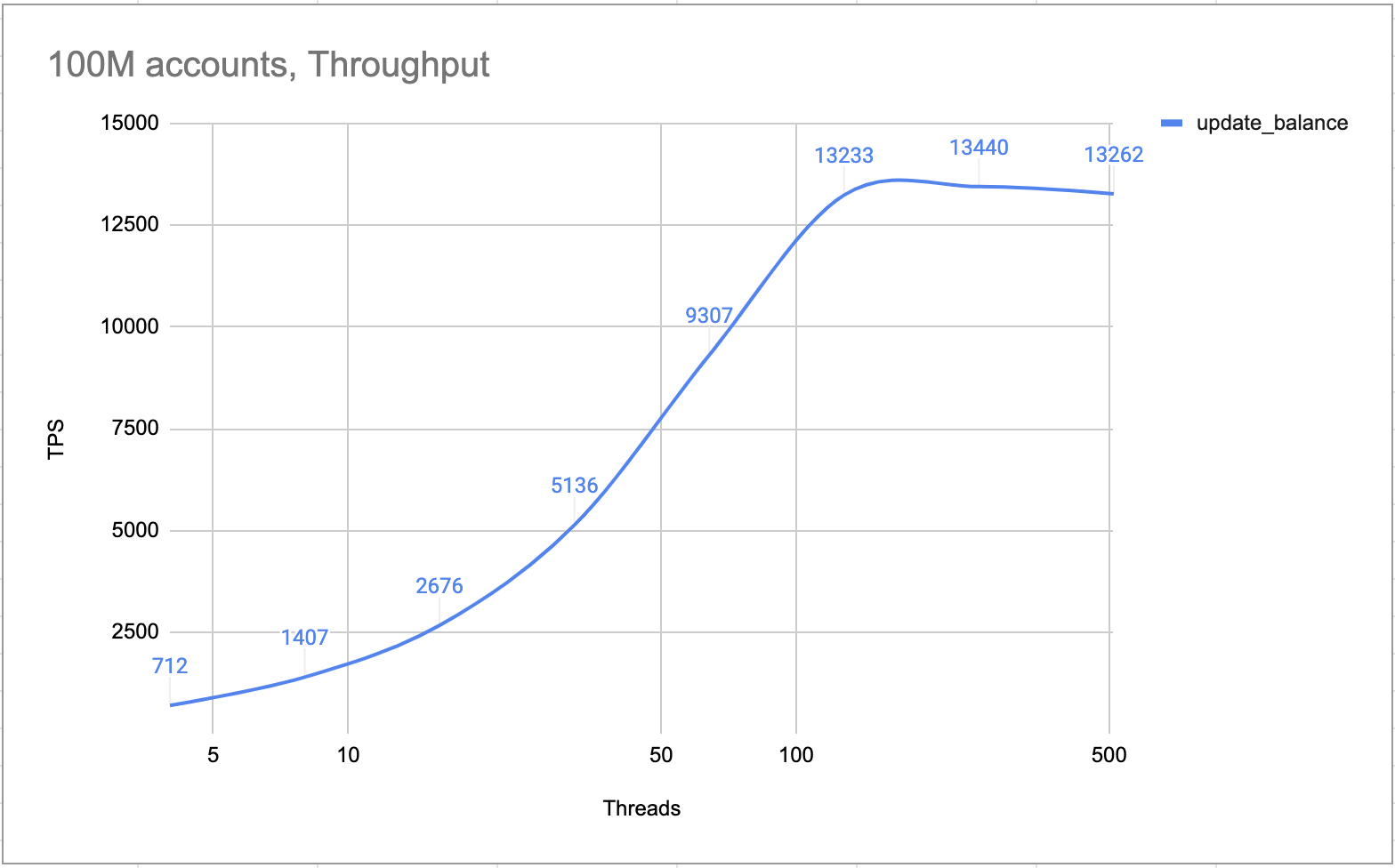
Conto caldo TPS
La figura seguente mostra la latenza di ciascuna transazione. La maggior parte delle transazioni potrebbe essere completata entro 10 ms. Le transazioni più lente potrebbero essere completate entro 25 ms.
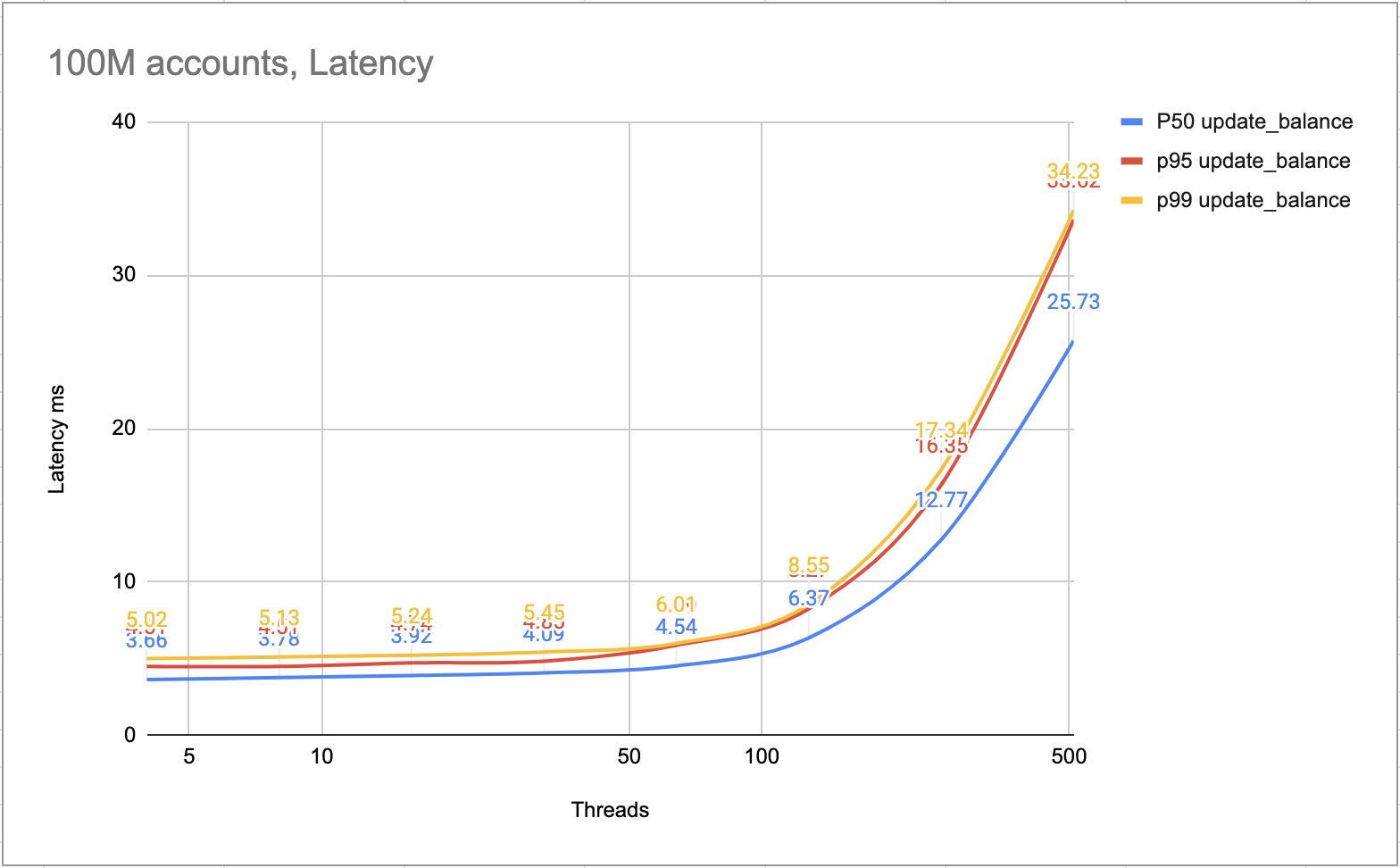
Latenza ms
Potenziamo i nostri servizi con Binance Ledger
Come avete visto, la risposta del settore tradizionale al problema degli account hot non soddisfa le esigenze di Binance e dei suoi clienti. Utilizzando un approccio progettato specificamente per l'infrastruttura di Binance, abbiamo ottenuto un'esperienza di scambio e di prodotto tra le più fluide disponibili. Siamo lieti di condividere con voi la nostra esperienza e speriamo che comprendiate meglio cosa contribuisce al funzionamento di un servizio come Binance.
Per maggiori informazioni sulla nostra infrastruttura tecnologica, leggi il seguente articolo:
(Blog di Binance) Utilizzo di MLOps per creare una pipeline di apprendimento automatico end-to-end in tempo reale
(Binance Blog) Incontra il CTO: Rohit riflette su criptovalute, blockchain, Web3 e il suo primo mese in Binance
Riferimenti
[1] Disgregatore LMAX
[2] RocksDB
[3] L'algoritmo di consenso Raft