

All’inizio di settembre, Yandex ha ospitato una mini-conferenza privata sull’intelligenza artificiale generativa, fornendo una piattaforma per approfondimenti nel mondo dell’intelligenza artificiale. Tuttavia, la conferenza ha portato rivelazioni significative, soprattutto per quanto riguarda l'attesissimo YandexGPT 2.
La presentazione di YandexGPT 2 da parte di Yandex ha suscitato grande attesa nella comunità dell'intelligenza artificiale. I creatori di questo modello hanno esplorato varie caratteristiche distintive, incluso un modulo specializzato progettato per cercare e fornire risposte basate sui dati dei risultati di ricerca. In particolare, le rivelazioni del team hanno svelato un aspetto sorprendente: anche se addestrato su un vasto archivio di dati interni Yandex che abbracciano oltre un decennio di lavoro sui meccanismi di ricerca neurale, questo modello proprietario non era ancora all’altezza del formidabile GPT-4. Questo sviluppo significativo sottolinea i notevoli passi avanti raggiunti da GPT-4. Questa osservazione accentua la supremazia di GPT-4 sia sugli sviluppi proprietari che sulle precedenti iterazioni open source.
Ampliando tali conoscenze fondamentali, Google ha condotto uno studio per valutare l'accuratezza delle risposte dei Large Language Models (LLM) dotati dell'accesso ai motori di ricerca. Sebbene l’idea di integrare uno strumento esterno con i LLM non sia nuova, Google ha scoperto che la complessità risiede nella valutazione e nella convalida sfumate di questi modelli. I fattori cruciali che danno forma a questa integrazione comprendono la selezione di un prompt attentamente realizzato e le capacità intrinseche dei LLM.
Metodologia di test LLM di Google
Un corpus curato di 600 domande è stato diviso in quattro gruppi distinti. Ciascun gruppo ha dato priorità all’accuratezza fattuale, ma un gruppo si è distinto per aver incluso domande radicate in false premesse. Ad esempio, domande come “cosa ha scritto Trump dopo essere stato ripubblicato su Twitter?” conteneva una premessa imprecisa, poiché Trump non era stato riammesso. I restanti tre gruppi hanno introdotto variabili di obsolescenza della risposta: mai, raramente e spesso. Nel gruppo “mai”, ci si aspettava che gli LLM rispondessero esclusivamente a memoria, mentre le domande sugli eventi recenti richiedevano una ricerca in tempo reale. Ciascun gruppo era composto da 125 domande.
Le domande sono state presentate a una vasta gamma di modelli. Curiosamente, le domande contenenti false premesse hanno rivelato la predominanza di GPT-4 e ChatGPT, che hanno abilmente confutato tali premesse, indicando la loro formazione specifica per gestire tali sfide.
Ne è seguita un’analisi comparativa, che ha messo a confronto ChatGPT, GPT-4, ricerca Google (basata su frammenti di testo o risposte sulla prima pagina) e PPLX.AI (una piattaforma che sfrutta ChatGPT per aggregare le risposte di Google, rivolte agli sviluppatori). In questo contesto, i LLM hanno fornito risposte esclusivamente dalla loro memoria.
Un’osservazione degna di nota è che la ricerca su Google ha fornito risposte corrette in media nel 40% dei casi nei quattro gruppi. L’accuratezza per le domande “eterne” era pari al 70%, mentre le domande con premesse false sono crollate solo all’11%. Le prestazioni di ChatGPT sono state in media del 26%, mentre GPT-4 ha raggiunto il 28%, rispondendo in modo impressionante a domande con premesse false nel 42% dei casi. PPLX.AI ha dimostrato un tasso di successo del 52%.
Lo studio ha approfondito il problema integrando un nuovo approccio. Ogni domanda richiedeva una ricerca su Google, con i risultati incorporati nella richiesta. Agli LLM è stato quindi richiesto di "leggere" queste informazioni prima di comporre le loro risposte. Questa tecnica ha consentito l'apprendimento Few-Shot (dove gli esempi sono presentati nel prompt per guidare il modello) e un'attenta considerazione passo passo prima di rispondere.
I risultati sono stati a dir poco affascinanti. GPT-4 ha mostrato un notevole punteggio di qualità del 77%, rispondendo a domande “eterne” con una precisione del 96% e affrontando domande con premesse false con un’encomiabile precisione del 75%. Sebbene ChatGPT offrisse parametri leggermente meno impressionanti, ha sovraperformato sia PPLX.AI che la ricerca di Google.
Padroneggiare la progettazione dei prompt dell'intelligenza artificiale: approfondimenti chiave da PPLX.AI e dagli esperti Google
La capacità di guidare efficacemente i Large Language Models (LLM) attraverso un labirinto di informazioni non è un’impresa da poco. Tuttavia, una recente esplorazione dei suggerimenti dell’intelligenza artificiale ha illuminato le strategie chiave che promettono di migliorare la qualità delle risposte generate dal LLM, offrendo uno sguardo sui meccanismi sfumati dell’assistenza dell’intelligenza artificiale.
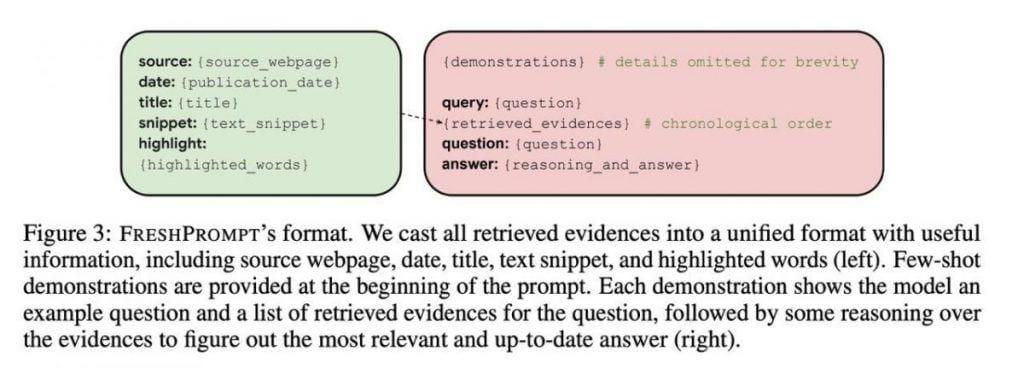
Il fondamento di questa rivelazione è stato stabilito attraverso un'attenta e tempestiva strutturazione. Questo metodo è costituito da più componenti, offrendo un percorso chiaro per ottenere risposte precise, saldamente ancorate alla comprensione contestuale. L'aspetto iniziale include esempi illustrativi, che fungono da indicatori guida, indirizzando gli LLM verso la risposta corretta sulla base di indizi contestuali.
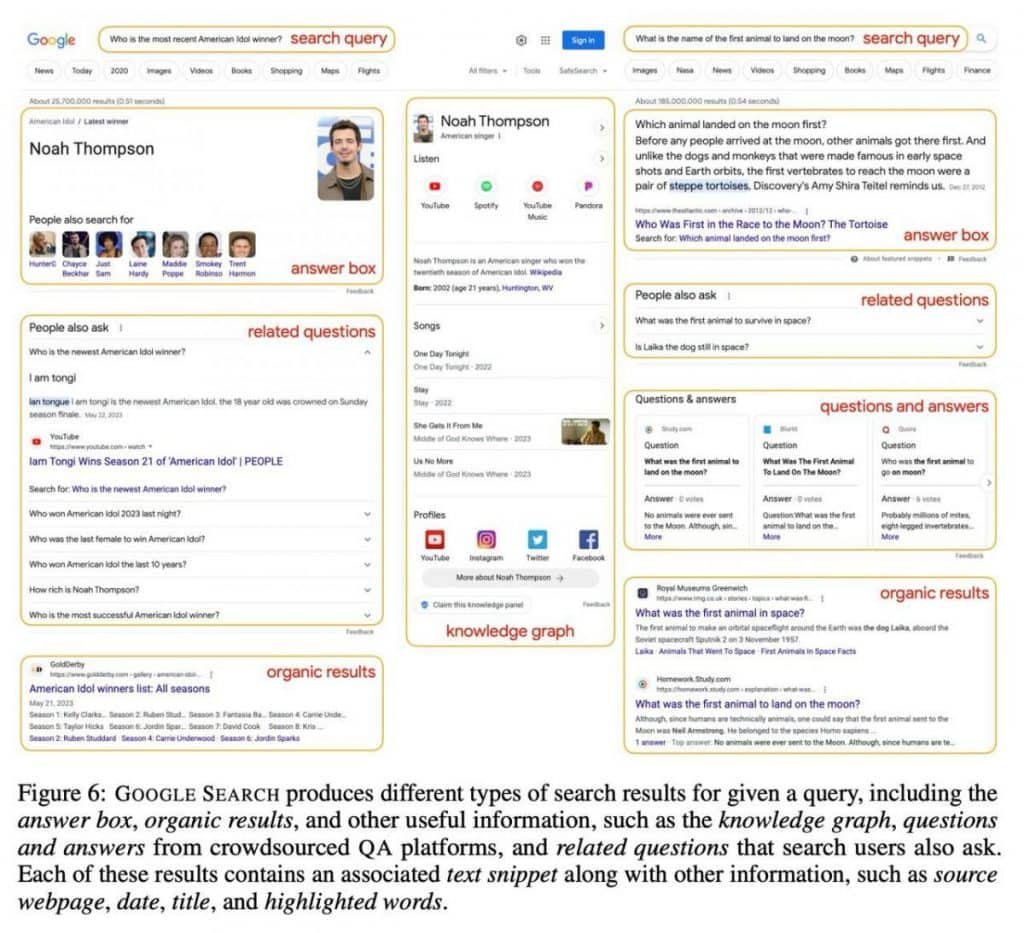
il secondo livello rivela la query effettiva insieme a 10-15 risultati di ricerca. Questi risultati vanno oltre i semplici collegamenti alle pagine Web e comprendono una vasta gamma di informazioni, inclusi contenuti testuali, query pertinenti, domande, risposte e grafici della conoscenza. Questo approccio dota l’IA di una libreria di conoscenze completa.
La sofisticazione di questo sistema va oltre. Una scoperta cruciale è emersa nel disporre i collegamenti in ordine cronologico all'interno del prompt, ponendo alla fine le aggiunte più recenti. Questa disposizione cronologica rispecchia la natura in evoluzione delle informazioni, consentendo al modello di discernere la sequenza temporale dei cambiamenti. L'inclusione delle date in ciascun esempio ha svolto un ruolo fondamentale nel migliorare la comprensione contestuale.
Sebbene il codice per utilizzare questa strutturazione dei prompt ricca di sfumature sia atteso con impazienza, la sua assenza ha spinto gli appassionati a avventurarsi nella riscrittura dei modelli di prompt basati sulle immagini fornite.
Da questa incursione nella meccanica dei suggerimenti dell’IA emergono diversi aspetti chiave:
1) PPLX.AI, una piattaforma che sfrutta ChatGPT per aggregare le risposte di Google, è emersa come un'opzione promettente. Anche i dipendenti di Google hanno accennato alla sua superiorità.
2) La sperimentazione con vari elementi ha prodotto miglioramenti nelle metriche di risposta. La precisione nella costruzione rapida, a quanto pare, è un'arte a sé stante.
3) GPT-4 dimostra una lodevole competenza nell'elaborazione di vasti insiemi di notizie e testi. Anche se potrebbe non essere definito “eccellente”, la sua qualità, anche in scenari di notizie in rapido cambiamento, si aggira intorno al 60%. La comunità dell’intelligenza artificiale è incoraggiata a valutare criticamente tali parametri.
4) Mentre l’ecosistema dell’intelligenza artificiale continua ad espandersi, gli LLM integrati nei motori di ricerca sono pronti a diventare onnipresenti, soddisfacendo un ampio spettro di utenti. La presenza dell’intelligenza artificiale nelle esperienze di ricerca quotidiane è in una traiettoria ascendente, a significare un cambiamento trasformativo nel modo in cui si accede e si elaborano le informazioni.
L'approccio multiforme offre un modo promettente per ottenere risposte accurate da questi modelli linguistici sofisticati perché include esempi illustrativi, una query chiaramente definita e una ricchezza di informazioni contestuali. La disposizione cronologica dei collegamenti all'interno dei suggerimenti ha portato ad un'intuizione significativa, sottolineando l'importanza di adattarsi alla natura dinamica delle informazioni. Gli LLM possono navigare nella sequenza temporale dei cambiamenti grazie a questa consapevolezza temporale, che migliora la loro comprensione contestuale.
Il post L'analisi di Google rivela approfondimenti sorprendenti sugli LLM e sull'accuratezza dei motori di ricerca è apparso per la prima volta su Metaverse Post.