
Kesimpulan Utama
Di Binance, kami menggunakan pembelajaran mesin (ML) untuk menyelesaikan berbagai masalah bisnis, termasuk namun tidak terbatas pada penipuan pengambilalihan akun (ATO), penipuan P2P, dan detail pembayaran yang dicuri.
Dengan menggunakan operasi pembelajaran mesin (MLOps), data scientist Binance Risk AI kami telah membangun pipeline ML end-to-end real-time yang terus menghadirkan layanan ML siap produksi.

Mengapa kami menggunakan MLOps?
Sebagai permulaan, membuat layanan ML adalah proses yang berulang. Ilmuwan data terus bereksperimen untuk meningkatkan metrik tertentu, baik offline maupun online, berdasarkan tujuan memberikan nilai bagi bisnis. Jadi bagaimana kita bisa membuat proses ini menjadi lebih efisien — misalnya, mempersingkat waktu pemasaran model ML?
Kedua, perilaku layanan ML dipengaruhi tidak hanya oleh kode yang kami, sebagai pengembang, tetapkan, tetapi juga oleh data yang dikumpulkannya. Ide yang dikenal juga sebagai penyimpangan konsep ini ditekankan dalam makalah Google yang berjudul Hutang Teknis Tersembunyi dalam Sistem Pembelajaran Mesin.
Ambil contoh penipuan; penipu bukan hanya sekedar mesin tetapi manusia yang beradaptasi dan terus-menerus mengubah cara mereka menyerang. Dengan demikian, distribusi data yang mendasarinya akan berevolusi untuk mencerminkan perubahan vektor serangan. Bagaimana kita dapat memastikan model produksi secara efektif mempertimbangkan pola data terbaru?
Untuk mengatasi tantangan yang disebutkan di atas, kami menggunakan konsep yang disebut MLOps, istilah yang pertama kali diusulkan oleh Google pada tahun 2018. Dalam MLOps, kami fokus pada performa model dan infrastruktur yang mendukung sistem produksi. Hal ini memungkinkan kami membangun layanan ML yang skalabel, ketersediaan tinggi, andal, dan mudah dikelola.
Menguraikan Pipeline ML End-to-end Real-time Kami
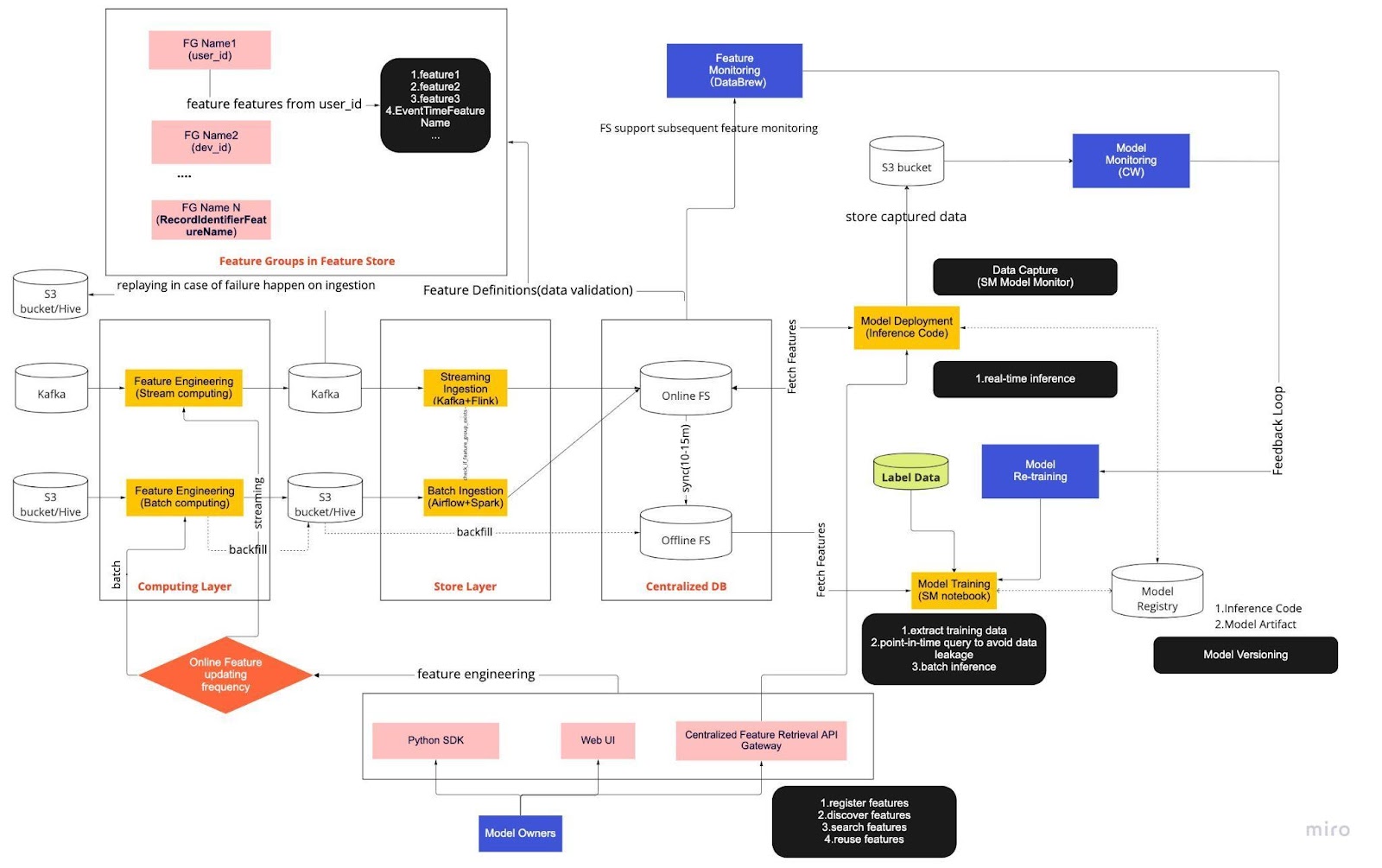
Bayangkan diagram di atas sebagai prosedur operasi standar (SOP) kami untuk pengembangan model waktu nyata dengan penyimpanan fitur. Pipeline ML end-to-end menentukan bagaimana tim kami menerapkan MLops, dan pipeline ini dibuat dengan dua jenis persyaratan: fungsional dan non-fungsional.
Fungsional
Pengolahan data
Pelatihan Model
Pengembangan Model
Penerapan Model
Pemantauan
Persyaratan non-fungsional
Dapat diskalakan
Sangat tersedia
Dapat diandalkan
Dapat dipelihara
Jalur pipa ini selanjutnya dibagi menjadi enam komponen utama:
Lapisan komputasi
Lapisan Toko
DB terpusat
Pelatihan Model
Penerapan Model
Pemantauan Model
1. Lapisan Komputasi

Lapisan komputasi terutama bertanggung jawab atas rekayasa fitur, proses mengubah data mentah menjadi fitur yang berguna.
Kami mengkategorikan lapisan komputasi menjadi dua jenis berdasarkan frekuensi pembaruannya: komputasi aliran untuk interval satu menit/detik dan komputasi batch untuk interval harian/jam.
Data masukan lapisan komputasi umumnya berasal dari database berbasis peristiwa, yang mencakup Apache Kafka dan Kinesis, atau database OLAP, yang mencakup Apache Hive untuk sumber terbuka dan Snowflake untuk solusi cloud.
2. Lapisan Penyimpanan
Lapisan penyimpanan adalah tempat kami mendaftarkan definisi fitur dan menerapkannya ke penyimpanan fitur serta melakukan pengisian ulang, sebuah proses yang memungkinkan kami membangun kembali fitur melalui data historis setiap kali fitur baru ditentukan. Pengisian ulang biasanya merupakan pekerjaan satu kali yang dapat dilakukan ilmuwan data kami di lingkungan buku catatan. Karena Kafka hanya dapat menyimpan kejadian dari tujuh hari terakhir, Kafka menggunakan mekanisme cadangan ke dalam tabel s3/hive untuk meningkatkan toleransi kesalahan.
Anda akan melihat lapisan perantara, Hive dan Kafka, sengaja ditempatkan di antara lapisan komputasi dan penyimpanan. Bayangkan penempatan ini sebagai penyangga antara fitur komputasi dan penulisan. Analoginya adalah memisahkan produsen dari konsumen. Komputasi aliran adalah produsennya, sedangkan penyerapan aliran adalah konsumennya.
Memisahkan komputasi dan penyerapan memberikan berbagai manfaat untuk pipeline ML kami. Sebagai permulaan, kita dapat meningkatkan ketahanan pipa jika terjadi kegagalan. Ilmuwan data kami masih dapat mengambil nilai fitur dari database terpusat, meskipun lapisan penyerapan atau komputasi tidak tersedia karena masalah operasional, perangkat keras, atau jaringan.
Selain itu, kami dapat mengukur berbagai bagian infrastruktur secara individual dan mengurangi energi yang dibutuhkan untuk membangun dan mengoperasikan jalur pipa. Misalnya, jika gagal karena alasan apa pun, lapisan penyerapan tidak akan memblokir lapisan komputasi. Dalam hal inovasi, kami dapat bereksperimen dan mengadopsi teknologi baru, seperti versi baru aplikasi Flink, tanpa memengaruhi infrastruktur kami yang sudah ada.

Baik lapisan komputasi maupun lapisan penyimpanan adalah apa yang kami sebut saluran fitur otomatis. Pipeline ini bersifat independen, berjalan pada jadwal yang bervariasi, dan dikategorikan sebagai pipeline streaming atau batch. Berikut cara kerja kedua alur secara berbeda: satu grup fitur dalam alur batch mungkin diperbarui setiap malam sementara grup lainnya diperbarui setiap jam. Dalam pipeline streaming, grup fitur diperbarui secara real-time saat data sumber tiba pada aliran input, seperti topik Apache Kafka.
3. DB Terpusat
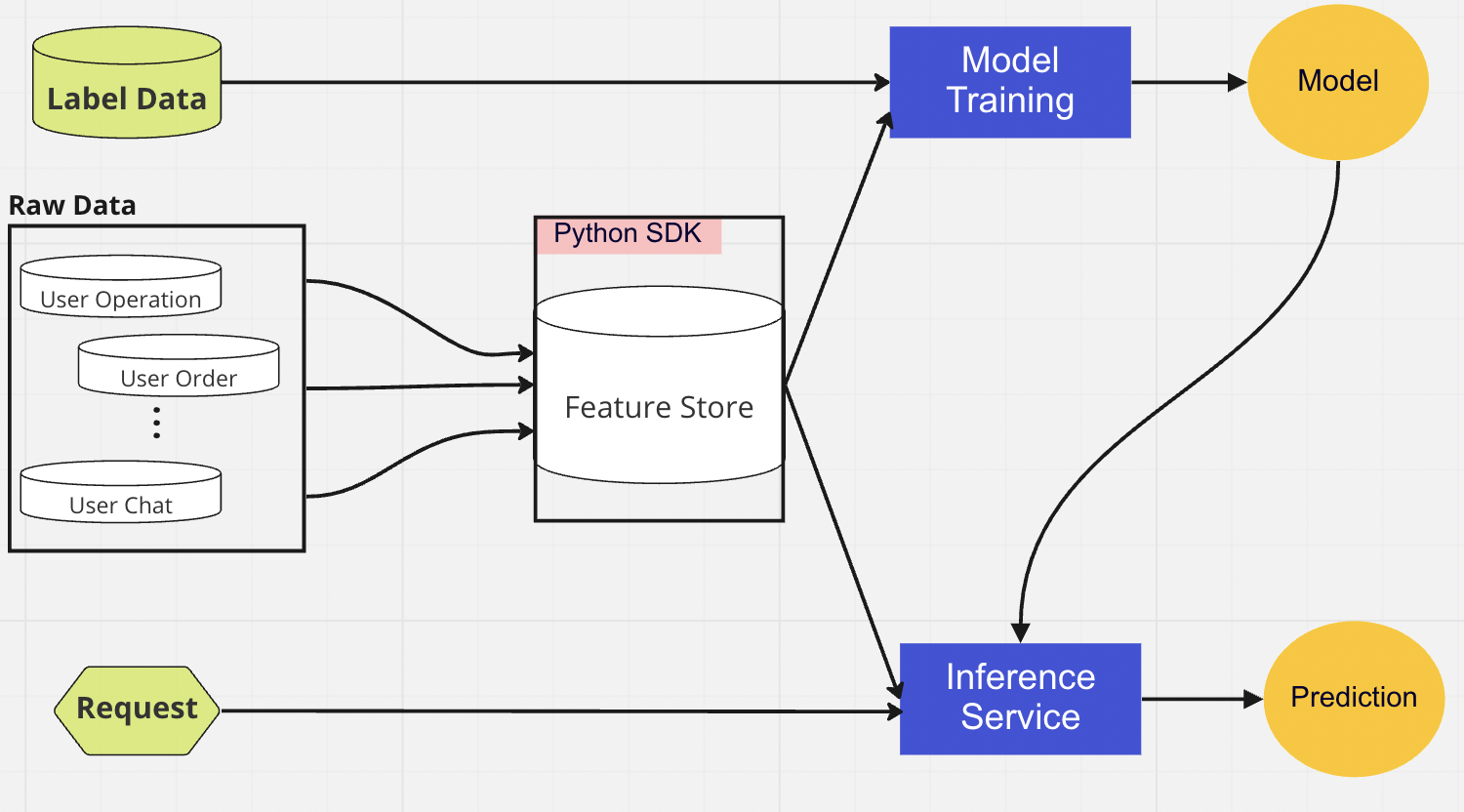
Lapisan DB terpusat adalah tempat ilmuwan data kami menyajikan data siap fitur mereka ke dalam penyimpanan fitur online atau offline.
Penyimpanan fitur online adalah penyimpanan latensi rendah dan ketersediaan tinggi yang memungkinkan pencarian data secara real-time. Di sisi lain, penyimpanan fitur offline menyediakan penyimpanan semua data fitur yang aman dan skalabel. Hal ini memungkinkan para ilmuwan untuk membuat kumpulan data pelatihan, validasi, atau penilaian batch dari sekumpulan grup fitur yang dikelola secara terpusat dengan catatan historis lengkap nilai fitur dalam sistem penyimpanan objek.
Kedua penyimpanan fitur secara otomatis melakukan sinkronisasi satu sama lain setiap 10-15 menit untuk menghindari distorsi penyajian pelatihan. Di artikel mendatang, kami akan mendalami cara kami menggunakan penyimpanan fitur di dalam pipeline.
4. Pelatihan Model
Lapisan pelatihan model adalah tempat ilmuwan kami mengekstrak data pelatihan dari penyimpanan fitur offline untuk menyempurnakan layanan ML kami. Kami menggunakan kueri titik waktu untuk mencegah kebocoran data selama proses ekstraksi.
Selain itu, lapisan ini mencakup komponen penting yang dikenal sebagai putaran umpan balik pelatihan ulang model. Pelatihan ulang model meminimalkan risiko penyimpangan konsep dengan memastikan model yang diterapkan secara akurat mewakili pola data terbaru — misalnya, peretas mengubah perilaku serangannya.
5. Penerapan Model
Untuk penerapan model, kami terutama menggunakan layanan penilaian berbasis cloud sebagai tulang punggung penyajian data real-time kami. Berikut diagram yang menunjukkan bagaimana kode inferensi saat ini terintegrasi dengan penyimpanan fitur.

6. Pemantauan Model
Di lapisan ini, tim kami memantau metrik penggunaan untuk layanan penilaian seperti QPS, latensi, memori, dan tingkat pemanfaatan CPU/GPU. Selain metrik dasar ini, kami menggunakan data yang diambil untuk memeriksa distribusi fitur dari waktu ke waktu, kemiringan penyajian pelatihan, dan penyimpangan prediksi untuk memastikan penyimpangan konsep yang minimal.
Menutup Pikiran
Singkatnya, membagi infrastruktur saluran pipa kami menjadi lapisan komputasi, lapisan penyimpanan, dan DB terpusat memberi kita tiga manfaat utama dibandingkan arsitektur yang digabungkan secara lebih erat.
Jaringan pipa yang lebih kuat jika terjadi kegagalan
Peningkatan fleksibilitas dalam memilih alat mana yang akan diterapkan
Komponen yang dapat diskalakan secara independen
Tertarik menggunakan ML untuk melindungi ekosistem kripto terbesar di dunia dan penggunanya? Lihat Binance Engineering/AI di halaman karir kami untuk lowongan pekerjaan terbuka.