
Stability AI telah merilis makalah baru di blognya tentang Stable Diffusion 2. Di dalamnya, Stability AI mengusulkan algoritma baru yang lebih efisien dan kuat dari yang sebelumnya sambil membandingkannya dengan metode canggih lainnya.

Model Stable Diffusion V1 asli CompVis merevolusi sifat model AI sumber terbuka dan menghasilkan ratusan model dan kemajuan berbeda di seluruh dunia. Program ini merupakan salah satu program tercepat yang mencapai 10.000 bintang di Github, mencapai 33.000 bintang dalam waktu kurang dari dua bulan, lebih cepat dibandingkan program lainnya di Github.
Rilisan Stable Diffusion V1 asli dipimpin oleh tim dinamis Robin Rombach (Stability AI) dan Patrick Esser (Runway ML) dari CompVis Group di LMU Munich, dipimpin oleh Prof. Mereka mengembangkan pekerjaan laboratorium sebelumnya dengan Model Difusi Laten dan menerima dukungan penting dari LAION dan Eleuther AI.

 Apa yang membedakan Difusi Stabil v1 dengan Difusi Stabil v2?
Apa yang membedakan Difusi Stabil v1 dengan Difusi Stabil v2?
Difusi Stabil 2.0 menyertakan sejumlah peningkatan dan fitur signifikan dibandingkan versi sebelumnya, jadi mari kita lihat.
Rilis Stable Diffusion 2.0 menampilkan model teks-ke-gambar tangguh yang dilatih dengan encoder teks baru (OpenCLIP) yang dikembangkan oleh LAION dengan bantuan Stability AI, yang secara signifikan meningkatkan kualitas gambar yang dihasilkan dibandingkan rilis V1 sebelumnya. Model text-to-image rilis ini dapat menghasilkan gambar dengan resolusi default 512×512 piksel dan 768×768 piksel.
Model-model ini dilatih menggunakan subset estetika dari kumpulan data LAION-5B yang dihasilkan oleh tim DeepFloyd Stability AI, yang kemudian difilter untuk mengecualikan konten dewasa menggunakan filter NSFW LAION.
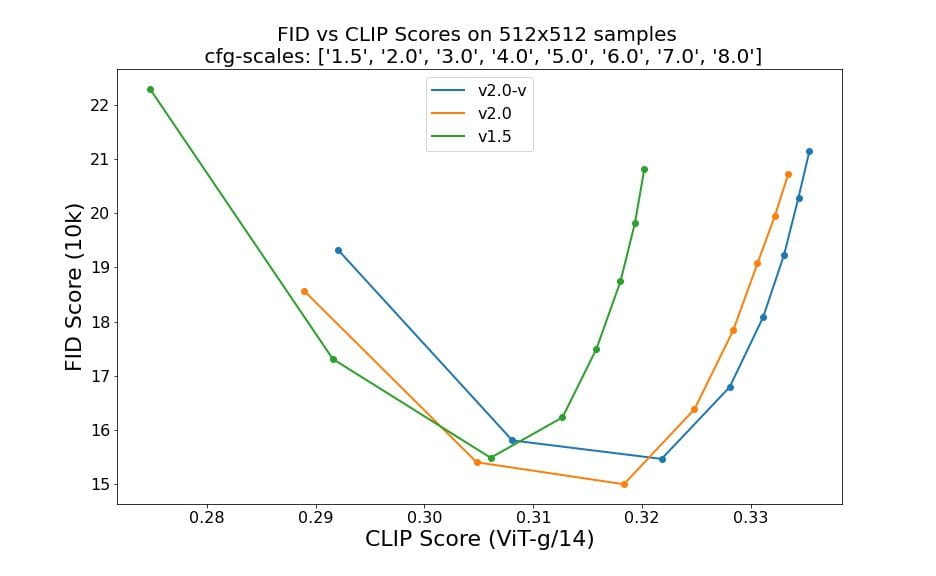
Evaluasi menggunakan 50 langkah sampel DDIM, 50 skala panduan bebas pengklasifikasi, dan 1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, dan 8.0 menunjukkan peningkatan relatif pada pos pemeriksaan:
Difusi Stabil 2.0 kini menggunakan model Difusi Upscaler, yang meningkatkan resolusi gambar sebanyak empat kali lipat. Contoh model kami yang meningkatkan gambar yang dihasilkan berkualitas rendah (128×128) menjadi gambar beresolusi lebih tinggi ditunjukkan di bawah (512×512). Difusi Stabil 2.0, bila digabungkan dengan model teks-ke-gambar kami, kini dapat menghasilkan gambar dengan resolusi 2048×2048 atau lebih tinggi.

Model difusi stabil yang dipandu kedalaman baru, depth2img, memperluas fitur gambar-ke-gambar sebelumnya dari V1 dengan kemungkinan kreatif yang sepenuhnya baru. Depth2img menentukan kedalaman gambar masukan (menggunakan model yang sudah ada) dan kemudian menghasilkan gambar baru berdasarkan teks dan informasi kedalaman. Depth-to-Image dapat menyediakan sejumlah besar aplikasi kreatif baru, menawarkan perubahan yang tampak sangat berbeda dari aslinya, namun tetap mempertahankan koherensi dan kedalaman gambar.
Apa yang baru di Difusi Stabil 2?
Model difusi stabil baru menawarkan resolusi 768x768.
U-Net memiliki jumlah parameter yang sama dengan versi 1.5, tetapi dilatih dari awal dan menggunakan OpenCLIP-ViT/H sebagai encoder teksnya. Model prediksi v yang disebut adalah SD 2.0-v.
Model yang disebutkan di atas telah disesuaikan dari basis SD 2.0, yang juga tersedia dan dilatih sebagai model prediksi noise pada gambar 512x512.
Model difusi terpandu teks laten dengan penskalaan x4 telah ditambahkan.
Model difusi stabil dengan panduan kedalaman dasar SD 2.0 yang disempurnakan. Model ini dapat digunakan untuk img2img yang mempertahankan struktur dan sintesis kondisional bentuk dan dikondisikan pada perkiraan kedalaman monokuler yang disimpulkan oleh MiDaS.
Model inpainting berpandu teks yang ditingkatkan yang dibangun di atas fondasi SD 2.0.
Pengembang bekerja keras, seperti iterasi awal Difusi Stabil, untuk mengoptimalkan model agar berjalan pada satu GPU—mereka ingin membuatnya dapat diakses oleh sebanyak mungkin orang sejak awal. Mereka telah melihat apa yang terjadi ketika jutaan orang mendapatkan model-model ini dan berkolaborasi untuk menciptakan hal-hal yang benar-benar luar biasa. Inilah kekuatan open source: memanfaatkan potensi besar dari jutaan orang berbakat yang mungkin tidak memiliki sumber daya untuk melatih model mutakhir namun memiliki kemampuan untuk melakukan hal-hal luar biasa dengan model tersebut.

Pembaruan baru ini, dikombinasikan dengan fitur-fitur baru yang canggih seperti depth2img dan kemampuan peningkatan resolusi yang lebih baik, akan menjadi landasan bagi sejumlah besar aplikasi baru dan memungkinkan ledakan potensi kreatif baru.
Baca lebih lanjut tentang Difusi Stabil:
AI Difusi Stabil Menciptakan Dunia Impian untuk VR dan Metaverse
Sang seniman menggunakan Difusi Stabil untuk memproduksi film animasi AI penuh pertama
Perkenalkan inpainting video: pengeditan berbasis teks dengan Difusi Stabil dan Atlas Neural
Pos Algoritma Difusi Stabil 2 Stabilitas AI Akhirnya Publik: model depth2img baru, peningkatan resolusi super, tidak ada konten dewasa muncul pertama kali di Metaverse Post.