Pagi ini, saya sedang merapikan catatan lama tentang model AI yang pernah ramai dibicarakan, dan perasaan yang familiar muncul kembali, bahwa hal-hal yang paling dipuji pasar sering kali bukanlah hal-hal yang dipahami secara mendalam. Di sinilah Openledger menarik perhatian saya, bukan karena ia berbicara lebih keras daripada yang lain, tetapi karena ia menargetkan masalah yang lebih kecil, lebih sulit, dan lebih nyata, bagaimana kantong-kantong pengetahuan yang sangat khusus, padat dengan konteks, masih bisa memiliki tempatnya sendiri alih-alih menghilang ke dalam massa pemahaman yang rata.
Apa yang membuat saya bertahan lebih lama ada di Datanets. Banyak proyek berbicara tentang data dalam istilah yang sangat luas, seolah-olah mengumpulkan cukup banyak sudah cukup. Cara berpikir seperti itu bekerja di permukaan, tetapi melewatkan sifat pengetahuan niche, di mana akurasi tidak datang dari skala, tetapi dari struktur, konteks, dan pelabelan. Openledger pergi ke arah lain dengan mencoba mempertahankan batasan data, dengan asal usul, kontributor, kondisi penggunaan, dan cap waktu yang utuh. Pengetahuan sempit biasanya tidak menghilang karena kurangnya nilai, itu menghilang karena terlalu cepat terlarut.
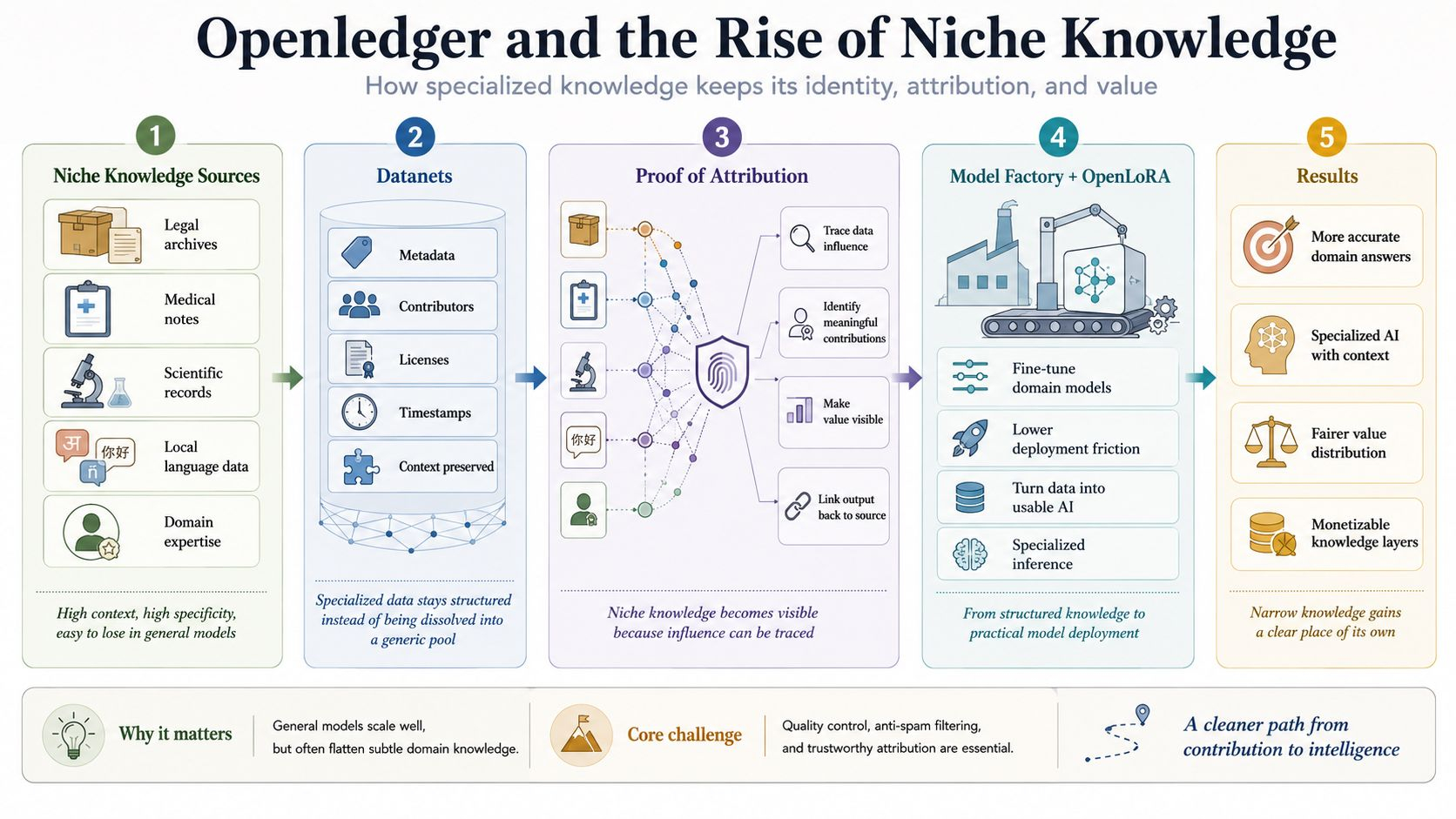
Itulah sebabnya proyek ini tidak bisa dibaca hanya sebagai tempat yang mengumpulkan data dan kemudian memberikannya ke dalam pelatihan model. Apa yang jauh lebih penting adalah bahwa Openledger berusaha mengubah data khusus menjadi lapisan yang memiliki hak untuk ada. Setelah data diorganisir sebagai unit yang dapat diperhitungkan, pertanyaan kontribusi tidak lagi berada pada tingkat etika, tetapi bergerak ke level arsitektur. Saya telah melalui cukup banyak siklus untuk melihat bahwa pasar selalu lebih suka berbicara tentang model atau produk akhir, sementara bagian yang benar-benar menciptakan presisi didorong kembali ke dalam kegelapan.
Itulah tepatnya mengapa Proof of Attribution adalah bagian yang paling saya timbang. Banyak orang mendengar istilah itu dan menganggapnya hanya sebagai lapisan tambahan untuk membuat cerita terdengar lebih baik, tetapi sebenarnya inilah tempat Openledger bertaruh pada perubahan terberat, melacak dataset mana yang mempengaruhi output dan kontribusi mana yang membawa bobot nyata. Siapa pun yang telah membangun sistem data mungkin memahami ini, melacak pengaruh tidak pernah mudah, terutama ketika output dibuat melalui beberapa lapisan pemrosesan yang ditumpuk. Tetapi kesulitan itulah yang memberi nilai.
Melangkah lebih jauh, saya pikir ide ini hanya berdiri jika atribusi tidak terpisah dari penerapan model. Di situlah Model Factory dan OpenLoRA masuk sebagai dua bagian yang tidak dapat diperlakukan sebagai sekunder. Openledger tidak hanya ingin mempertahankan jejak pengetahuan khusus, tetapi juga ingin membuka jalur bagi data tersebut untuk bergerak ke dalam model yang disesuaikan dan kemudian ke operasi nyata tanpa mati di tengah jalan karena biayanya terlalu tinggi atau prosesnya terlalu berat. Banyak ide yang benar gagal hanya karena jarak dari data ke aplikasi lebih panjang daripada daya tahan seorang pembangun.
Saya tidak melihat cerita ini dengan kelemahan juga. Setiap sistem yang mengaitkan imbalan dengan pengaruh data pada akhirnya akan menghadapi sisi gelap dari insentif. Orang-orang dapat membanjiri dengan lebih banyak data hanya untuk masuk ke dalam rantai atribusi. Mereka juga bisa belajar mengoptimalkan untuk dianggap berpengaruh alih-alih benar-benar meningkatkan akurasi. Untuk alasan itu, Openledger membutuhkan lebih dari sekadar ide yang benar, ia memerlukan disiplin yang sangat ketat dalam penyaringan dan pemilihan. Jujur, di sinilah banyak proyek akhirnya mengungkapkan sifat asli mereka.
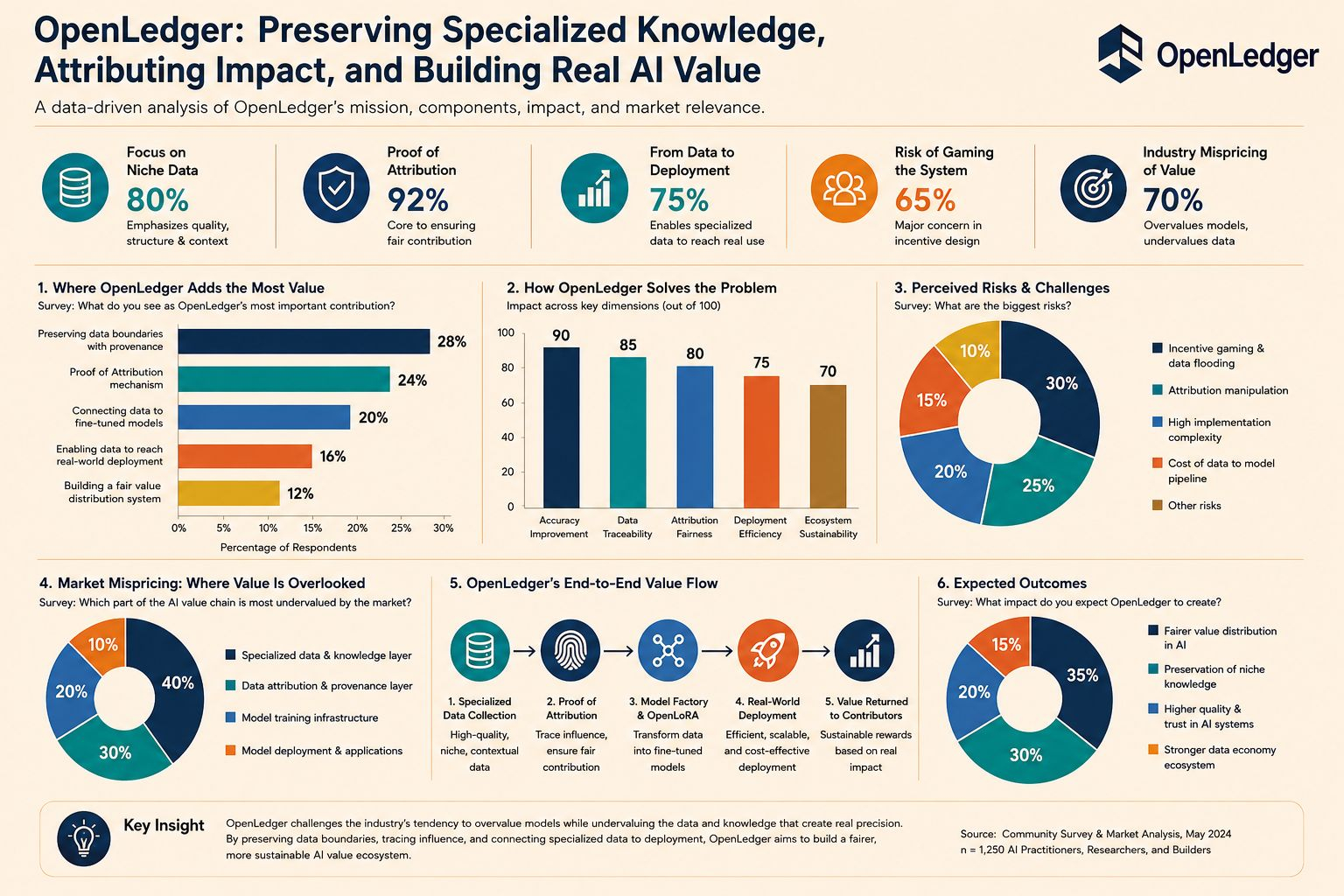
Apa yang membuat saya menghargai usaha ini adalah bahwa itu bergerak melawan naluri industri yang sudah dikenal. Alih-alih membangun satu lapisan model lainnya yang mengklaim memahami segalanya, Openledger secara implisit mengakui bahwa ada domain pengetahuan yang seharusnya tidak dipaksakan ke dalam logika rata-rata. Keahlian mendalam di bidang sempit tidak perlu dibesar-besarkan menjadi narasi besar, itu membutuhkan saluran yang cukup bersih untuk mempertahankan konteks dan kontribusi yang menghasilkan akurasi. Itu adalah perbedaan sikap, bukan hanya pilihan teknis.
Apa yang saya temukan paling layak dipikirkan setelah melihat dekat struktur ini adalah bahwa pasar mungkin telah salah menilai nilai dari awal, memberi imbalan lapisan agregasi akhir dengan dermawan sementara meremehkan lapisan pengetahuan yang tenang yang menciptakan presisi. Ketika sebuah sistem mencoba mempertahankan batasan data, jejak pengaruh, menghubungkan data khusus ke model yang disesuaikan, dan membawanya ke penggunaan nyata, Openledger mencoba memperbaiki bagaimana nilai didistribusikan dalam AI dengan cara yang jauh lebih ketat. Dan jika Openledger benar-benar bisa menjaga pengetahuan sempit dari tenggelam ke dalam kabur antara kontribusi dan output, apakah pasar masih akan terus memuja kecerdasan yang luas namun dangkal sebagai standar yang cukup baik.