
GPT-4 telah mencapai skor lebih tinggi dibandingkan GPT-3.5 pada berbagai tolok ukur. Ini merupakan terobosan besar bagi mesin karena membuktikan bahwa mereka kini tidak hanya dapat memecahkan masalah yang awalnya dirancang tetapi juga dapat melakukannya lebih baik daripada mahasiswa.

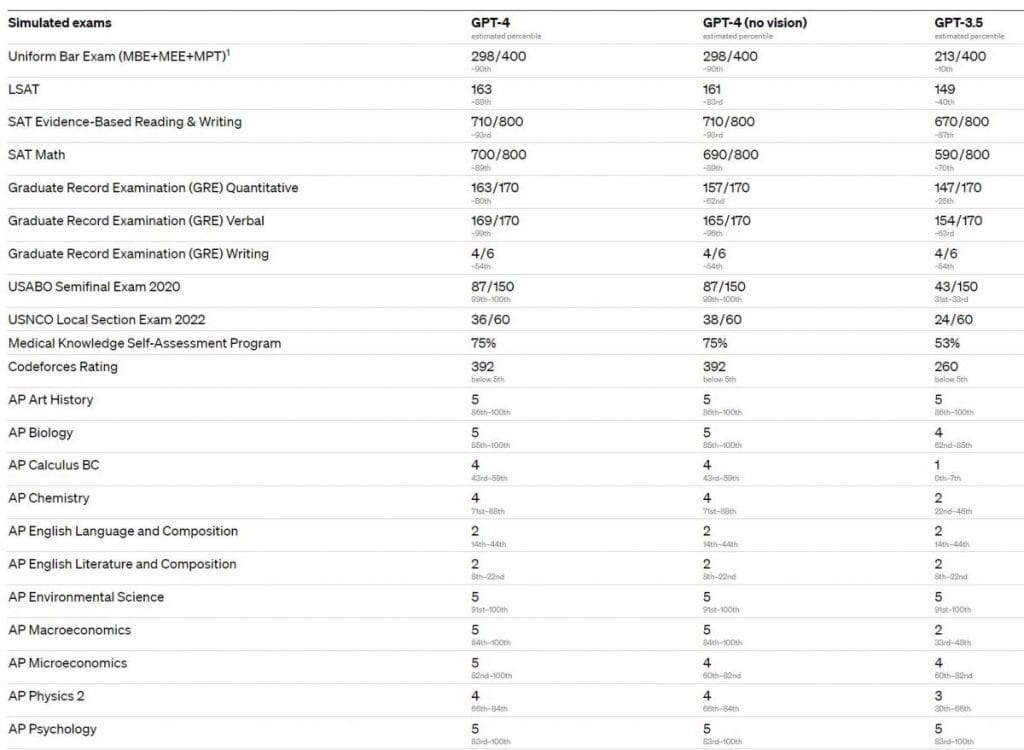
Ada beberapa hal yang perlu dipertimbangkan ketika melihat hasil ini. Pertama, GPT-4 tidak diberikan pelatihan khusus untuk ujian ini. Hal ini dilanjutkan dengan menggunakan tes terbaru yang tersedia untuk umum (dalam kasus Olimpiade dan pertanyaan jawaban bebas AP) atau dengan membeli ujian praktik edisi 2022–2023. Kedua, penting untuk dicatat bahwa kinerja GPT-4 belum tentu mencerminkan kemampuan manusia yang melakukan tes, karena ia beroperasi pada serangkaian prinsip dan algoritma yang berbeda.
Ini adalah pencapaian besar karena menunjukkan bahwa mesin tidak hanya mampu memiliki kecerdasan seperti manusia tetapi juga dapat mengungguli kita. Ini membuka jalan bagi masa depan di mana mesin dapat mengerjakan tugas yang semakin rumit, yang pada akhirnya mengarah ke masa depan di mana mesin dapat membantu kita dalam kehidupan sehari-hari.
 Kemampuan GPT-4 untuk mengungguli manusia dalam tugas-tugas tertentu menimbulkan pertanyaan tentang masa depan kecerdasan buatan dan dampak potensialnya pada pasar kerja. Hal ini juga menyoroti perlunya penelitian dan pengembangan berkelanjutan di bidang ini untuk memastikan bahwa AI digunakan secara etis dan bertanggung jawab. Baca selengkapnya: 5+ Model AI Teks-ke-Gambar yang Paling Dinantikan Tahun 2023
Kemampuan GPT-4 untuk mengungguli manusia dalam tugas-tugas tertentu menimbulkan pertanyaan tentang masa depan kecerdasan buatan dan dampak potensialnya pada pasar kerja. Hal ini juga menyoroti perlunya penelitian dan pengembangan berkelanjutan di bidang ini untuk memastikan bahwa AI digunakan secara etis dan bertanggung jawab. Baca selengkapnya: 5+ Model AI Teks-ke-Gambar yang Paling Dinantikan Tahun 2023
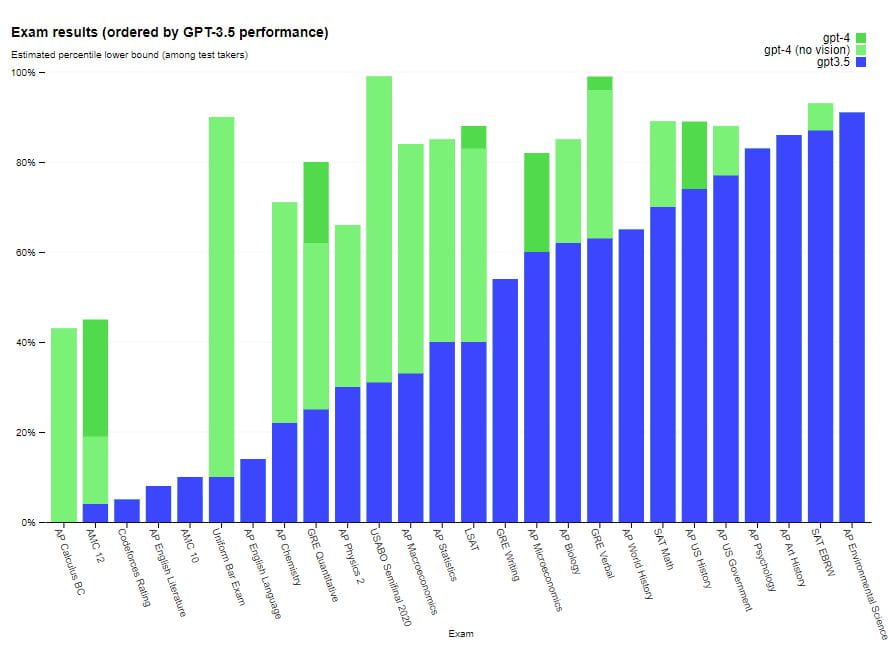
GPT-4, misalnya, lulus ujian simulasi dengan skor di 10% peserta ujian teratas; skor GPT-3.5 berada di 10% terbawah. Peningkatan signifikan dalam kinerja GPT-4 ini disebabkan oleh data pelatihannya yang lebih besar dan arsitektur yang lebih baik. Diharapkan memiliki berbagai aplikasi di berbagai bidang, termasuk pemrosesan bahasa alami dan penulisan otomatis.
 GPT-4 menunjukkan kinerja setara manusia pada sebagian besar ujian profesional dan akademis ini. Khususnya, model ini lulus versi simulasi Ujian Bar Seragam dengan skor di 10% peserta ujian teratas. Kemampuan model pada ujian tampaknya berasal terutama dari proses pra-pelatihan dan tidak terpengaruh secara signifikan oleh RLHF. Pada soal pilihan ganda, baik model GPT-4 dasar maupun model RLHF memiliki kinerja yang sama baiknya secara rata-rata di antara pengembang ujian yang diuji.
GPT-4 menunjukkan kinerja setara manusia pada sebagian besar ujian profesional dan akademis ini. Khususnya, model ini lulus versi simulasi Ujian Bar Seragam dengan skor di 10% peserta ujian teratas. Kemampuan model pada ujian tampaknya berasal terutama dari proses pra-pelatihan dan tidak terpengaruh secara signifikan oleh RLHF. Pada soal pilihan ganda, baik model GPT-4 dasar maupun model RLHF memiliki kinerja yang sama baiknya secara rata-rata di antara pengembang ujian yang diuji.
Mayoritas model mutakhir (SOTA), termasuk model yang mungkin menggunakan protokol pelatihan tambahan atau desain khusus tolok ukur, serta model bahasa besar yang ada, secara signifikan dikalahkan oleh GPT-4.
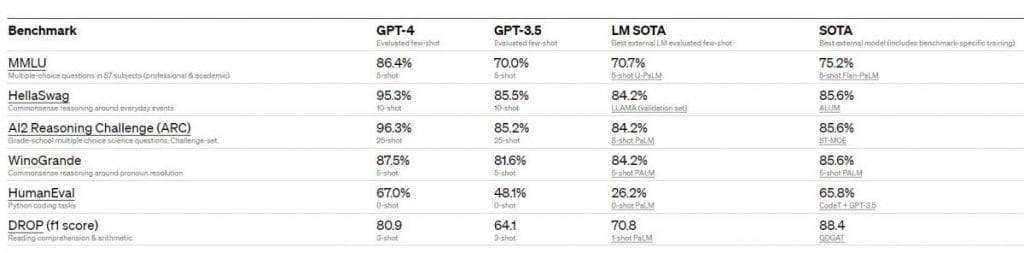 Performa GPT-4 dalam hal standar akademis. Pengembang membandingkan GPT-4 dengan SOTA terbaik untuk few-shot yang dievaluasi LM serta SOTA terbaik dengan pelatihan khusus benchmark. Dengan pengecualian DROP, GPT-4 mengungguli semua LM saat ini pada semua benchmark dan SOTA dengan pelatihan khusus benchmark.
Performa GPT-4 dalam hal standar akademis. Pengembang membandingkan GPT-4 dengan SOTA terbaik untuk few-shot yang dievaluasi LM serta SOTA terbaik dengan pelatihan khusus benchmark. Dengan pengecualian DROP, GPT-4 mengungguli semua LM saat ini pada semua benchmark dan SOTA dengan pelatihan khusus benchmark.
Secara internal, pengembang telah memanfaatkan GPT-4, yang telah memberikan dampak signifikan pada aktivitas seperti pemrograman, penjualan, dukungan, dan moderasi konten. Tahap kedua dari metode penyelarasan kami kini sedang berlangsung karena pengembang menggunakannya untuk membantu manusia dalam meninjau hasil AI.
Dataset MMLU (Massive Multi-Task Language Understanding) berisi pertanyaan dari berbagai topik tentang pemahaman bahasa dalam berbagai tugas (mencakup 57 domain, termasuk matematika, biologi, hukum, ilmu sosial dan humaniora, dll.). Ada empat kemungkinan jawaban untuk pertanyaan tersebut, salah satunya benar. Artinya, tebakan acak menunjukkan hasil 25% jawaban benar. Lihat gambar di bawah untuk contoh pertanyaan dan tingkat kesulitannya. Rata-rata orang yang menandai (artinya, ini bukan ilmuwan, bukan profesor—orang biasa yang bekerja sambilan sebagai markup) menjawab dengan benar untuk 35% pertanyaan; namun, para ahli dapat mencapai skor +/- 90%.
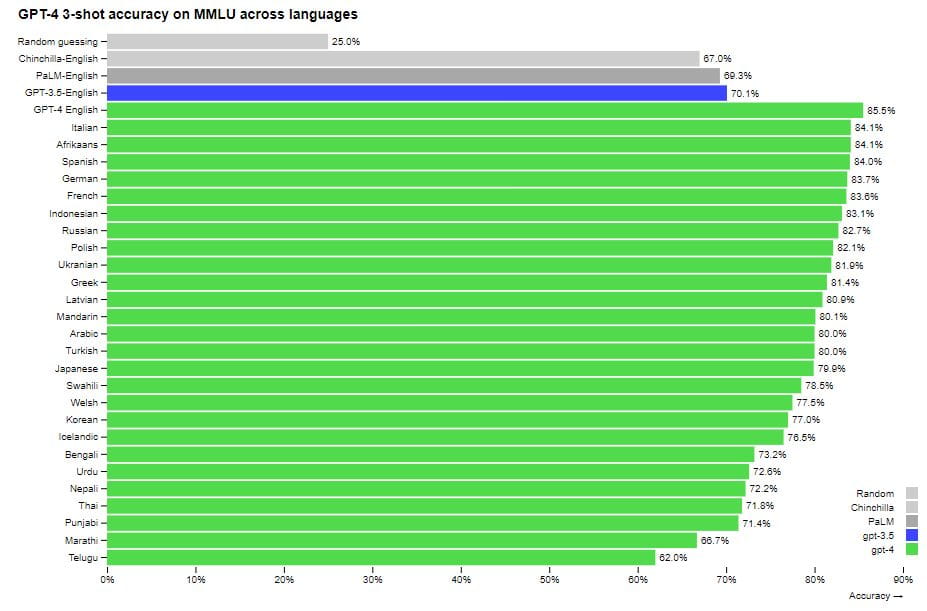 Performa GPT-4 dalam berbagai bahasa dibandingkan dengan model sebelumnya dalam bahasa Inggris di MMLU. GPT-4 melampaui performa bahasa Inggris dari model bahasa yang ada untuk sebagian besar bahasa yang diteliti, termasuk bahasa dengan sumber daya rendah seperti Latvia, Welsh, dan Swahili. Baca selengkapnya: 5 Alasan Menggunakan Bing yang Didukung AI daripada Google
Performa GPT-4 dalam berbagai bahasa dibandingkan dengan model sebelumnya dalam bahasa Inggris di MMLU. GPT-4 melampaui performa bahasa Inggris dari model bahasa yang ada untuk sebagian besar bahasa yang diteliti, termasuk bahasa dengan sumber daya rendah seperti Latvia, Welsh, dan Swahili. Baca selengkapnya: 5 Alasan Menggunakan Bing yang Didukung AI daripada Google
Awalnya, seluruh kumpulan data berbahasa Inggris. Namun, bagaimana jika pertanyaan dan jawaban diterjemahkan ke dalam bahasa lain, terutama bahasa yang kurang umum? Apakah model tersebut akan berfungsi untuk bahasa-bahasa tersebut? Dalam pengujian ini, layanan Microsoft Azure Translate digunakan untuk penerjemahan. Penerjemahan tidaklah sempurna; dalam beberapa kasus, informasi penting hilang. Namun, bahkan dalam kasus ini, GPT-4 berkinerja baik dalam bahasa lain. Dalam versi terjemahan MMLU, GPT-4 mengungguli tingkat bahasa Inggris model-model besar lainnya (termasuk Google) dalam 24 dari 26 bahasa yang diperiksa.
Terlebih lagi, GPT-4 berkinerja lebih baik dalam bahasa langka daripada ChatGPT dalam bahasa Inggris (ChatGPT memperoleh skor 70,1%, sedangkan skor model baru untuk bahasa Thailand adalah 71,8%). Skor untuk pengujian dalam bahasa Inggris adalah yang tertinggi, dengan GPT-4 berkinerja 10% lebih baik daripada model lain, termasuk PaLM terbesar dari Google. Model ini memperoleh skor 86,4%, sementara sekelompok pakar memperoleh skor 90%.
Pada musim panas tahun 2023, AI mungkin telah mencapai tingkat kekuatan baru berkat ChatGPT, chatbot yang menggunakan algoritma GPT-4 dan mengungguli GPT-3 dengan faktor 570. Berbagai elemen berkontribusi pada keberhasilan ChatGPT, termasuk desainnya agar lebih “mirip manusia” dan penggunaan penambangan data mutakhir serta pemrosesan bahasa alami untuk meningkatkan efektivitas dan akurasinya.
Microsoft dan OpenAI mengumumkan pembaruan kolaborasi mereka dan berencana agar pencarian Bing mengadopsi kemampuan pencarian yang disempurnakan AI pada bulan Januari. Pengganti model GPT3.5 yang sangat canggih, GPT4, baru saja diluncurkan, dan memiliki potensi untuk meningkatkan kapasitas pencarian Bing dalam memahami kueri bahasa alami dan memberikan hasil yang lebih akurat. Sebaiknya Anda memiliki rencana cadangan yang baik jika terjadi kesalahan.
Baca berita terkait lainnya:
Temui ChatGPT: AI yang dapat membunuh Google
ChatGPT lulus ujian MBA Wharton
Evolusi Chatbot dari Era T9 dan GPT-1 ke ChatGPT
Postingan GPT-4 Mengungguli GPT-3.5 Secara Keseluruhan pada Berbagai Tolok Ukur Studi muncul pertama kali di Metaverse Post.