

Kerangka Sirkuit Benchmarking menggunakan SHA-256

Kami ingin mengucapkan terima kasih kepada tim dari Polygon Zero, proyek gnark di Consensys, Pado Labs, dan Delphinus Lab atas ulasan dan masukan mereka yang berharga di blog ini.
Pantheon Bukti Pengetahuan Nol
Selama beberapa bulan terakhir, kami telah mendedikasikan banyak waktu dan upaya untuk mengembangkan infrastruktur mutakhir yang memanfaatkan bukti ringkas zk-SNARK. Sebagai bagian dari upaya pengembangan kami, kami telah menguji dan menggunakan beragam kerangka pengembangan Zero-Knowledge-Proof (ZKP). Meskipun perjalanan ini membuahkan hasil, kami menyadari bahwa banyaknya kerangka kerja ZKP yang tersedia sering kali menimbulkan tantangan bagi pengembang baru yang mencoba menemukan yang paling sesuai dengan kasus penggunaan spesifik dan persyaratan kinerja mereka. Dengan mempertimbangkan masalah ini, kami yakin diperlukan platform evaluasi komunitas yang mampu memberikan hasil tolok ukur yang komprehensif dan akan sangat membantu dalam pengembangan aplikasi baru ini.
Untuk memenuhi kebutuhan ini, kami meluncurkan Pantheon of Zero Knowledge Proof sebagai inisiatif komunitas barang publik. Langkah pertama adalah mendorong komunitas untuk berbagi hasil benchmarking yang dapat direproduksi dari berbagai kerangka ZKP. Tujuan utama kami adalah untuk secara kolektif dan kolaboratif menciptakan dan memelihara pengujian evaluasi yang diakui secara universal yang mencakup kerangka pengembangan sirkuit tingkat rendah, zkVM dan kompiler tingkat tinggi, dan bahkan penyedia akselerasi perangkat keras. Kami berharap inisiatif ini akan mempercepat penerapan ZKP dengan memfasilitasi pengambilan keputusan yang terinformasi, sekaligus mendorong evolusi dan iterasi kerangka ZKP itu sendiri dengan menyediakan serangkaian hasil tolok ukur yang dapat dijadikan referensi umum. Kami berkomitmen untuk berinvestasi dalam inisiatif ini dan mengundang semua anggota komunitas yang berpikiran sama untuk bergabung dengan kami dan berkontribusi dalam upaya ini bersama-sama!
Langkah Pertama: Membandingkan Kerangka Sirkuit menggunakan SHA-256
Dalam postingan blog ini, kami mengambil langkah pertama dalam membangun Pantheon ZKP dengan menyediakan serangkaian hasil benchmark yang dapat direproduksi menggunakan SHA-256 di berbagai kerangka pengembangan sirkuit tingkat rendah. Meskipun kami mengakui bahwa granularitas dan primitif pembandingan lainnya dimungkinkan, kami memilih SHA-256 karena penerapannya pada berbagai kasus penggunaan ZKP, termasuk sistem blockchain, tanda tangan digital, zkDID, dan banyak lagi. Perlu juga disebutkan bahwa kami juga memanfaatkan SHA-256 di sistem kami sendiri, jadi ini juga cukup nyaman bagi kami! 😂
Tolok ukur kami mengevaluasi kinerja SHA-256 pada berbagai kerangka pengembangan sirkuit zk-SNARK dan zk-STARK. Melalui perbandingan ini, kami berupaya memberikan wawasan kepada pengembang tentang efisiensi dan kepraktisan setiap kerangka kerja. Tujuan kami adalah bahwa temuan ini akan memungkinkan pengembang untuk membuat keputusan yang tepat ketika memilih kerangka kerja yang paling sesuai untuk proyek mereka.
Sistem Pembuktian
Dalam beberapa tahun terakhir, kami telah mengamati menjamurnya sistem pembuktian tanpa pengetahuan. Meskipun sulit untuk mengikuti semua kemajuan menarik di bidang ini, kami telah dengan cermat memilih sistem pembuktian berikut berdasarkan kematangan dan adopsi pengembang. Tujuan kami adalah menyajikan contoh representatif dari kombinasi frontend/backend yang berbeda.
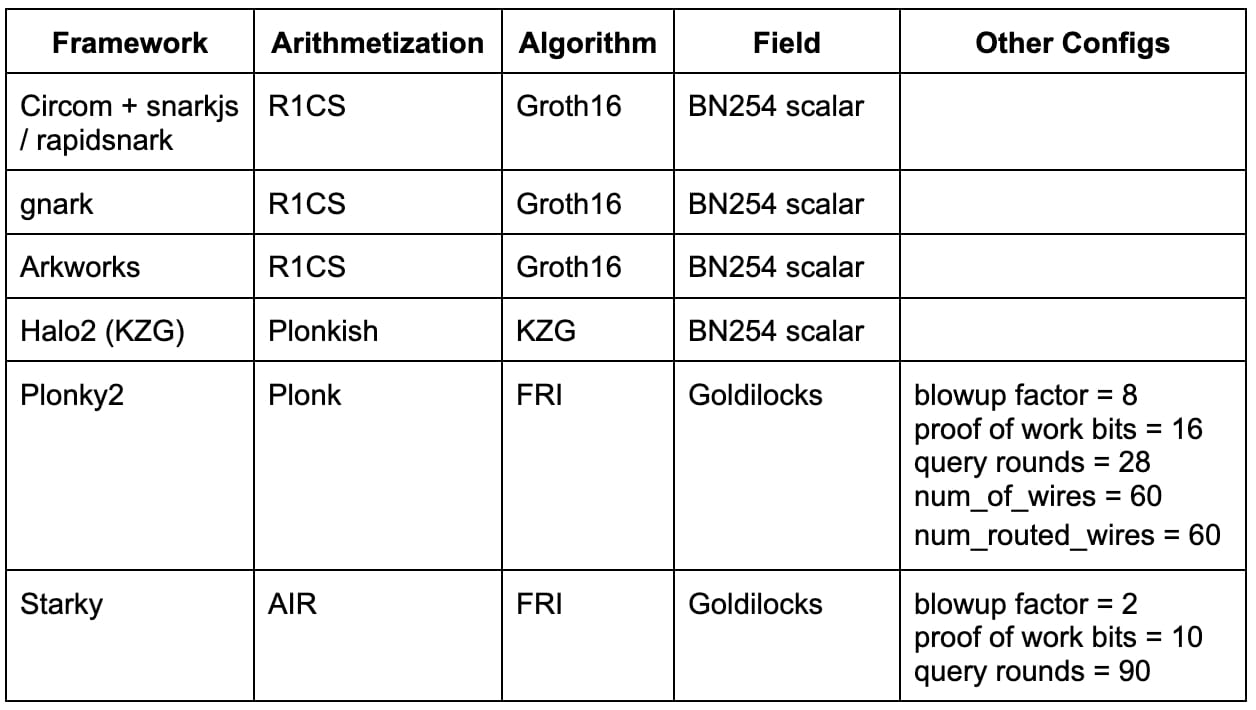
Circom + snarkjs / rapidsnark: Circom adalah DSL populer untuk menulis sirkuit dan menghasilkan batasan R1CS sementara snarkjs mampu menghasilkan bukti Groth16 atau Plonk untuk Circom. Rapidsnark juga merupakan pembuktian untuk Circom yang menghasilkan bukti Groth16 dan biasanya jauh lebih cepat daripada snarkjs karena penggunaan ekstensi ADX, yang memparalelkan pembuatan bukti sebanyak mungkin.
gnark: gnark adalah kerangka kerja Golang komprehensif dari Consensys yang mendukung Groth16, Plonk, dan banyak fitur lanjutan lainnya.
Arkworks: Arkworks adalah kerangka kerja Rust yang komprehensif untuk zk-SNARKs.
Halo2 (KZG): Halo2 adalah implementasi zk-SNARK Zcash dengan Plonk. Ia dilengkapi dengan aritmetisasi Plonkish yang sangat fleksibel yang mendukung banyak primitif yang berguna, seperti gerbang khusus dan tabel pencarian. Kami menggunakan fork Halo2 dengan dukungan KZG dari Ethereum Foundation dan Scroll.
Plonky2: Plonky2 merupakan implementasi SNARK berdasarkan teknik dari PLONK dan FRI dari Polygon Zero. Plonky2 menggunakan bidang Goldilocks kecil dan mendukung rekursi yang efisien. Dalam benchmarking, kami menargetkan keamanan dugaan 100-bit dan menggunakan parameter yang menghasilkan waktu pembuktian terbaik untuk pekerjaan benchmark. Secara khusus, kami menggunakan 28 kueri Merkle, faktor ledakan 8, dan tantangan penggilingan proof-of-work 16-bit. Selain itu, kami menetapkan num_of_wires = 60 dan num_routed_wires = 60.
Starky: Starky adalah kerangka kerja STARK berperforma tinggi dari Polygon Zero. Dalam pembandingan kami, kami menargetkan keamanan dugaan 100-bit dan menggunakan parameter yang menghasilkan waktu pembuktian terbaik. Secara khusus, kami menggunakan 90 kueri Merkle, faktor ledakan 2, dan tantangan penggilingan proof-of-work 10-bit.
Tabel di bawah ini merangkum kerangka kerja di atas dengan konfigurasi relevan yang digunakan dalam tolok ukur kami. Daftar ini tidak lengkap dan banyak kerangka kerja/teknik canggih (misalnya, Nova, GKR, Hyperplonk) yang tersisa untuk pekerjaan di masa depan.
Perlu diketahui bahwa hasil benchmark ini hanya untuk kerangka pengembangan sirkuit. Kami berencana untuk menerbitkan blog terpisah yang membandingkan zkVM yang berbeda (misalnya, Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) dan kerangka kompiler IR (misalnya, Noir, zkLLVM) di masa mendatang.
Metodologi Tolok Ukur
Untuk membandingkan berbagai sistem pembuktian ini, kami menghitung hash SHA-256 untuk N byte data, di mana kami bereksperimen dengan N = 64, 128, ..., 64K (dengan satu pengecualian adalah Starky, yang rangkaiannya mengulangi SHA-256 komputasi untuk input tetap 64-byte tetapi mempertahankan jumlah total potongan pesan yang sama). Kode benchmark dan implementasi rangkaian SHA-256 dapat ditemukan di repositori ini.
Selanjutnya, kami melakukan benchmarking pada setiap sistem menggunakan metrik kinerja berikut:
Waktu Pembuatan Bukti (termasuk waktu pembuatan saksi)
Penggunaan Memori Puncak selama pembuatan bukti
Rata-rata % Pemanfaatan CPU selama pembuatan bukti. (Metrik ini mencerminkan tingkat paralelisasi selama pembuatan bukti)
Harap dicatat bahwa kami membuat beberapa asumsi “lambaian tangan” mengenai ukuran bukti dan biaya verifikasi bukti, karena aspek-aspek ini dapat dikurangi dengan menulis dengan Groth16/KZG sebelum melakukan on-chain.
Mesin-mesin
Kami melakukan benchmarking pada dua mesin berbeda:
Server Linux: 20 Core @2,3 GHz, memori 384GB
Macbook M1 Pro: 10 Core @3.2Ghz, memori 16GB
Server Linux digunakan untuk mensimulasikan skenario dengan banyak inti CPU dan memori berlimpah. Sedangkan Macbook M1 Pro yang biasa digunakan untuk R&D memiliki CPU yang lebih bertenaga dengan core yang lebih sedikit.
Kami mengaktifkan multithreading jika opsional, tetapi kami tidak menggunakan akselerasi GPU dalam benchmark ini. Kami berencana untuk memasukkan benchmarking GPU sebagai bagian dari pekerjaan kami di masa depan.
Hasil Tolok Ukur
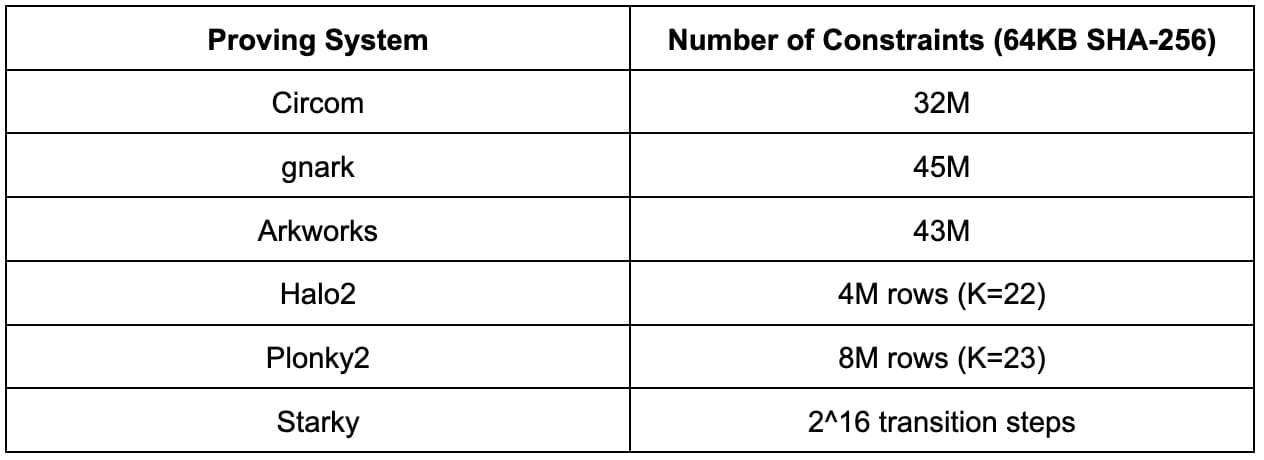
Jumlah Kendala
Sebelum kita beralih ke hasil benchmarking secara detail, ada baiknya kita terlebih dahulu memahami kompleksitas SHA-256 dengan melihat jumlah kendala di setiap sistem pembuktian. Penting untuk menyadari bahwa angka kendala dalam skema aritmetisasi yang berbeda tidak dapat dibandingkan secara langsung.
Hasil di bawah ini sesuai dengan ukuran pra-gambar sebesar 64KB. Meskipun hasilnya mungkin berbeda dengan ukuran pra-gambar lainnya, hasilnya dapat diskalakan secara linear.
Circom, gnark, dan Arkworks semuanya menggunakan aritmetisasi R1CS yang sama, dan jumlah batasan R1CS untuk komputasi 64KB SHA-256 kira-kira 30M hingga 45M. Perbedaan antara Circom, gnark, dan Arkworks kemungkinan besar disebabkan oleh perbedaan implementasi.
Halo2 dan Plonky2 keduanya menggunakan aritmetisasi Plonkish, dengan jumlah baris berkisar dari 2^22 hingga 2^23. Implementasi Halo2 pada SHA-256 jauh lebih efisien dibandingkan di Plonky2 karena penggunaan tabel pencarian.
Starky menggunakan aritmetisasi AIR di mana tabel jejak eksekusi memerlukan 2^16 langkah transisi.
Waktu Pembuatan Bukti
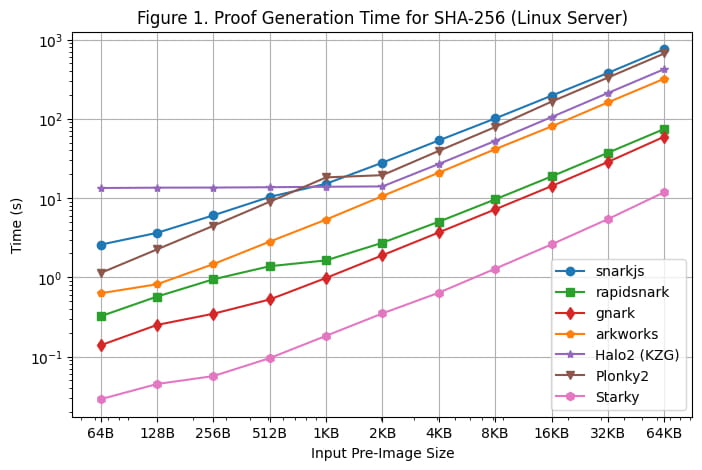
[Gambar 1] mengilustrasikan waktu pembuatan bukti setiap kerangka kerja untuk SHA-256 pada berbagai ukuran pra-gambar, menggunakan Server Linux. Kami dapat melakukan pengamatan berikut:
Untuk SHA-256, kerangka kerja Groth16 (rapidsnark, gnark, dan Arkworks) menghasilkan bukti lebih cepat daripada kerangka Plonk (Halo2 dan Plonky2). Hal ini karena SHA-256 terutama terdiri dari operasi bitwise dengan nilai kawat 0 atau 1. Untuk Groth16, hal ini mengurangi sebagian besar komputasi dari perkalian skalar kurva elips menjadi penambahan titik kurva elips. Namun, nilai kawat tidak secara langsung digunakan dalam komputasi Plonk, sehingga struktur kawat khusus di SHA-256 tidak mengurangi jumlah komputasi yang diperlukan dalam kerangka Plonk.
Di antara semua kerangka kerja Groth16, gnark dan rapidsnark 5x-10x lebih cepat dibandingkan Arkworks dan snarkjs. Hal ini berkat kemampuan superior mereka dalam memanfaatkan banyak inti untuk memparalelkan pembuatan bukti. Gnark 25% lebih cepat dari rapidsnark.
Untuk kerangka kerja Plonk, Plonky2 50% lebih lambat dibandingkan Halo2 untuk SHA-256 saat menggunakan ukuran pra-gambar yang lebih besar >= 4KB. Hal ini karena implementasi Halo2 banyak menggunakan tabel pencarian untuk mempercepat operasi bitwise, sehingga menghasilkan baris 2x lebih sedikit dibandingkan Plonky2. Namun, jika kita membandingkan Plonky2 dan Halo2 dengan jumlah baris yang sama (misalnya, SHA-256 lebih dari 2KB di Halo2 vs. SHA-256 lebih dari 4KB di Plonky2), Plonky2 50% lebih cepat daripada Halo2. Jika kita mengimplementasikan SHA-256 dengan tabel pencarian di Plonky2, kita bisa memperkirakan Plonky2 lebih cepat dari Halo2, meskipun ukuran bukti Plonky2 lebih besar.
Di sisi lain, ketika ukuran pra-gambar masukan kecil (<=512 byte), Halo2 lebih lambat dibandingkan Plonky2 (dan kerangka kerja lainnya) karena biaya pengaturan tetap tabel pencarian yang menyebabkan sebagian besar kendala. Namun, seiring dengan peningkatan gambar awal, performa Halo2 menjadi lebih kompetitif, dengan waktu pembuatan bukti yang tetap konstan untuk ukuran gambar awal hingga 2 KB dan kemudian diskalakan hampir secara linier, seperti yang dapat diamati pada grafik.
Seperti yang diharapkan, waktu pembuatan bukti Starky secara signifikan lebih pendek (5x-50x) dibandingkan kerangka SNARK mana pun, namun hal ini mengakibatkan ukuran bukti yang jauh lebih besar.
Catatan tambahan adalah meskipun ukuran sirkuit linear dalam ukuran pra-gambar, pembuatan bukti tumbuh super-linear untuk SNARK karena FFT O(nlogn) (walaupun hal ini tidak terlihat jelas pada grafik karena skala log).
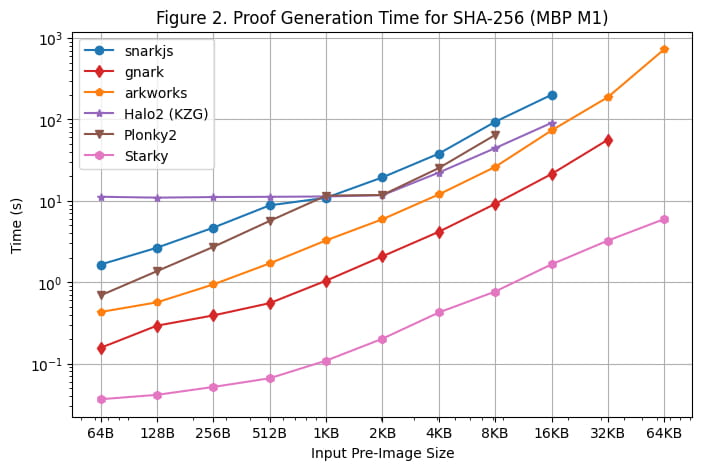
Kami juga melakukan tolok ukur waktu pembuatan bukti pada Macbook M1 Pro, seperti yang diilustrasikan pada [Gambar 2]. Namun, penting untuk dicatat bahwa rapidsnark tidak disertakan dalam benchmark ini karena kurangnya dukungan untuk arsitektur arm64. Untuk menggunakan snarkjs di arm64, kami harus membuat saksi menggunakan webassembly, yang lebih lambat dibandingkan pembuatan saksi C++ yang digunakan di Server Linux.
Ada beberapa pengamatan tambahan saat menjalankan benchmark di Macbook M1 Pro:
Kecuali Starky, semua kerangka SNARK mengalami kesalahan kehabisan memori (OOM) atau menggunakan memori swap (mengakibatkan waktu pembuktian lebih lambat) ketika ukuran pra-gambar menjadi besar. Secara khusus, kerangka kerja Groth16 (snarkjs, gnark, Arkworks) mulai menggunakan memori swap ketika ukuran pra-gambar lebih besar dari atau sama dengan 8KB, dan gnark menemui OOM sebesar 64KB. Halo2 mengalami batas memori ketika ukuran gambar awal lebih besar atau sama dengan 32KB. Plonky2 mulai menggunakan memori swap ketika ukuran gambar awal lebih besar atau sama dengan 8KB.
Kerangka kerja berbasis FRI (Starky dan Plonky2) sekitar 60% lebih cepat di Macbook M1 Pro dibandingkan di Server Linux, sementara kerangka kerja lain mengalami waktu pembuktian yang serupa dibandingkan dengan kerangka kerja di Server Linux. Hasilnya, Plonky2 mencapai waktu pembuktian yang hampir sama dengan Halo2 di Macbook M1 Pro, meskipun tabel pencarian tidak digunakan di Plonky2. Alasan utamanya adalah Macbook M1 Pro memiliki CPU yang lebih bertenaga tetapi dengan inti yang lebih sedikit. FRI terutama melakukan operasi hash, yang lebih sensitif terhadap siklus jam CPU tetapi tidak dapat diparalelkan seperti KZG/Groth16.
Penggunaan Memori Puncak
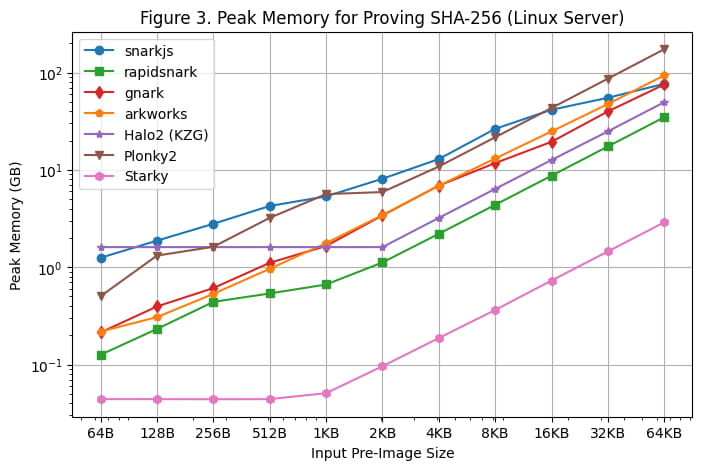
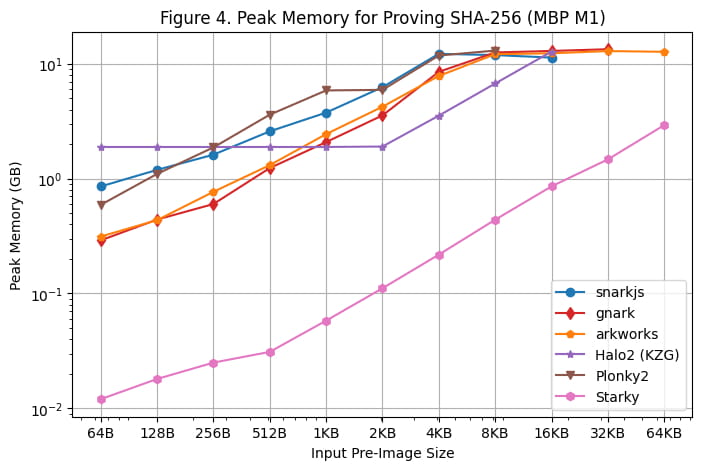
Penggunaan memori puncak selama pembuatan bukti di Server Linux dan Macbook M1 Pro masing-masing ditunjukkan pada [Gambar 3] dan [Gambar 4]. Pengamatan berikut dapat dilakukan berdasarkan hasil benchmarking tersebut:
Di antara semua kerangka SNARK, rapidsnark adalah yang paling hemat memori. Kami juga melihat bahwa Halo2 menggunakan lebih banyak memori ketika ukuran pra-gambar lebih kecil karena biaya pengaturan tetap tabel pencarian, namun mengkonsumsi lebih sedikit memori secara keseluruhan ketika ukuran pra-gambar lebih besar.
Starky 10x lebih hemat memori dibandingkan kerangka kerja SNARK. Hal ini sebagian disebabkan oleh penggunaan baris yang lebih sedikit.
Perlu dicatat bahwa penggunaan memori puncak tetap relatif datar pada Macbook M1 Pro karena ukuran gambar awal menjadi besar karena penggunaan memori swap.
Pemanfaatan CPU
Kami mengevaluasi tingkat paralelisasi untuk setiap sistem pembuktian dengan mengukur rata-rata penggunaan CPU selama pembuatan bukti untuk SHA-256 melalui input pra-gambar 4KB. Tabel di bawah menunjukkan rata-rata penggunaan CPU (dan rata-rata penggunaan per inti dalam tanda kurung ) di Server Linux (dengan 20 core) dan Macbook M1 Pro (dengan 10 core).
Pengamatan utamanya adalah sebagai berikut:
Gnark dan rapidsnark menunjukkan penggunaan CPU tertinggi di Server Linux, menunjukkan kemampuan mereka untuk menggunakan banyak inti secara efisien dan memparalelkan pembuatan bukti. Halo2 juga menunjukkan kinerja paralelisasi yang baik.
Sebagian besar kerangka kerja menunjukkan penggunaan CPU 2x di Server Linux dibandingkan dengan Macbook Pro M1, pengecualian untuk ini adalah snarkjs.
Meskipun ada ekspektasi awal bahwa kerangka kerja berbasis FRI (Plonky2 dan Starky) mungkin kesulitan menggunakan banyak inti secara efektif, kinerjanya tidak lebih buruk daripada beberapa kerangka kerja Groth16/KZG dalam tolok ukur kami. Masih harus dilihat apakah akan ada perbedaan dalam pemanfaatan CPU pada mesin dengan lebih banyak core (misalnya, 100 core).

Kesimpulan dan Pekerjaan Masa Depan
Entri blog ini menyajikan perbandingan komprehensif kinerja SHA-256 pada berbagai kerangka pengembangan zk-SNARK dan zk-STARK. Melalui hasil benchmark, kami memperoleh wawasan tentang efisiensi dan kepraktisan setiap kerangka kerja untuk pengembang yang memerlukan bukti ringkas untuk pengoperasian SHA-256. Kerangka kerja Groth16 (misalnya, rapidsnark, gnark) ditemukan lebih cepat dalam menghasilkan bukti dibandingkan kerangka Plonk (misalnya, Halo2, Plonky2). Tabel pencarian dalam aritmetisasi Plonkish secara signifikan mengurangi batasan dan waktu pembuktian untuk SHA-256 saat menggunakan ukuran pra-gambar yang lebih besar. Selain itu, gnark dan rapidsnark menunjukkan kemampuan luar biasa dalam memanfaatkan banyak inti untuk paralelisasi. Starky, sebaliknya, menunjukkan waktu pembuatan bukti yang jauh lebih singkat namun dengan mengorbankan ukuran bukti yang jauh lebih besar. Dalam hal efisiensi memori, rapidsnark dan Starky mengungguli kerangka kerja lainnya.
Sebagai langkah pertama dalam membangun Pantheon ZKP, kami mengakui bahwa hasil benchmark ini masih jauh dari pengujian komprehensif akhir yang kami tuju suatu hari nanti. Kami menyambut dan terbuka terhadap masukan dan kritik, serta mengundang semua orang untuk berkontribusi pada inisiatif menjadikan ZKP lebih mudah dan lebih mudah diakses oleh pengembang. Kami juga bersedia memberikan hibah bagi kontributor individu untuk menutupi biaya sumber daya komputasi untuk pembandingan skala besar. Bersama-sama kita dapat meningkatkan efisiensi dan kepraktisan ZKP untuk kepentingan masyarakat luas.