

Pada awal September, Yandex menyelenggarakan konferensi mini pribadi tentang AI generatif, yang menyediakan platform untuk mendalami dunia AI. Namun demikian, konferensi tersebut menghasilkan pengungkapan yang signifikan, terutama mengenai YandexGPT 2 yang sangat dinantikan.
Peluncuran YandexGPT 2 oleh Yandex membuat komunitas AI penuh dengan antisipasi. Pembuat model ini mengeksplorasi berbagai fitur pembeda, termasuk modul khusus yang dirancang untuk mencari dan memberikan jawaban berdasarkan data hasil pencarian. Khususnya, temuan tim ini mengungkap aspek yang mencolok: bahkan ketika dilatih pada repositori data internal Yandex yang sangat besar yang mencakup lebih dari satu dekade pengerjaan mekanisme pencarian saraf, model eksklusif ini masih belum mampu menandingi GPT-4 yang tangguh. Perkembangan signifikan ini menggarisbawahi kemajuan luar biasa yang dicapai oleh GPT-4. Pengamatan ini menonjolkan supremasi GPT-4 atas pengembangan berpemilik dan iterasi sumber terbuka sebelumnya.
Untuk memperluas wawasan dasar tersebut, Google melakukan penelitian untuk menilai keakuratan respons dari Model Bahasa Besar (LLM) yang dilengkapi dengan akses mesin pencari. Meskipun gagasan untuk mengintegrasikan alat eksternal dengan LLM bukanlah hal baru, Google menemukan bahwa kompleksitasnya terletak pada penilaian dan validasi model ini. Faktor penting yang membentuk integrasi ini mencakup pemilihan prompt yang dibuat dengan cermat dan kemampuan intrinsik LLM.
Metodologi Tes LLM Google
Kumpulan 600 pertanyaan yang dikurasi dibagi menjadi empat kelompok berbeda. Masing-masing kelompok memprioritaskan keakuratan faktual, namun ada satu kelompok yang menonjol karena memasukkan pertanyaan-pertanyaan yang berakar pada premis-premis yang salah. Misalnya, pertanyaan-pertanyaan seperti “apa yang ditulis Trump setelah larangannya dicabut di Twitter?” berisi premis yang tidak akurat, karena Trump belum dicabut larangannya. Tiga kelompok sisanya memperkenalkan variabel keusangan jawaban: tidak pernah, jarang, dan sering. Dalam kelompok “tidak pernah”, LLM diharapkan menjawab murni dari ingatan, sedangkan pertanyaan tentang kejadian terkini memerlukan pencarian waktu nyata. Setiap kelompok terdiri dari 125 pertanyaan.
Pertanyaan-pertanyaan tersebut disajikan kepada beragam model. Menariknya, pertanyaan yang mengandung premis palsu mengungkap dominasi GPT-4 dan ChatGPT, yang dengan cerdik membantah premis tersebut, dan menunjukkan pelatihan khusus mereka untuk menangani tantangan tersebut.
Analisis komparatif pun terjadi, yang mengadu ChatGPT, GPT-4, penelusuran Google (berdasarkan cuplikan teks atau jawaban halaman pertama), dan PPLX.AI (platform yang memanfaatkan ChatGPT untuk mengumpulkan tanggapan Google, yang ditujukan untuk pengembang) satu sama lain. Dalam konteks ini, LLM memberikan jawaban secara eksklusif dari ingatan mereka.
Dalam pengamatan yang patut diperhatikan, penelusuran Google memberikan jawaban yang benar rata-rata pada 40% kasus di keempat kelompok. Akurasi untuk pertanyaan “abadi” mencapai 70%, sementara pertanyaan dengan premis salah merosot menjadi hanya 11%. Performa ChatGPT rata-rata mencapai 26%, sementara GPT-4 mencapai 28%, dan secara mengesankan mampu menjawab pertanyaan dengan premis palsu dalam 42% kasus. PPLX.AI menunjukkan tingkat keberhasilan 52%.
Studi ini menggali lebih dalam dengan mengintegrasikan pendekatan baru. Setiap pertanyaan mendorong pencarian Google, dan hasilnya dimasukkan ke dalam prompt. LLM kemudian diminta untuk “membaca” informasi ini sebelum menyusun jawaban mereka. Teknik ini memungkinkan pembelajaran Few-Shot (di mana contoh disajikan dalam prompt untuk memandu model) dan pertimbangan langkah demi langkah yang bijaksana sebelum menjawab.
Hasilnya sungguh menakjubkan. GPT-4 menunjukkan peringkat kualitas yang luar biasa sebesar 77%, menjawab pertanyaan “abadi” dengan akurasi 96% dan menjawab pertanyaan premis palsu dengan presisi 75% yang patut dipuji. Meskipun ChatGPT menawarkan metrik yang sedikit kurang mengesankan, performanya mengungguli PPLX.AI dan penelusuran Google.
Menguasai Desain Prompt AI: Wawasan Utama dari PPLX.AI dan Pakar Google
Kemampuan untuk memandu Model Bahasa Besar (LLM) secara efektif melalui labirin informasi bukanlah suatu prestasi kecil. Namun, eksplorasi baru-baru ini terhadap permintaan AI telah menjelaskan strategi-strategi utama yang menjanjikan untuk meningkatkan kualitas respons yang dihasilkan LLM, memberikan gambaran sekilas tentang mekanisme bantuan AI yang berbeda.
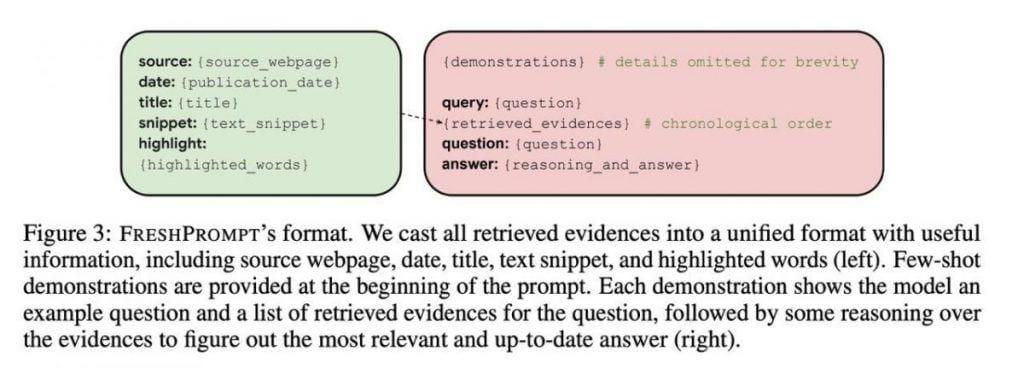
Landasan bagi wahyu ini dibangun melalui penataan yang cermat dan cepat. Metode ini terdiri dari beberapa komponen, menawarkan jalur yang jelas untuk mencapai jawaban yang tepat, dan didasarkan pada pemahaman kontekstual. Aspek awal mencakup contoh ilustratif, berfungsi sebagai penanda panduan, mengarahkan LLM menuju jawaban yang benar berdasarkan petunjuk kontekstual.
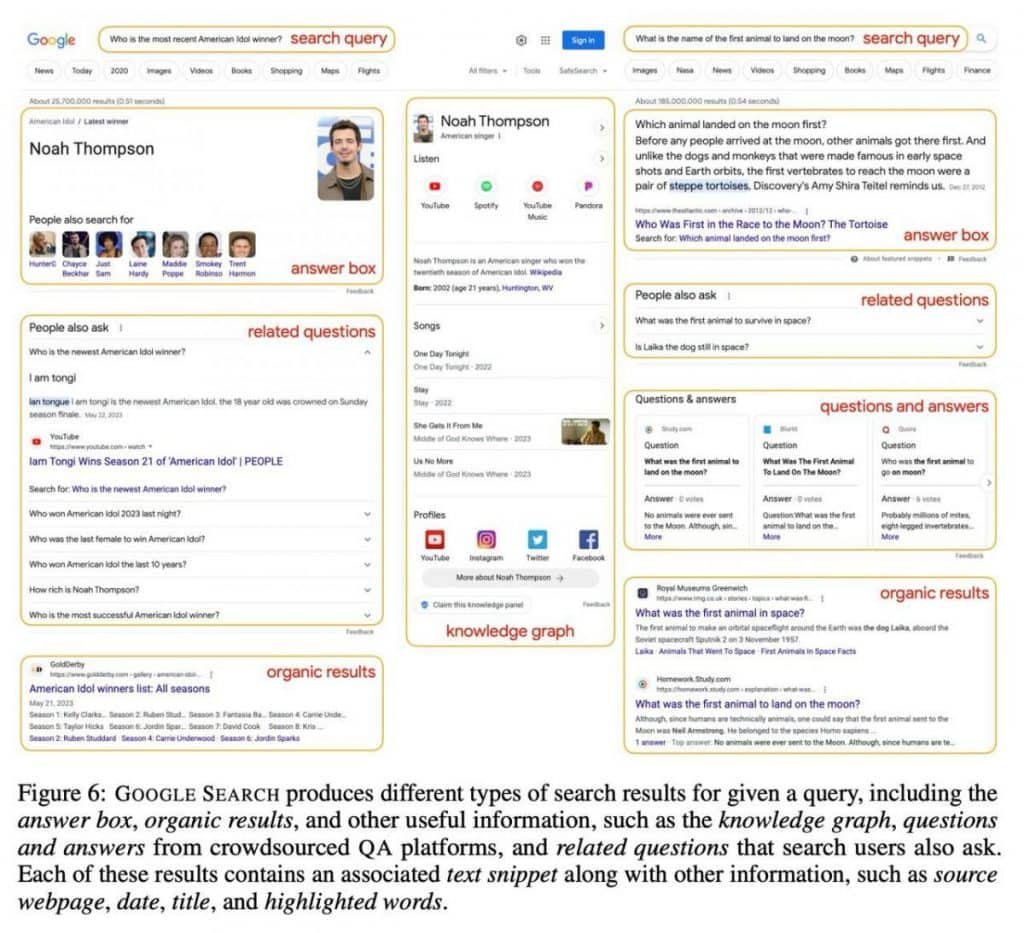
lapisan kedua mengungkapkan permintaan sebenarnya bersama dengan 10-15 hasil pencarian. Hasil ini lebih dari sekadar tautan halaman web, yang mencakup banyak informasi, termasuk konten tekstual, kueri yang relevan, pertanyaan, jawaban, dan grafik pengetahuan. Pendekatan ini melengkapi AI dengan perpustakaan pengetahuan yang komprehensif.
Kecanggihan sistem ini lebih jauh lagi. Penemuan penting muncul ketika menyusun tautan secara kronologis dalam prompt, menempatkan penambahan terbaru di bagian akhir. Susunan kronologis ini mencerminkan sifat informasi yang terus berkembang, sehingga memungkinkan model untuk membedakan garis waktu perubahan. Dimasukkannya tanggal dalam setiap contoh memainkan peran penting dalam meningkatkan pemahaman kontekstual.
Meskipun kode untuk menggunakan struktur prompt yang bernuansa ini sangat dinantikan, ketidakhadirannya telah mendorong para penggemar untuk mencoba menulis ulang template prompt berdasarkan gambar yang disediakan.
Beberapa hal penting yang dapat diambil dari penelitian ini terhadap mekanisme perintah AI:
1) PPLX.AI, sebuah platform yang memanfaatkan ChatGPT untuk mengumpulkan tanggapan Google, telah muncul sebagai opsi yang menjanjikan. Bahkan karyawan Google telah mengisyaratkan keunggulannya.
2) Eksperimen dengan berbagai elemen menghasilkan peningkatan dalam metrik respons. Ketepatan dalam konstruksi yang cepat, tampaknya, merupakan seni tersendiri.
3) GPT-4 menunjukkan kemahiran yang patut dipuji dalam memproses banyak sekali berita dan teks. Meskipun mungkin tidak dikategorikan sebagai “luar biasa”, kualitasnya bahkan dalam skenario berita yang berubah dengan cepat berada di kisaran 60%. Komunitas AI didorong untuk mengevaluasi metrik tersebut secara kritis.
4) Seiring dengan berkembangnya ekosistem AI, LLM yang diintegrasikan ke dalam mesin pencari siap untuk tersebar luas dan melayani spektrum pengguna yang luas. Kehadiran AI dalam pengalaman penelusuran sehari-hari sedang mengalami peningkatan, menandakan perubahan transformatif dalam cara informasi diakses dan diproses.
Pendekatan multifaset menawarkan cara yang menjanjikan untuk mendapatkan jawaban akurat dari model bahasa canggih ini karena mencakup contoh ilustratif, pertanyaan yang didefinisikan dengan jelas, dan banyak informasi kontekstual. Susunan kronologis tautan dalam petunjuknya menghasilkan wawasan yang signifikan, menggarisbawahi pentingnya beradaptasi dengan sifat dinamis informasi. LLM dapat menavigasi garis waktu perubahan berkat kesadaran temporal ini, yang meningkatkan pemahaman kontekstual mereka.
Pos Analisis Google Mengungkapkan Wawasan Mengejutkan tentang LLM dan Akurasi Mesin Pencari muncul pertama kali di Metaverse Post.