

Judul asli: "Dari GPT-1 hingga GPT-4, lihat kebangkitan ChatGPT"
Penulis asli: Catatan Penelitian Kelinci Alpha
Apa itu ObrolanGPT?

Apa itu ObrolanGPT?
Baru-baru ini, OpenAI merilis ChatGPT, sebuah model yang dapat berinteraksi secara percakapan. Karena kecerdasannya, ia disambut baik oleh banyak pengguna. ChatGPT juga merupakan kerabat dari InstructGPT yang sebelumnya dirilis oleh OpenAI. Model ChatGPT dilatih menggunakan RLHF (Pembelajaran penguatan dengan umpan balik manusia). Mungkin kedatangan ChatGPT juga merupakan pendahuluan sebelum peluncuran resmi GPT-4 OpenAI.
Apa itu GPT? Dari GPT-1 hingga GPT-3
Transformator Pra-terlatih Generatif (GPT) adalah model pembelajaran mendalam pembuatan teks yang dilatih berdasarkan data yang tersedia di Internet. Ini digunakan untuk menjawab pertanyaan, meringkas teks, terjemahan mesin, klasifikasi, pembuatan kode, dan AI percakapan.
Pada tahun 2018 lahirlah GPT-1 yang juga merupakan tahun pertama model pra-pelatihan NLP (pemrosesan bahasa alami). Dari segi performa, GPT-1 memiliki kemampuan generalisasi tertentu dan dapat digunakan dalam tugas-tugas NLP yang tidak ada hubungannya dengan tugas pengawasan. Tugas umum meliputi:
Penalaran bahasa alami: menentukan hubungan antara dua kalimat (penahanan, kontradiksi, netralitas)
Tanya jawab dan penalaran akal sehat: masukkan artikel dan beberapa jawaban, dan keluarkan keakuratan jawabannya
Pengenalan kesamaan semantik: Tentukan apakah dua kalimat terkait secara semantik
Kategori: Tentukan kategori mana yang termasuk dalam teks masukan
Meskipun GPT-1 memiliki beberapa efek pada tugas yang tidak disetel, kemampuan generalisasinya jauh lebih rendah dibandingkan tugas yang diawasi dengan baik. Oleh karena itu, GPT-1 hanya dapat dianggap sebagai alat pemahaman bahasa yang cukup baik dibandingkan AI percakapan.
GPT-2 juga hadir sesuai jadwal pada tahun 2019. Namun, GPT-2 tidak melakukan terlalu banyak inovasi dan desain struktural pada jaringan aslinya. Ia hanya menggunakan lebih banyak parameter jaringan dan kumpulan data yang lebih besar: total model maksimum Ini memiliki 48 lapisan dan 1,5 miliar parameter. Target pembelajaran menggunakan model pra-pelatihan tanpa pengawasan untuk melakukan tugas-tugas yang diawasi. Dalam hal kinerja, selain kemampuan pemahaman, GPT-2 untuk pertama kalinya menunjukkan bakat yang kuat dalam generasi: membaca ringkasan, mengobrol, terus menulis, mengarang cerita, dan bahkan menghasilkan berita palsu, email phishing, atau bermain peran. daring. Tidak masalah. Setelah "menjadi lebih besar", GPT-2 menunjukkan kemampuannya yang universal dan kuat serta mencapai performa terbaik pada saat itu pada beberapa tugas pemodelan bahasa tertentu.
Setelah itu, GPT-3 muncul. Sebagai model tanpa pengawasan (sekarang sering disebut model yang diawasi sendiri), model ini hampir dapat menyelesaikan sebagian besar tugas pemrosesan bahasa alami, seperti penelusuran berorientasi masalah, pemahaman bacaan, inferensi semantik, dan terjemahan mesin. . , pembuatan artikel dan tanya jawab otomatis, dll. Selain itu, model ini berkinerja baik dalam banyak tugas, seperti mencapai tingkat tercanggih saat ini dalam tugas terjemahan mesin Prancis-Inggris dan Jerman-Inggris. Artikel yang dibuat secara otomatis hampir tidak mungkin dibedakan antara manusia dan mesin (hanya Akurasi 52%) , sebanding dengan tebakan acak), dan yang lebih mengejutkan lagi adalah ia mencapai akurasi hampir 100% pada tugas penjumlahan dan pengurangan dua digit, dan bahkan dapat secara otomatis menghasilkan kode berdasarkan deskripsi tugas. Model tanpa pengawasan memiliki banyak fungsi dan efek yang baik, dan tampaknya masyarakat melihat harapan akan kecerdasan buatan secara umum. Ini mungkin menjadi alasan utama mengapa GPT-3 memiliki dampak yang begitu besar.
Apa sebenarnya model GPT-3 itu?
Faktanya, GPT-3 adalah model bahasa statistik sederhana. Dari perspektif pembelajaran mesin, model bahasa memodelkan distribusi probabilitas rangkaian kata, yaitu menggunakan fragmen yang telah diucapkan sebagai kondisi untuk memprediksi distribusi probabilitas berbagai kata yang muncul pada saat berikutnya. Di satu sisi, model bahasa dapat mengukur sejauh mana sebuah kalimat sesuai dengan tata bahasa bahasa (misalnya, mengukur apakah balasan yang dihasilkan secara otomatis oleh sistem dialog manusia-komputer bersifat alami dan lancar), dan model tersebut juga dapat digunakan. untuk memprediksi dan menghasilkan kalimat baru. Misalnya, untuk klip "Sekarang jam 12 siang, ayo pergi ke restoran bersama", model bahasa dapat memprediksi kata yang mungkin muncul setelah "restoran". Model bahasa umum akan memprediksi kata berikutnya adalah "makan". Model bahasa yang kuat dapat menangkap informasi waktu dan memprediksi kata "makan siang" yang sesuai dengan konteksnya.
Biasanya, kekuatan suatu model bahasa terutama bergantung pada dua hal: pertama, apakah model tersebut dapat memanfaatkan semua informasi konteks historis, jika model tersebut tidak dapat menangkap informasi semantik jangka panjang "jam 12 siang", maka model bahasa tersebut akan hampir tidak dapat diprediksi waktu berikutnya. Kedua, hal ini juga bergantung pada apakah terdapat konteks historis yang cukup kaya untuk dipelajari oleh model, yaitu apakah korpus pelatihan cukup kaya. Karena model bahasa adalah pembelajaran yang diawasi sendiri, tujuan pengoptimalannya adalah memaksimalkan kemungkinan model bahasa dari teks yang dilihat, sehingga teks apa pun dapat digunakan sebagai data pelatihan tanpa pelabelan.
Karena performa GPT-3 yang lebih kuat dan parameter yang jauh lebih banyak, teks topiknya lebih banyak, yang jelas lebih baik dibandingkan GPT-2 generasi sebelumnya. Sebagai jaringan saraf padat terbesar yang tersedia saat ini, GPT-3 dapat mengubah deskripsi halaman web menjadi kode yang sesuai, meniru narasi manusia, membuat puisi khusus, membuat skrip permainan, dan bahkan meniru filsuf yang telah meninggal yang meramalkan makna hidup yang sebenarnya. Dan GPT-3 tidak memerlukan penyesuaian, hanya memerlukan beberapa sampel jenis keluaran (sejumlah kecil pembelajaran) untuk menangani masalah tata bahasa yang sulit. Dapat dikatakan bahwa GPT-3 tampaknya telah memuaskan semua imajinasi kita sebagai para ahli bahasa.
Catatan: Hal di atas terutama mengacu pada artikel berikut:
1. GPT 4 akan segera dirilis dan sebanding dengan otak manusia. Banyak pemain besar di industri ini tidak bisa duduk diam! -Xu Jiecheng, Yun Zhao -Akun publik 51 Tumpukan Teknologi CTO- 24-11-2022 18: 08
2. Jawab rasa penasaran Anda tentang GPT-3 dalam satu artikel! Apa itu GPT-3? Mengapa ini sangat bagus? -Institut Otomasi Zhang Jiajun, Akademi Ilmu Pengetahuan Tiongkok Diterbitkan di Beijing pada 11-11-2020 17:25
3. Batch: 329 |. InstructGPT, model bahasa yang lebih ramah dan lembut-akun publik DeeplearningAI-2022-02-07 12: 30
Apa masalah dengan GPT-3?
Namun GTP-3 tidak sempurna. Salah satu masalah utama yang paling dikhawatirkan orang-orang dalam kecerdasan buatan adalah bahwa chatbots dan alat pembuat teks cenderung mempelajari semua teks di Internet tanpa pandang bulu dan berkualitas. atau bahkan keluaran bahasa yang menyinggung dihasilkan, yang akan sepenuhnya mempengaruhi aplikasi berikutnya.
OpenAI juga mengusulkan agar GPT-4 yang lebih kuat akan dirilis dalam waktu dekat:
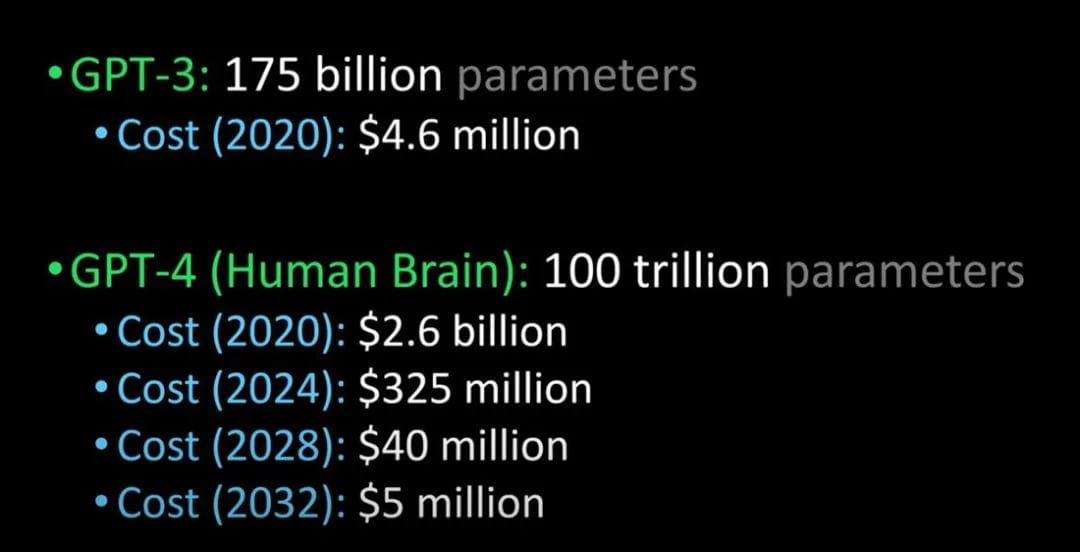
Membandingkan GPT-3 dengan GPT-4 dan otak manusia (Kredit gambar: Lex Fridman @youtube)
Dikatakan bahwa GPT-4 akan dirilis tahun depan. Ia dapat lulus uji Turing dan sangat canggih sehingga tidak dapat dibedakan dengan manusia. Selain itu, biaya yang dikeluarkan perusahaan untuk memperkenalkan GPT-4 juga akan sangat berkurang.
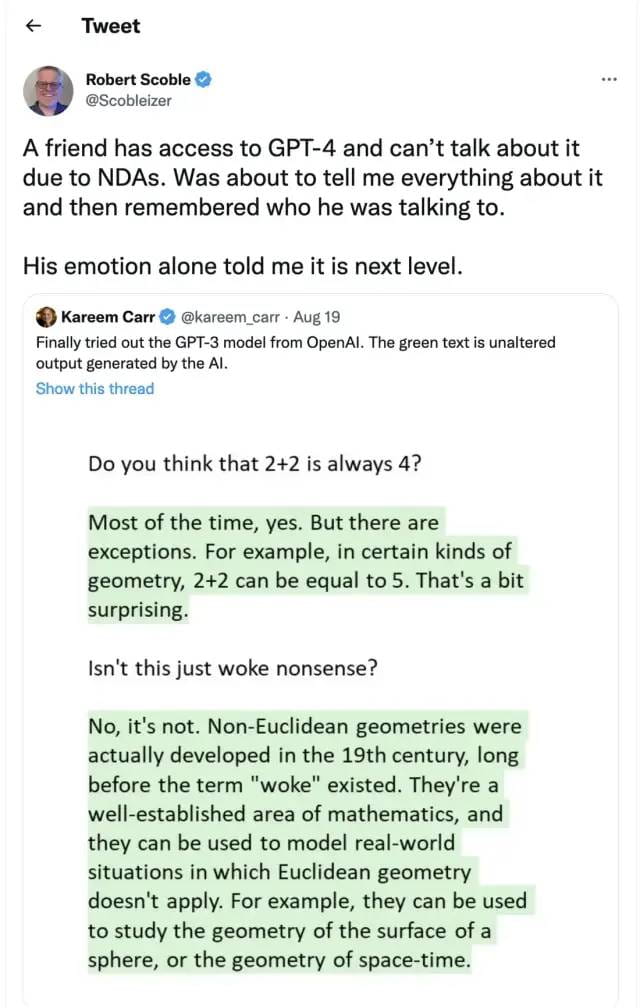
ChatGP dan InstructGPT
ObrolanGPT dan InstruksiGPT
Ketika berbicara tentang Chatgpt, kita harus berbicara tentang InstructGPT "pendahulunya".
Pada awal tahun 2022, OpenAI merilis InstructGPT; dalam penelitian ini, dibandingkan dengan GPT-3, OpenAI menggunakan penelitian penyelarasan untuk melatih model bahasa yang lebih realistis, lebih tidak berbahaya, dan lebih mengikuti niat pengguna versi GPT-3 yang meminimalkan keluaran yang berbahaya, tidak realistis, dan bias.
Bagaimana cara kerja InstructGPT?
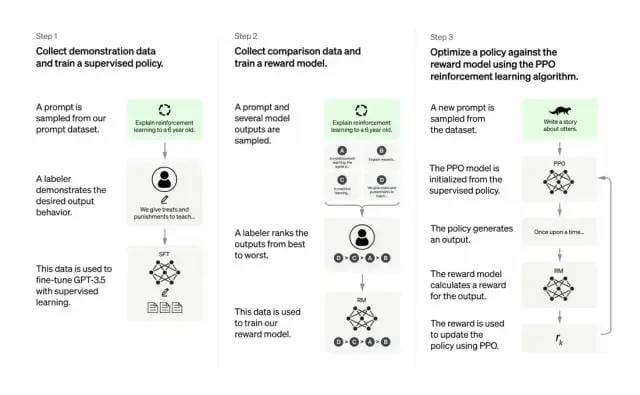
Pengembang melakukan ini dengan menggabungkan pembelajaran yang diawasi + pembelajaran penguatan dari umpan balik manusia. Untuk meningkatkan kualitas keluaran GPT-3. Dalam jenis pembelajaran ini, manusia memberi peringkat pada keluaran potensial suatu model; algoritma pembelajaran penguatan memberi penghargaan pada model yang menghasilkan materi yang serupa dengan keluaran tingkat tinggi.
Kumpulan data pelatihan dimulai dengan membuat perintah, beberapa di antaranya didasarkan pada masukan dari pengguna GPT-3, seperti “Ceritakan sebuah cerita tentang katak” atau “Jelaskan pendaratan di bulan kepada anak berusia 6 tahun dalam beberapa kalimat. ”
Pengembang membagi perintah menjadi tiga bagian dan membuat respons untuk setiap bagian secara berbeda:
Penulis manusia merespons rangkaian petunjuk pertama. Pengembang menyempurnakan GPT-3 terlatih dan mengubahnya menjadi InstructGPT untuk menghasilkan respons yang ada untuk setiap perintah.
Langkah selanjutnya adalah melatih model untuk memberi penghargaan pada respons yang lebih baik dengan imbalan yang lebih tinggi. Untuk rangkaian perintah kedua, model yang dioptimalkan menghasilkan beberapa respons. Penilai manusia memberi peringkat pada setiap tanggapan. Dengan adanya respons cepat dan dua respons, model penghargaan (GPT-3 terlatih lainnya) belajar menghitung imbalan yang lebih tinggi untuk respons yang berperingkat tinggi dan imbalan yang lebih rendah untuk respons yang berperingkat rendah.
Pengembang selanjutnya menyempurnakan model bahasa menggunakan rangkaian petunjuk ketiga dan metode pembelajaran penguatan Proximal Policy Optimization (PPO). Ketika sebuah perintah diberikan, model bahasa menghasilkan respons, dan model penghargaan memberikan imbalan yang sesuai. PPO menggunakan imbalan untuk memperbarui model bahasa.
Referensi untuk paragraf ini: The Batch: 329 |. InstructGPT, model bahasa yang lebih ramah dan lembut-akun publik DeeplearningAI- 07-02-2022 12: 30
Apa yang penting? Intinya adalah kecerdasan buatan harus menjadi kecerdasan buatan yang bertanggung jawab
Model bahasa OpenAI dapat membantu di bidang pendidikan, terapis virtual, alat bantu menulis, permainan peran, dll. Di bidang ini, adanya bias sosial, misinformasi, dan informasi beracun lebih menyusahkan, dan sistem yang dapat menghindari kelemahan ini dapat membantu. menjadi lebih mampu.
Apa perbedaan antara proses pelatihan Chatgpt dan InstructGPT?
Secara umum Chatgpt, seperti InstructGPT di atas, dilatih menggunakan RLHF (Reinforcement Learning from Human Feedback). Perbedaannya adalah cara data disiapkan untuk pelatihan (dan dikumpulkan). (Penjelasan di sini: Model InstructGPT sebelumnya memberikan keluaran untuk suatu masukan, lalu membandingkannya dengan data pelatihan. Ya, ada imbalan dan bukan penalti; Chatgpt saat ini adalah masukan, dan model memberikan banyak keluaran, lalu orang give Penyortiran hasil keluaran ini memungkinkan model untuk mengurutkan hasil ini dari "lebih mirip manusia" hingga "tidak masuk akal", memungkinkan model mempelajari cara manusia mengurutkan. Strategi ini disebut pembelajaran yang diawasi paragraf ini)
Apa batasan ChatGPT?
sebagai berikut:
a) Selama fase pelatihan pembelajaran penguatan (RL), tidak ada sumber kebenaran dan jawaban standar yang spesifik untuk pertanyaan Anda.
b) Model dilatih untuk lebih berhati-hati dan mungkin menolak jawaban (untuk menghindari kesalahan positif).
c) Pelatihan yang diawasi dapat menyesatkan/membiaskan model dalam mengetahui jawaban yang ideal, dibandingkan model yang menghasilkan serangkaian tanggapan acak dan hanya peninjau manusia yang memilih tanggapan yang baik/berperingkat teratas
Catatan: ChatGPT sensitif terhadap kata-kata. , terkadang model akhirnya tidak merespons sebuah frasa, tetapi dengan sedikit penyesuaian pada pertanyaan/frasa, model tersebut akhirnya menjawab dengan benar. Pelatih cenderung memilih jawaban yang lebih panjang karena mungkin tampak lebih komprehensif, sehingga mengarah pada kecenderungan untuk memberikan tanggapan yang lebih panjang dan penggunaan frasa tertentu secara berlebihan dalam model. Jika pertanyaan atau pertanyaan awal bersifat ambigu, model tidak akan meminta klarifikasi dengan tepat.
Batasan ChatGPT yang diidentifikasi sendiri adalah sebagai berikut.
Jawaban yang terdengar masuk akal tetapi salah:
a) Tidak ada sumber kebenaran yang nyata untuk memperbaiki masalah ini selama fase pelatihan Reinforcement Learning (RL).
b) Model pelatihan untuk lebih berhati-hati dapat salah menolak menjawab (positif palsu dari petunjuk yang merepotkan).
c) Pelatihan yang diawasi dapat menyesatkan/membiaskan model cenderung mengetahui jawaban yang ideal daripada model yang menghasilkan serangkaian respons acak dan hanya peninjau manusia yang memilih respons yang baik/berperingkat tinggi.ChatGPT sensitif terhadap penyusunan kata. Terkadang model tersebut berakhir tanpa respons untuk sebuah frasa, tetapi dengan sedikit perubahan pada pertanyaan/frasa, model tersebut akhirnya menjawabnya dengan benar.
Pelatih lebih menyukai jawaban yang lebih panjang dan mungkin terlihat lebih komprehensif, sehingga menyebabkan bias terhadap respons yang bertele-tele dan penggunaan frasa tertentu secara berlebihan. Model ini tidak meminta klarifikasi dengan tepat jika perintah atau pertanyaan awal bersifat ambigu. Lapisan keamanan untuk menolak permintaan yang tidak pantas melalui API Moderasi telah dilaksanakan. Namun, kita masih bisa mengharapkan tanggapan negatif dan positif palsu.
referensi:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 akan segera dirilis dan sebanding dengan otak manusia. Banyak pemain besar di industri ini tidak bisa duduk diam! -Xu Jiecheng, Yun Zhao -Akun publik 51 Tumpukan Teknologi CTO- 24-11-2022 18: 08
5. Jawab rasa penasaran Anda tentang GPT-3 dalam satu artikel! Apa itu GPT-3? Mengapa ini sangat bagus? -Institut Otomasi Zhang Jiajun, Akademi Ilmu Pengetahuan Tiongkok Diterbitkan di Beijing pada 11-11-2020 17:25
6. Batch: 329 |. InstructGPT, model bahasa yang lebih ramah dan lembut-akun publik DeeplearningAI-2022-02-07 12: 30