
Stability AI a publié un nouvel article sur son blog sur Stable Diffusion 2. Dans ce document, Stability AI propose un nouvel algorithme plus efficace et plus robuste que le précédent tout en le comparant à d'autres méthodes de pointe.

Le modèle original Stable Diffusion V1 de CompVis a révolutionné la nature des modèles d'IA open source et a produit des centaines de modèles et d'avancées différents dans le monde. Il a connu l'une des ascensions les plus rapides jusqu'à 10 000 étoiles Github, accumulant 33 000 en moins de deux mois, plus rapidement que la plupart des programmes sur Github.
La version originale de Stable Diffusion V1 a été dirigée par l'équipe dynamique de Robin Rombach (Stability AI) et Patrick Esser (Runway ML) du groupe CompVis du LMU Munich, dirigée par le professeur Dr. Björn Ommer. Ils se sont appuyés sur les travaux antérieurs du laboratoire avec les modèles de diffusion latente et ont reçu le soutien essentiel de LAION et d’Eleuther AI.

 Qu’est-ce qui différencie Stable Diffusion v1 de Stable Diffusion v2 ?
Qu’est-ce qui différencie Stable Diffusion v1 de Stable Diffusion v2 ?
Stable Diffusion 2.0 inclut un certain nombre d'améliorations et de fonctionnalités importantes par rapport à la version précédente, alors examinons-les.
La version Stable Diffusion 2.0 propose des modèles texte-image robustes entraînés avec un nouvel encodeur de texte (OpenCLIP) développé par LAION avec l'aide de Stability AI, qui améliore considérablement la qualité des images générées par rapport aux versions V1 précédentes. Les modèles de conversion texte-image de cette version peuvent générer des images avec des résolutions par défaut de 512 × 512 pixels et 768 × 768 pixels.
Ces modèles sont formés à l’aide d’un sous-ensemble esthétique de l’ensemble de données LAION-5B généré par l’équipe DeepFloyd de Stability AI, qui est ensuite filtré pour exclure le contenu pour adultes à l’aide du filtre NSFW de LAION.
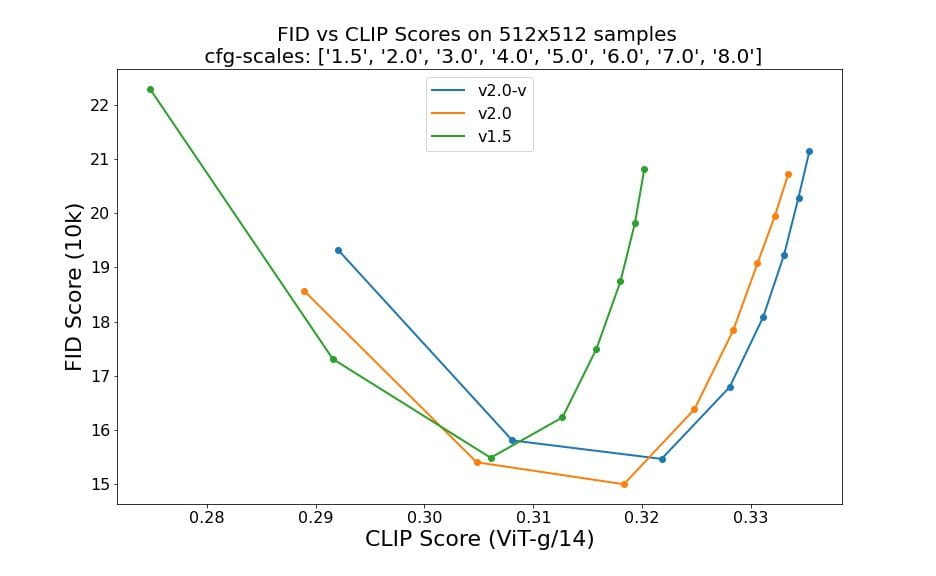
Les évaluations utilisant 50 étapes d'échantillonnage DDIM, 50 échelles directrices sans classificateur et 1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0 et 8,0 indiquent des améliorations relatives des points de contrôle :
Stable Diffusion 2.0 intègre désormais un modèle Upscaler Diffusion, qui augmente la résolution de l'image d'un facteur quatre. Un exemple de notre modèle transformant une image générée de faible qualité (128 × 128) en une image de résolution plus élevée est présenté ci-dessous (512 × 512). Stable Diffusion 2.0, lorsqu'il est combiné avec nos modèles texte-image, peut désormais générer des images avec des résolutions de 2048×2048 ou plus.

Le nouveau modèle de diffusion stable guidé en profondeur, deep2img, étend la fonctionnalité image à image antérieure de la V1 avec des possibilités créatives entièrement nouvelles. Depth2img détermine la profondeur d'une image d'entrée (à l'aide d'un modèle existant), puis génère de nouvelles images basées à la fois sur le texte et les informations de profondeur. Depth-to-Image peut fournir une pléthore de nouvelles applications créatives, offrant des changements qui semblent très différents de l'original tout en conservant la cohérence et la profondeur de l'image.
Quoi de neuf dans Stable Diffusion 2 ?
Le nouveau modèle de diffusion stable offre une résolution de 768×768.
U-Net a le même nombre de paramètres que la version 1.5, mais il est formé à partir de zéro et utilise OpenCLIP-ViT/H comme encodeur de texte. Un modèle dit de prédiction v est le SD 2.0-v.
Le modèle susmentionné a été ajusté à partir de la base SD 2.0, qui est également disponible et a été formé comme un modèle typique de prévision du bruit sur des images 512 × 512.
Un modèle de diffusion latent guidé par texte avec une mise à l'échelle x4 a été ajouté.
Modèle de diffusion stable raffiné, guidé en profondeur, basé sur la base SD 2.0. Le modèle peut être utilisé pour l'img2img préservant la structure et la synthèse conditionnelle de forme et est conditionné sur des estimations de profondeur monoculaires déduites par MiDaS.
Un modèle d'inpainting guidé par texte amélioré construit sur la base SD 2.0.
Les développeurs ont travaillé dur, tout comme lors de la première itération de Stable Diffusion, pour optimiser le modèle afin qu'il fonctionne sur un seul GPU : ils voulaient dès le départ le rendre accessible au plus grand nombre. Ils ont déjà vu ce qui se passe lorsque des millions d’individus mettent la main sur ces modèles et collaborent pour construire des choses absolument remarquables. C'est là le pouvoir de l'open source : exploiter le vaste potentiel de millions de personnes talentueuses qui n'ont peut-être pas les ressources nécessaires pour former un modèle de pointe, mais qui ont la capacité de faire des choses incroyables avec un tel modèle.

Cette nouvelle mise à jour, combinée à de nouvelles fonctionnalités puissantes telles que deep2img et à de meilleures capacités de conversion ascendante de résolution, servira de base à une pléthore de nouvelles applications et permettra une explosion de nouveau potentiel créatif.
En savoir plus sur la diffusion stable :
L'IA à diffusion stable crée des mondes de rêve pour la réalité virtuelle et le métaverse
L'artiste utilise Stable Diffusion pour produire le premier film d'animation entièrement basé sur l'IA
Découvrez l'inpainting vidéo : édition basée sur le texte avec diffusion stable et atlas neuronaux
L'algorithme de diffusion stable 2 de Stability AI est enfin public : nouveau modèle deep2img, upscaler super-résolution, aucun contenu pour adultes n'est apparu en premier sur Metaverse Post.