
Conclusiones principales
En Binance, utilizamos el aprendizaje automático (ML) para resolver diversos problemas comerciales, incluidos, entre otros, fraude de apropiación de cuentas (ATO), estafas P2P y detalles de pago robados.
Utilizando operaciones de aprendizaje automático (MLOps), nuestros científicos de datos de Binance Risk AI han creado un canal de aprendizaje automático de extremo a extremo en tiempo real que ofrece continuamente servicios de aprendizaje automático listos para producción.

¿Por qué utilizamos MLOps?
Para empezar, la creación de un servicio de aprendizaje automático es un proceso iterativo. Los científicos de datos experimentan constantemente para mejorar una métrica específica, ya sea en línea o fuera de línea, con el objetivo de generar valor para el negocio. Entonces, ¿cómo podemos hacer que este proceso sea más eficiente (por ejemplo, acortando el tiempo de comercialización del modelo ML)?
En segundo lugar, el comportamiento de los servicios de aprendizaje automático se ve afectado no solo por el código que nosotros, los desarrolladores, definimos, sino también por los datos que recopila. Esta idea, también conocida como deriva conceptual, se enfatiza en el artículo de Google titulado Hidden Technical Debt in Machine Learning Systems.
Tomemos como ejemplo el fraude; el estafador no es sólo una máquina sino un ser humano que se adapta y cambia constantemente su forma de atacar. Como tal, la distribución de datos subyacente evolucionará para reflejar los cambios en los vectores de ataque. ¿Cómo podemos garantizar de manera efectiva que el modelo de producción considere el patrón de datos más reciente?
Para superar los desafíos mencionados anteriormente, utilizamos un concepto llamado MLOps, un término propuesto inicialmente por Google en 2018. En MLOps, nos centramos en el rendimiento del modelo y la infraestructura que respalda el sistema de producción. Esto nos permite crear servicios de aprendizaje automático que sean escalables, de alta disponibilidad, confiables y fáciles de mantener.
Desglosando nuestro proceso de aprendizaje automático de extremo a extremo en tiempo real
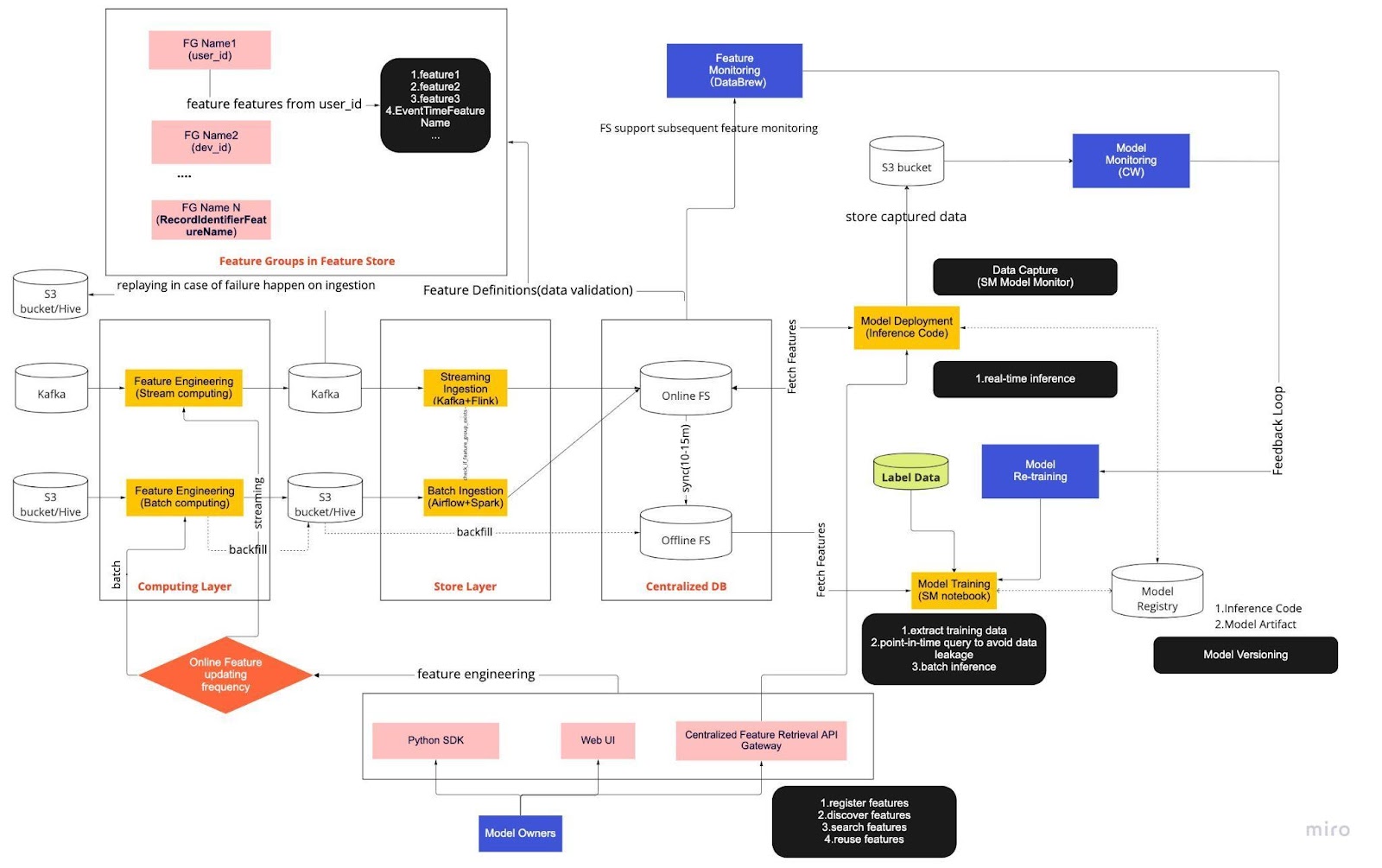
Piense en el diagrama anterior como nuestro procedimiento operativo estándar (SOP) para el desarrollo de modelos en tiempo real con un almacén de funciones. El proceso de aprendizaje automático de un extremo a otro dicta cómo nuestro equipo aplica MLops y está diseñado con dos tipos de requisitos: funcionales y no funcionales.
Funcional
Procesamiento de datos
Entrenamiento modelo
Modelo de desarrollo
Implementación del modelo
Supervisión
requerimientos no funcionales
Escalable
Altamente disponible
Confiable
Mantenible
El proyecto se divide a su vez en seis componentes clave:
Capa informática
Capa de tienda
Base de datos centralizada
Entrenamiento modelo
Implementación del modelo
Monitoreo de modelos
1. Capa informática

La capa informática es la principal responsable de la ingeniería de funciones, el proceso de transformar datos sin procesar en funciones útiles.
Clasificamos la capa informática en dos tipos según la frecuencia con la que se actualizan: informática en flujo para intervalos de un minuto/segundo y informática por lotes para intervalos diarios/de una hora.
Los datos de entrada de la capa informática generalmente provienen de la base de datos basada en eventos, que incluye Apache Kafka y Kinesis, o de la base de datos OLAP, que incluye Apache Hive para soluciones de código abierto y Snowflake para soluciones en la nube.
2. Almacenar capa
La capa de tienda es donde registramos las definiciones de características y las implementamos en nuestra tienda de características, así como también realizamos el reabastecimiento, un proceso que nos permite reconstruir características a través de datos históricos cada vez que se define una nueva característica. El reabastecimiento suele ser un trabajo único que nuestros científicos de datos pueden realizar en un entorno de notebook. Debido a que Kafka solo puede almacenar eventos de los últimos siete días, emplea un mecanismo de respaldo en la tabla s3/hive para aumentar la tolerancia a fallas.
Notarás que la capa intermedia, Hive y Kafka, está deliberadamente alojada entre las capas informática y de almacenamiento. Piense en esta ubicación como un amortiguador entre las funciones informáticas y de escritura. Una analogía sería separar al productor del consumidor. La computación de flujo es el productor, mientras que la ingestión de flujo es el consumidor.
Desacoplar la computación y la ingestión proporciona una variedad de beneficios para nuestras canalizaciones de ML. Para empezar, podemos aumentar la solidez del oleoducto en caso de fallos. Nuestros científicos de datos aún pueden extraer valor de las funciones de la base de datos centralizada, incluso si la capa de ingesta o informática no está disponible debido a problemas operativos, de hardware o de red.
Además, podemos escalar diferentes partes de la infraestructura individualmente y reducir la energía necesaria para construir y operar el gasoducto. Por ejemplo, si falla por cualquier motivo, la capa de ingesta no bloqueará la capa informática. En el frente de la innovación, podemos experimentar y adoptar nuevas tecnologías, como una nueva versión de la aplicación Flink, sin afectar nuestra infraestructura existente.

Tanto la capa informática como la capa de tienda son lo que llamamos canales de funciones automatizados. Estas canalizaciones son independientes, se ejecutan en diferentes horarios y se clasifican como canalizaciones de streaming o por lotes. Así es como funcionan de manera diferente las dos canalizaciones: un grupo de características en una canalización por lotes puede actualizarse cada noche, mientras que otro grupo se actualiza cada hora. En una canalización de transmisión, el grupo de funciones se actualiza en tiempo real a medida que los datos de origen llegan a una secuencia de entrada, como un tema de Apache Kafka.
3. Base de datos centralizada
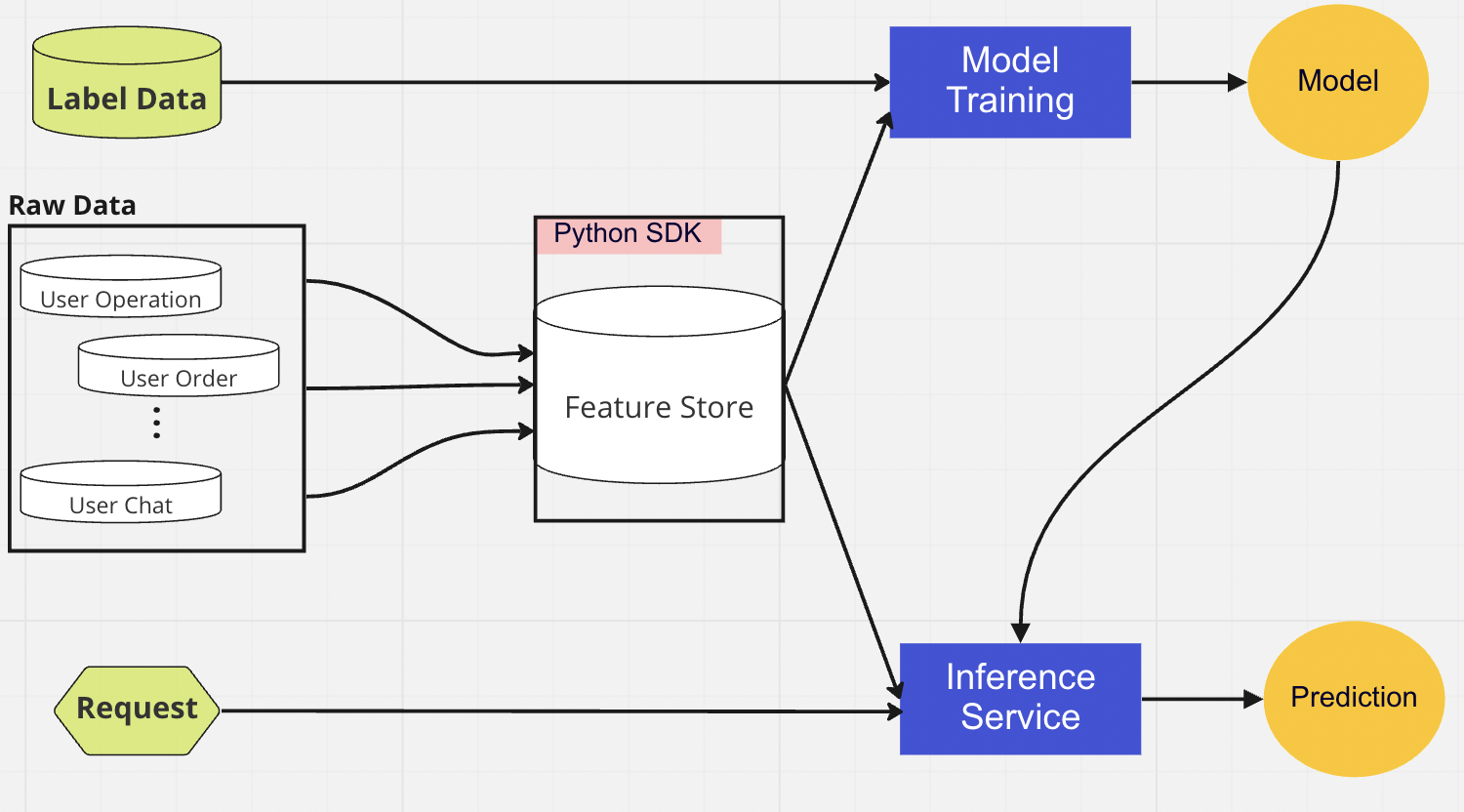
La capa de base de datos centralizada es donde nuestros científicos de datos presentan sus datos listos para funciones en un almacén de funciones en línea o fuera de línea.
La tienda de funciones en línea es una tienda de baja latencia y alta disponibilidad que permite la búsqueda de registros en tiempo real. Por otro lado, el almacén de funciones fuera de línea proporciona un depósito seguro y escalable de todos los datos de funciones. Esto permite a los científicos crear conjuntos de datos de entrenamiento, validación o puntuación por lotes a partir de un conjunto de grupos de características administrados centralmente con un registro histórico completo de los valores de las características en el sistema de almacenamiento de objetos.
Ambas tiendas de funciones se sincronizan automáticamente entre sí cada 10 a 15 minutos para evitar sesgos en el servicio de capacitación. En un artículo futuro, profundizaremos en cómo utilizamos las tiendas de funciones en las canalizaciones.
4. Entrenamiento modelo
La capa de entrenamiento del modelo es donde nuestros científicos extraen datos de entrenamiento del almacén de funciones fuera de línea para ajustar nuestros servicios de aprendizaje automático. Utilizamos consultas puntuales para evitar que se filtren datos durante el proceso de extracción.
Además, esta capa incluye un componente crucial conocido como circuito de retroalimentación de reentrenamiento de modelos. El reentrenamiento de modelos minimiza el riesgo de desviación de conceptos al garantizar que los modelos implementados representen con precisión los patrones de datos más recientes (por ejemplo, un pirata informático que cambia su comportamiento de ataque).
5. Implementación del modelo
Para la implementación del modelo, utilizamos principalmente un servicio de puntuación basado en la nube como columna vertebral de nuestro servicio de datos en tiempo real. A continuación se muestra un diagrama que muestra cómo el código de inferencia actual se integra con el almacén de funciones.

6. Monitoreo del modelo
En esta capa, nuestro equipo monitorea las métricas de uso para calificar servicios como QPS, latencia, memoria y tasa de utilización de CPU/GPU. Además de estas métricas básicas, utilizamos datos capturados para verificar la distribución de características a lo largo del tiempo, el sesgo del servicio de entrenamiento y la desviación de la predicción para garantizar una desviación mínima del concepto.
Pensamientos finales
En resumen, dividir libremente nuestra infraestructura de canalización en una capa informática, una capa de almacenamiento y una base de datos centralizada nos brinda tres beneficios clave en comparación con una arquitectura más estrechamente acoplada.
Tuberías más robustas en caso de fallas
Mayor flexibilidad para elegir qué herramientas implementar
Componentes escalables de forma independiente
¿Está interesado en utilizar el aprendizaje automático para salvaguardar el ecosistema criptográfico más grande del mundo y a sus usuarios? Consulte Binance Engineering/AI en nuestra página de carreras para conocer las ofertas de trabajo abiertas.