
Stability AI ha publicado un nuevo artículo en su blog sobre Stable Diffusion 2. En él, Stability AI propone un nuevo algoritmo que es más eficiente y robusto que el anterior y lo compara con otros métodos de última generación.

El modelo original Stable Diffusion V1 de CompVis revolucionó la naturaleza de los modelos de IA de código abierto y produjo cientos de modelos y avances diferentes en todo el mundo. Experimentó uno de los ascensos más rápidos hasta las 10.000 estrellas de Github, acumulando 33.000 en menos de dos meses, más rápido que la mayoría de programas en Github.
El lanzamiento original de Stable Diffusion V1 fue dirigido por el equipo dinámico de Robin Rombach (Stability AI) y Patrick Esser (Runway ML) del CompVis Group en LMU Munich, dirigido por el Prof. Dr. Björn Ommer. Se basaron en el trabajo anterior del laboratorio con modelos de difusión latente y recibieron apoyo crítico de LAION y Eleuther AI.

 ¿Qué diferencia a Stable Diffusion v1 de Stable Diffusion v2?
¿Qué diferencia a Stable Diffusion v1 de Stable Diffusion v2?
Stable Diffusion 2.0 incluye una serie de mejoras y características importantes con respecto a la versión anterior, así que echémosle un vistazo.
La versión Stable Diffusion 2.0 presenta modelos robustos de texto a imagen entrenados con un nuevo codificador de texto (OpenCLIP) desarrollado por LAION con la ayuda de Stability AI, que mejora significativamente la calidad de las imágenes generadas con respecto a las versiones V1 anteriores. Los modelos de texto a imagen de esta versión pueden generar imágenes con resoluciones predeterminadas de 512×512 píxeles y 768×768 píxeles.
Estos modelos se entrenan utilizando un subconjunto estético del conjunto de datos LAION-5B generado por el equipo DeepFloyd de Stability AI, que luego se filtra para excluir contenido para adultos utilizando el filtro NSFW de LAION.
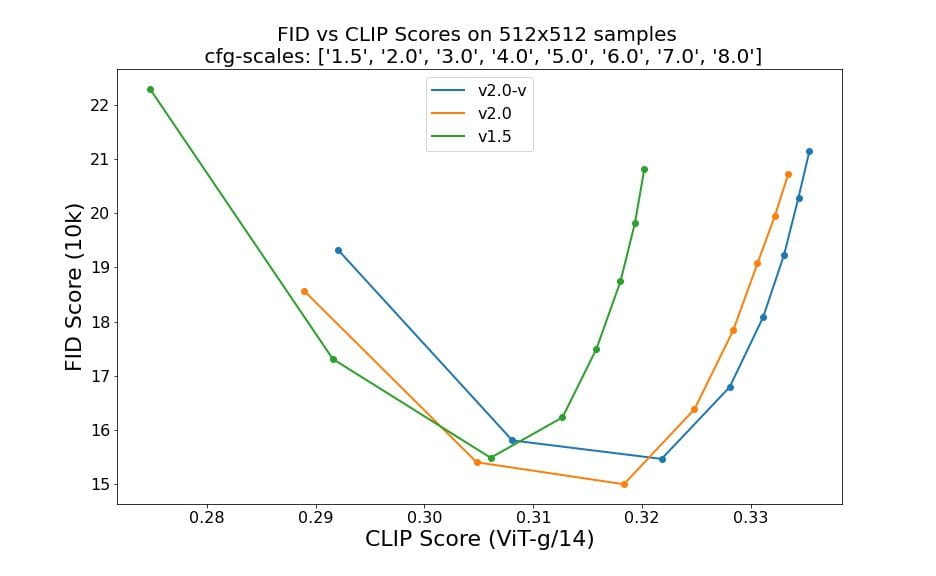
Las evaluaciones que utilizan 50 pasos de muestra de DDIM, 50 escalas guía sin clasificador y 1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0 y 8,0 indican mejoras relativas de los puntos de control:
Stable Diffusion 2.0 ahora incorpora un modelo Upscaler Diffusion, que aumenta la resolución de la imagen en un factor de cuatro. A continuación se muestra un ejemplo de nuestro modelo escalando una imagen generada de baja calidad (128 × 128) a una imagen de mayor resolución (512 × 512). Stable Diffusion 2.0, cuando se combina con nuestros modelos de texto a imagen, ahora puede generar imágenes con resoluciones de 2048×2048 o superiores.

El nuevo modelo de difusión estable guiado en profundidad, Depth2img, amplía la característica anterior de imagen a imagen de V1 con posibilidades creativas completamente nuevas. Depth2img determina la profundidad de una imagen de entrada (utilizando un modelo existente) y luego genera nuevas imágenes basadas tanto en el texto como en la información de profundidad. La profundidad de imagen puede proporcionar una gran cantidad de nuevas aplicaciones creativas, ofreciendo cambios que parecen significativamente diferentes del original y al mismo tiempo conservan la coherencia y profundidad de la imagen.
¿Qué hay de nuevo en Difusión Estable 2?
El nuevo modelo de difusión estable ofrece una resolución de 768×768.
U-Net tiene la misma cantidad de parámetros que la versión 1.5, pero está entrenado desde cero y utiliza OpenCLIP-ViT/H como codificador de texto. Un modelo de predicción v es el SD 2.0-v.
El modelo antes mencionado se ajustó a partir de la base SD 2.0, que también está disponible y se entrenó como un modelo típico de predicción de ruido en imágenes de 512×512.
Se ha agregado un modelo de difusión guiada por texto latente con escala x4.
Modelo de difusión estable guiado en profundidad con base SD 2.0 refinado. El modelo se puede utilizar para img2img que preserva la estructura y síntesis condicional de forma y está condicionado a estimaciones de profundidad monocular deducidas por MiDaS.
Un modelo de pintura mejorado guiado por texto construido sobre la base SD 2.0.
Los desarrolladores trabajaron duro, al igual que en la versión inicial de Stable Diffusion, para optimizar el modelo para que se ejecutara en una sola GPU; querían hacerlo accesible a la mayor cantidad de personas posible desde el principio. Ya han visto lo que sucede cuando millones de personas consiguen estos modelos y colaboran para construir cosas absolutamente extraordinarias. Éste es el poder del código abierto: aprovechar el vasto potencial de millones de personas talentosas que tal vez no tengan los recursos para entrenar un modelo de vanguardia, pero tienen la capacidad de hacer cosas increíbles con uno.

Esta nueva actualización, combinada con nuevas y potentes funciones como Depth2img y mejores capacidades de escalamiento de resolución, servirá como base para una gran cantidad de nuevas aplicaciones y permitirá una explosión de nuevo potencial creativo.
Lea más sobre la difusión estable:
La IA de difusión estable crea mundos de ensueño para la realidad virtual y el metaverso
El artista utiliza Stable Diffusion para producir la primera película de animación completa con IA
Conozca la pintura de video: edición basada en texto con difusión estable y atlas neuronales
El algoritmo de difusión estable 2 de Stability AI finalmente es público: nuevo modelo de profundidad2img, escalador de superresolución, sin contenido para adultos apareció por primera vez en Metaverse Post.