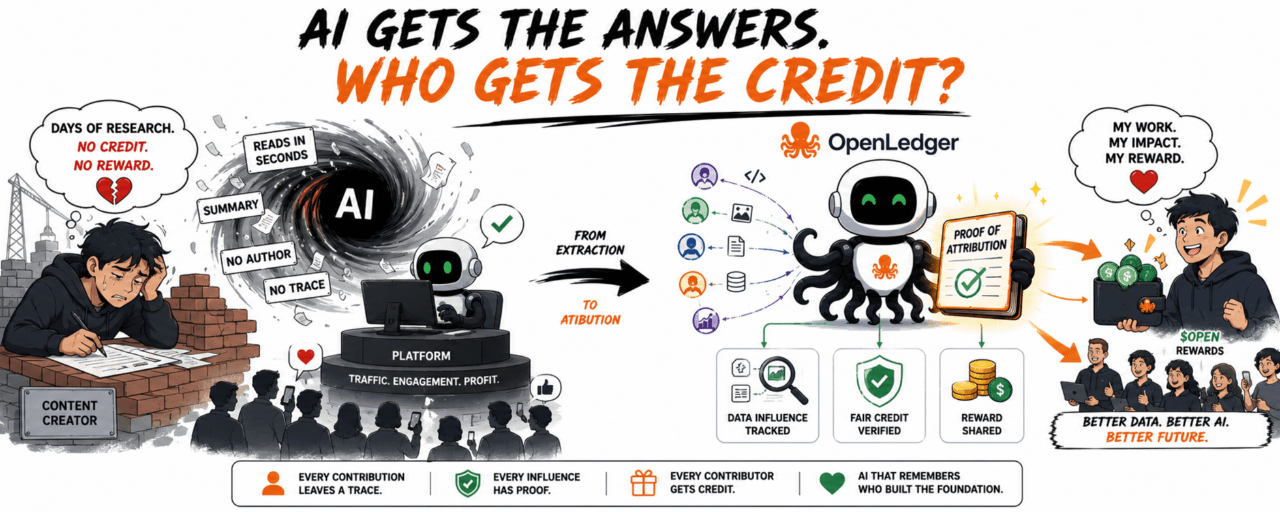
A mediados de 2024, empecé a ver a muchos creadores quejándose de algo bastante molesto: su trabajo de investigación de varios días, la IA lo lee en segundos y lo convierte en una respuesta concisa sin atribución al autor. Al lector le parece cómodo. La plataforma mantiene el tráfico. Pero el creador de contenido se siente como un albañil que construye toda una casa, y al final, el nombre en la escritura es de otra persona.
En ese momento, me di cuenta de que el problema de la IA no es solo "recoger datos para entrenar".
Está utilizando el trabajo de otros sin llevar un libro de cuentas decente.
Y honestamente, al principio, al ver @OpenLedger también tuve mis dudas. Ahora en crypto, cualquier proyecto que le pongan 'IA' suena como un lugar de fideos que cambia su letrero a 'AI Kitchen' y busca financiación. Pero al leer más a fondo, veo que OpenLedger no solo está contando la historia de una nueva cadena de IA.
Está tocando una pregunta muy real:
Si los datos ayudan a la IA a hacer dinero, ¿quién se lleva el crédito?

Ethereum registra quién envía dinero a quién. Bittensor se inclina más hacia la computación y la inteligencia de redes. En cambio, OpenLedger se adentra en la parte menos glamorosa: qué datos han influido en la salida de la IA, y si las personas que aportaron esos datos son reconocidas.
Hablando en términos más claros, la IA actual es como un equipo que hace videos, pero el crédito al final solo menciona cada plataforma. El guion fue escrito por otros, las imágenes fueron grabadas por otros, la música fue elegida por otros, el feedback de los usuarios se aporta poco a poco. Al final, el producto se lanza y la persona detrás desaparece como si nunca hubiera existido.
OpenLedger quiere recuperar ese crédito mediante la Prueba de Atribución.
Por ejemplo, un grupo que se especializa en detectar estafas on-chain en el sudeste asiático tiene solo un pequeño conjunto de datos: wallets fraudulentas, contratos falsos de airdrop, muestras de phishing, y algunos trucos de KOLs basura que suelen usar para atraer al retail. Normalmente, este tipo de datos es muy fácil de copiar, usar para entrenar y luego perder la pista. Pero si un agente de seguridad utiliza esos mismos datos para alertar a los usuarios antes de firmar una transacción, la contribución puede ser reconocida y recompensada a través de $OPEN.
Suena pequeño, pero para el retail, una alerta en el momento adecuado puede salvar toda una wallet.
El tema es que el sistema no solo necesita saber 'quién sube los datos'. Lo complicado es saber si esos datos realmente ayudan al modelo a responder mejor. Si solo subir datos cuenta como mérito, este juego se romperá muy rápido.
Donde hay recompensas, hay agricultores.
Donde hay atribución, hay personas haciéndose pasar por contribuyentes.
Los datos basura se vestirán con 'conocimiento del dominio'.
Los hilos copiados harán cosplay de investigación.
El spam será empaquetado como un conjunto de datos limpio.
Otra debilidad es el puntaje de influencia. Si este puntaje no es lo suficientemente transparente, será muy difícil para el contribuyente confiar en el sistema. Los que aportan buenos datos pero reciben pocas recompensas se preguntarán por qué. Si los datos basura obtienen una puntuación alta, no hay que preguntar, porque ya están beneficiándose.
Un pequeño conjunto de datos limpio puede valer más que un millón de líneas de contenido reciclado.
Y aquí está el ángulo que veo más interesante: la IA en el futuro podría no ganar solo porque responde mejor, sino porque demuestra de dónde aprendió.
El modelo que pueda distinguir entre datos reales y ruido es el que tiene posibilidades de sobrevivir a largo plazo.
Ese es el problema que OpenLedger está tratando de resolver.
