

Evaluación comparativa de circuitos utilizando SHA-256

Nos gustaría agradecer a los equipos de Polygon Zero, el proyecto gnark en Consensys, Pado Labs y Delphinus Lab por su valiosa revisión y comentarios en este blog.
El Panteón de la Prueba de Conocimiento Cero
Durante los últimos meses, hemos dedicado una cantidad significativa de tiempo y esfuerzo al desarrollo de una infraestructura de vanguardia que aproveche las pruebas sucintas de zk-SNARK. Como parte de nuestros esfuerzos de desarrollo, hemos probado y utilizado una amplia variedad de marcos de desarrollo a prueba de conocimiento cero (ZKP). Si bien este viaje ha sido gratificante, nos damos cuenta de que la abundancia de marcos ZKP disponibles a menudo crea un desafío para los nuevos desarrolladores que intentan encontrar el que mejor se adapte a sus casos de uso específicos y requisitos de rendimiento. Con este punto crítico en mente, creemos que se necesita una plataforma de evaluación comunitaria que pueda proporcionar resultados de referencia completos y que ayudará en gran medida en el desarrollo de estas nuevas aplicaciones.
Para satisfacer esta necesidad, estamos lanzando el Panteón de la Prueba de Conocimiento Cero como una iniciativa comunitaria de bien público. El primer paso será alentar a la comunidad a compartir resultados de evaluación comparativa reproducibles de varios marcos ZKP. Nuestro objetivo final es crear y mantener de manera colectiva y colaborativa un banco de pruebas de evaluación reconocido universalmente que cubra marcos de desarrollo de circuitos de bajo nivel, zkVM y compiladores de alto nivel e incluso proveedores de aceleración de hardware. Esperamos que esta iniciativa acelere la adopción de ZKP al facilitar la toma de decisiones informada, al mismo tiempo que alienta la evolución y la iteración de los propios marcos ZKP al proporcionar un conjunto de resultados de evaluación comparativa de referencia común. ¡Estamos comprometidos a invertir en esta iniciativa e invitamos a todos los miembros de la comunidad con ideas afines a unirse a nosotros y contribuir a este esfuerzo juntos!
Un primer paso: evaluación comparativa de los circuitos utilizando SHA-256
En esta publicación del blog, damos el primer paso hacia la creación del Panteón de ZKP al proporcionar un conjunto reproducible de resultados de evaluación comparativa utilizando SHA-256 en una variedad de marcos de desarrollo de circuitos de bajo nivel. Si bien reconocemos que son posibles otras granularidades y primitivas de evaluación comparativa, seleccionamos SHA-256 debido a su aplicabilidad a una amplia gama de casos de uso de ZKP, incluidos sistemas de cadena de bloques, firmas digitales, zkDID y más. También vale la pena mencionar que también aprovechamos SHA-256 en nuestro propio sistema, por lo que también es bastante conveniente para nosotros. 😂
Nuestro punto de referencia evalúa el rendimiento de SHA-256 en varios marcos de desarrollo de circuitos zk-SNARK y zk-STARK. A través de esta comparación, buscamos brindarles a los desarrolladores información sobre la eficiencia y la practicidad de cada marco. Nuestro objetivo es que estos hallazgos permitan a los desarrolladores tomar decisiones informadas al seleccionar el marco más adecuado para sus proyectos.
Sistemas de prueba
En los últimos años, hemos observado una proliferación de sistemas de prueba de conocimiento cero. Si bien es difícil mantenerse al día con todos los avances emocionantes en el espacio, hemos seleccionado cuidadosamente los siguientes sistemas de prueba en función de su madurez y adopción por parte de los desarrolladores. Nuestro objetivo es presentar una muestra representativa de diferentes combinaciones de frontend/backend.
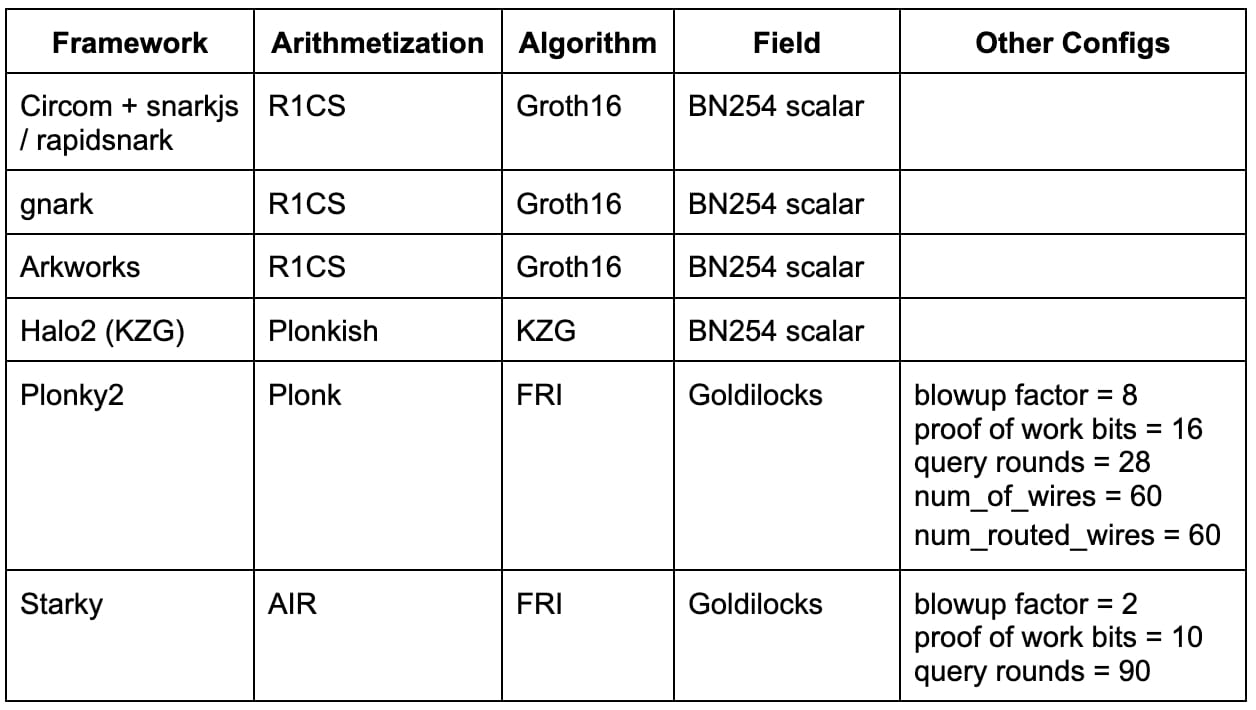
Circom + snarkjs / rapidsnark: Circom es un DSL popular para escribir circuitos y generar restricciones R1CS, mientras que snarkjs puede generar pruebas Groth16 o Plonk para Circom. Rapidsnark también es un probador para Circom que genera pruebas Groth16 y, por lo general, es mucho más rápido que snarkjs debido al uso de la extensión ADX, que paraleliza la generación de pruebas tanto como sea posible.
gnark: gnark es un marco Golang integral de Consensys que admite Groth16, Plonk y muchas más funciones avanzadas.
Arkworks: Arkworks es un marco Rust integral para zk-SNARK.
Halo2 (KZG): Halo2 es la implementación zk-SNARK de Zcash con Plonk. Está equipada con la aritmetización Plonkish altamente flexible que admite muchas primitivas útiles, como puertas personalizadas y tablas de búsqueda. Usamos una bifurcación de Halo2 con soporte para KZG de la Fundación Ethereum y Scroll.
Plonky2: Plonky2 es una implementación de SNARK basada en técnicas de PLONK y FRI de Polygon Zero. Plonky2 utiliza un campo Goldilocks pequeño y admite una recursión eficiente. En nuestra evaluación comparativa, nos centramos en una seguridad conjeturada de 100 bits y utilizamos los parámetros que arrojaron el mejor tiempo de prueba para el trabajo de evaluación comparativa. Específicamente, utilizamos 28 consultas Merkle, un factor de expansión de 8 y un desafío de prueba de trabajo de 16 bits. Además, establecimos num_of_wires = 60 y num_routed_wires = 60.
Starky: Starky es un marco STARK de alto rendimiento de Polygon Zero. En nuestra evaluación comparativa, nos centramos en una seguridad conjeturada de 100 bits y utilizamos los parámetros que arrojaron el mejor tiempo de prueba. Específicamente, utilizamos 90 consultas Merkle, un factor de expansión de 2 y un desafío de prueba de trabajo de 10 bits.
La siguiente tabla resume los marcos mencionados anteriormente con las configuraciones pertinentes utilizadas en nuestra evaluación comparativa. Esta lista no es exhaustiva y muchos marcos y técnicas de última generación (por ejemplo, Nova, GKR, Hyperplonk) quedan para trabajos futuros.
Tenga en cuenta que estos resultados de evaluación comparativa son solo para marcos de desarrollo de circuitos. En el futuro, tenemos previsto publicar un blog independiente en el que se evalúen comparativamente diferentes zkVM (por ejemplo, Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) y marcos de compilación IR (por ejemplo, Noir, zkLLVM).
Metodología de referencia
Para evaluar estos diversos sistemas de prueba, calculamos el hash SHA-256 para N bytes de datos, donde experimentamos con N = 64, 128, ..., 64K (con una excepción: Starky, donde el circuito repite el cálculo SHA-256 para una entrada fija de 64 bytes, pero mantiene el mismo número total de fragmentos de mensajes). El código de evaluación comparativa y las implementaciones del circuito SHA-256 se pueden encontrar en este repositorio.
Además, realizamos la evaluación comparativa de cada sistema utilizando las siguientes métricas de rendimiento:
Tiempo de generación de la prueba (incluido el tiempo de generación del testigo)
Uso máximo de memoria durante la generación de pruebas
Porcentaje de utilización promedio de CPU durante la generación de pruebas. (Esta métrica refleja el grado de paralelización durante la generación de pruebas)
Tenga en cuenta que estamos haciendo algunas suposiciones "ambiguas" con respecto al tamaño de la prueba y el costo de verificación de la prueba, ya que estos aspectos se pueden mitigar componiendo con Groth16/KZG antes de entrar en la cadena.
Las máquinas
Realizamos nuestra evaluación comparativa en dos máquinas diferentes:
Servidor Linux: 20 núcleos a 2,3 GHz, 384 GB de memoria
MacBook M1 Pro: 10 núcleos a 3,2 GHz, 16 GB de memoria
El servidor Linux se utilizó para simular el escenario con muchos núcleos de CPU y abundante memoria, mientras que el MacBook M1 Pro, que se utiliza habitualmente para I+D, tiene una CPU más potente con menos núcleos.
Hemos habilitado el multiprocesamiento cuando era opcional, pero no hemos utilizado la aceleración de GPU en esta evaluación comparativa. Tenemos previsto incluir la evaluación comparativa de GPU como parte de nuestro trabajo futuro.
Resultados de referencia
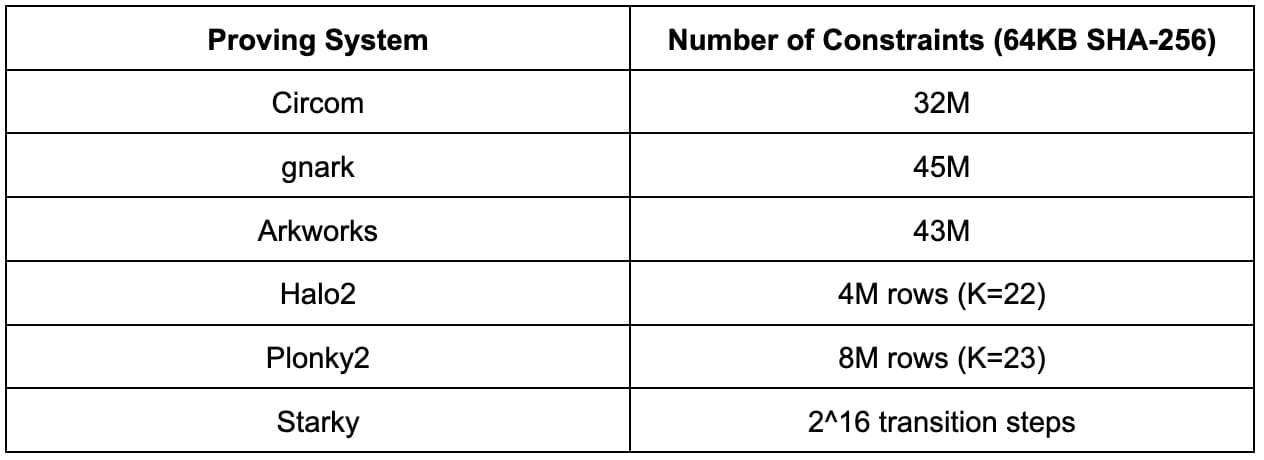
Número de restricciones
Antes de pasar a los resultados detallados de la evaluación comparativa, es útil comprender primero la complejidad del SHA-256 observando la cantidad de restricciones en cada sistema de prueba. Es importante tener en cuenta que las cantidades de restricciones en diferentes esquemas de aritmetización no son directamente comparables.
Los resultados que se muestran a continuación corresponden a un tamaño de imagen previa de 64 KB. Si bien los resultados pueden variar con otros tamaños de imagen previa, se pueden escalar de manera lineal.
Circom, gnark y Arkworks utilizan la misma aritmetización R1CS, y la cantidad de restricciones R1CS para calcular SHA-256 de 64 KB es de aproximadamente 30 M a 45 M. La diferencia entre Circom, gnark y Arkworks probablemente se deba a diferencias de implementación.
Tanto Halo2 como Plonky2 utilizan aritmética Plonkish, donde el número de filas varía de 2^22 a 2^23. La implementación de SHA-256 de Halo2 es mucho más eficiente que la de Plonky2 debido al uso de tablas de búsqueda.
Starky utiliza aritmetización AIR donde las tablas de seguimiento de ejecución requieren 2^16 pasos de transición.
Tiempo de generación de pruebas
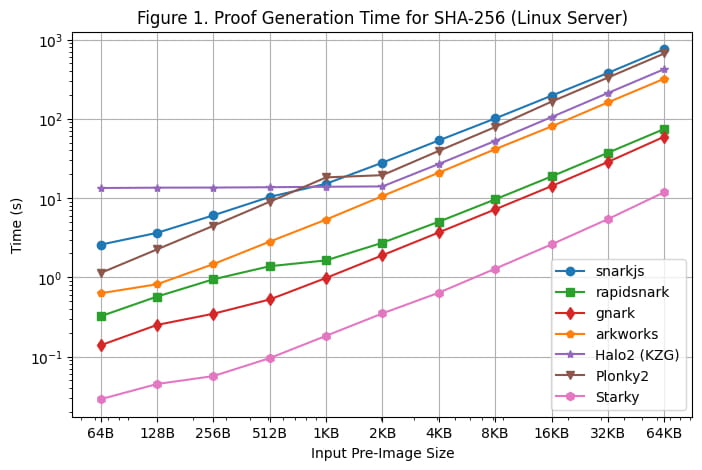
La [Figura 1] ilustra el tiempo de generación de pruebas de cada marco para SHA-256 en los distintos tamaños de preimagen, utilizando el servidor Linux. Podemos hacer las siguientes observaciones:
Para SHA-256, los marcos Groth16 (rapidsnark, gnark y Arkworks) generan pruebas más rápido que los marcos Plonk (Halo2 y Plonky2). Esto se debe a que SHA-256 consiste principalmente en operaciones bit a bit donde los valores de los cables son 0 o 1. Para Groth16, esto reduce la mayoría de los cálculos, desde la multiplicación escalar de curvas elípticas hasta la suma de puntos de curvas elípticas. Sin embargo, los valores de los cables no se utilizan directamente en los cálculos de Plonk, por lo que la estructura especial de los cables en SHA-256 no reduce la cantidad de cálculos necesarios en los marcos Plonk.
Entre todos los frameworks de Groth16, Gnark y Rapidsnark son entre 5 y 10 veces más rápidos que Arkworks y snarkjs. Esto se debe a su capacidad superior de utilizar múltiples núcleos para paralelizar la generación de pruebas. Gnark es un 25 % más rápido que Rapidsnark.
En el caso de los marcos Plonk, Plonky2 es un 50 % más lento que Halo2 para SHA-256 cuando se utiliza un tamaño de preimagen mayor de >= 4 KB. Esto se debe a que la implementación de Halo2 utiliza en gran medida una tabla de búsqueda para acelerar las operaciones bit a bit, lo que da como resultado el doble de filas que Plonky2. Sin embargo, si comparamos Plonky2 y Halo2 con la misma cantidad de filas (por ejemplo, SHA-256 sobre 2 KB en Halo2 frente a SHA-256 sobre 4 KB en Plonky2), Plonky2 es un 50 % más rápido que Halo2. Si implementamos SHA-256 con una tabla de búsqueda en Plonky2, deberíamos esperar que Plonky2 sea más rápido que Halo2, aunque el tamaño de prueba de Plonky2 sea mayor.
Por otro lado, cuando el tamaño de la preimagen de entrada es pequeño (<=512 bytes), Halo2 es más lento que Plonky2 (y otros frameworks) debido al costo fijo de configuración de la tabla de búsqueda que representa la mayoría de las restricciones. Sin embargo, a medida que aumenta la preimagen, el rendimiento de Halo2 se vuelve más competitivo, con un tiempo de generación de prueba que permanece constante para tamaños de preimagen de hasta 2 KB y luego escala casi linealmente, como se puede observar en el gráfico.
Como era de esperar, el tiempo de generación de pruebas de Starky es significativamente más corto (5x-50x) que el de cualquier marco SNARK, pero esto tiene el costo de un tamaño de prueba mucho mayor.
Una nota adicional es que incluso si el tamaño del circuito es lineal en el tamaño de la preimagen, la generación de prueba crece de manera superlineal para SNARK debido a la FFT O(nlogn) (aunque esto no es obvio en el gráfico debido a la escala logarítmica).
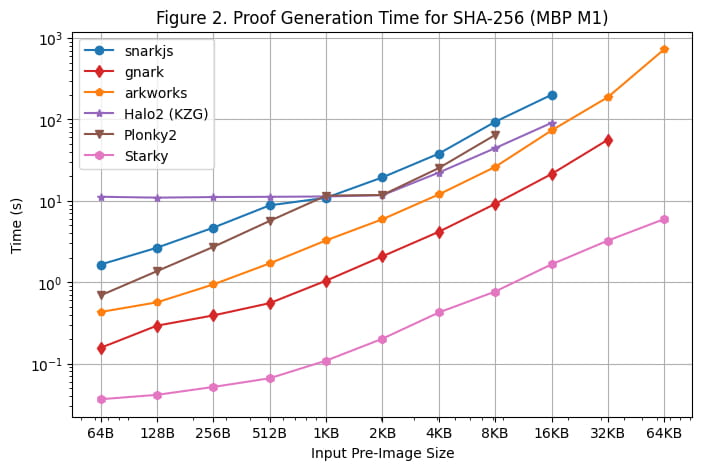
También realizamos una prueba comparativa de tiempo de generación en la MacBook M1 Pro, como se ilustra en la [Figura 2]. Sin embargo, es importante señalar que rapidsnark no se incluyó en esta prueba comparativa debido a su falta de compatibilidad con la arquitectura arm64. Para poder usar snarkjs en arm64, tuvimos que generar el testigo mediante webassembly, que es más lento que la generación de testigos en C++ que se utiliza en el servidor Linux.
Hubo varias observaciones adicionales al ejecutar el benchmark en Macbook M1 Pro:
A excepción de Starky, todos los frameworks SNARK encontraron errores de falta de memoria (OOM) o usaron memoria de intercambio (lo que resultó en un tiempo de prueba más lento) cuando el tamaño de la imagen previa se volvió grande. Específicamente, los frameworks Groth16 (snarkjs, gnark, Arkworks) comenzaron a usar memoria de intercambio cuando el tamaño de la imagen previa era mayor o igual a 8 KB, y gnark encontró OOM para 64 KB. Halo2 encontró un límite de memoria cuando el tamaño de la imagen previa era mayor o igual a 32 KB. Plonky2 comienza a usar memoria de intercambio cuando el tamaño de la imagen previa era mayor o igual a 8 KB.
Los frameworks basados en FRI (Starky y Plonky2) fueron aproximadamente un 60% más rápidos en el Macbook M1 Pro que en el servidor Linux, mientras que otros frameworks tuvieron tiempos de prueba similares en comparación con los del servidor Linux. Como resultado, Plonky2 logró casi el mismo tiempo de prueba que Halo2 en el Macbook M1 Pro, a pesar de que la tabla de búsqueda no se utilizó en Plonky2. La razón principal de esto es que el Macbook M1 Pro tiene una CPU más potente pero con menos núcleos. FRI realiza principalmente operaciones hash, que son más sensibles a los ciclos de reloj de la CPU pero no tan paralelizables como KZG/Groth16.
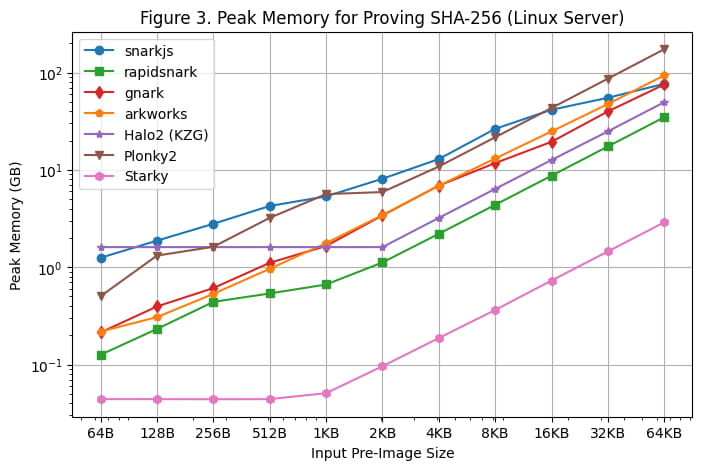
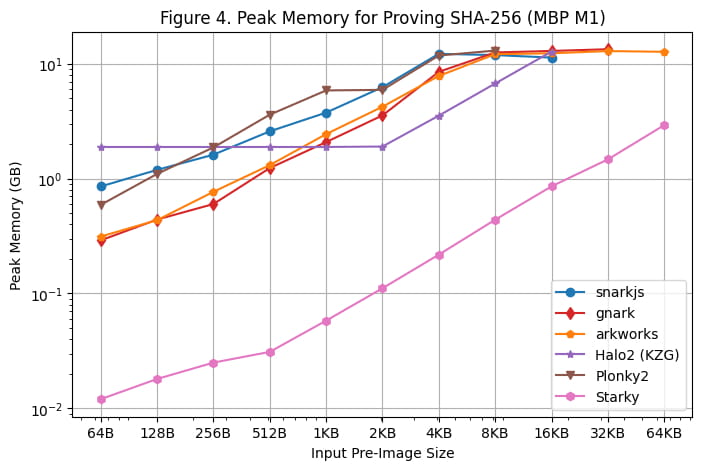
Uso máximo de memoria
El uso máximo de memoria durante la generación de pruebas en el servidor Linux y en la MacBook M1 Pro se muestra en la [Figura 3] y la [Figura 4], respectivamente. Se pueden hacer las siguientes observaciones en función de estos resultados de evaluación comparativa:
Entre todos los marcos SNARK, rapidsnark es el que hace un uso más eficiente de la memoria. También vemos que Halo2 utiliza más memoria cuando el tamaño de la imagen previa es menor debido al costo fijo de configuración de la tabla de búsqueda, pero consume menos memoria en general cuando el tamaño de la imagen previa es mayor.
Starky es diez veces más eficiente en el uso de la memoria que los frameworks SNARK. Esto se debe en parte a que utiliza menos filas.
Cabe señalar que el uso máximo de memoria se mantiene relativamente estable en la MacBook M1 Pro, ya que el tamaño de la imagen previa aumenta debido al uso de la memoria de intercambio.
Utilización de CPU
Evaluamos el grado de paralelización para cada sistema de prueba midiendo la utilización promedio de la CPU durante la generación de prueba para SHA-256 sobre una entrada de preimagen de 4 KB. La siguiente tabla muestra la utilización promedio de la CPU (y la utilización promedio por núcleo entre paréntesis) tanto en el servidor Linux (con 20 núcleos) como en la MacBook M1 Pro (con 10 núcleos).
Las observaciones clave son las siguientes:
Gnark y rapidsnark muestran el mayor uso de CPU en el servidor Linux, lo que indica su capacidad para utilizar de manera eficiente varios núcleos y paralelizar la generación de pruebas. Halo2 también demuestra un buen rendimiento de paralelización.
La mayoría de los marcos demuestran una utilización de CPU 2x en el servidor Linux en comparación con el MacBook Pro M1, la excepción a esto es snarkjs.
A pesar de las expectativas iniciales de que los frameworks basados en FRI (Plonky2 y Starky) podrían tener dificultades para utilizar varios núcleos de manera eficaz, no tienen peor rendimiento que algunos frameworks Groth16/KZG en nuestras pruebas comparativas. Queda por ver si habrá alguna diferencia en la utilización de la CPU en una máquina con incluso más núcleos (por ejemplo, 100 núcleos).

Conclusión y trabajo futuro
Esta publicación del blog presenta una comparación completa del rendimiento de SHA-256 en varios marcos de desarrollo zk-SNARK y zk-STARK. A través de los resultados de la evaluación comparativa, obtuvimos información sobre la eficiencia y la practicidad de cada marco para los desarrolladores que requieren pruebas concisas para operaciones SHA-256. Se descubrió que los marcos Groth16 (por ejemplo, rapidsnark, gnark) son más rápidos en la generación de pruebas que los marcos Plonk (por ejemplo, Halo2, Plonky2). La tabla de búsqueda en la aritmetización Plonkish reduce significativamente las restricciones y el tiempo de prueba para SHA-256 cuando se usa un tamaño de preimagen más grande. Además, gnark y rapidsnark demuestran una excelente capacidad para utilizar múltiples núcleos para la paralelización. Starky, por otro lado, muestra un tiempo de generación de prueba mucho más corto, pero a costa de un tamaño de prueba mucho mayor. En términos de eficiencia de memoria, rapidsnark y Starky superan a otros marcos.
Como primeros pasos para construir el Panteón de ZKP, reconocemos que este resultado de referencia está lejos de ser el banco de pruebas integral final que aspiramos a que sea algún día. Agradecemos y estamos abiertos a los comentarios y críticas e invitamos a todos a contribuir a esta iniciativa de hacer que ZKP sea más fácil y accesible para los desarrolladores. También estamos dispuestos a proporcionar subvenciones a los contribuyentes individuales para cubrir los costos de los recursos computacionales para la evaluación comparativa a gran escala. Juntos, podemos mejorar la eficiencia y la practicidad de ZKP para el beneficio de la comunidad en general.